Misaligned Roles, Misplaced Images: Structural Input Perturbations Expose Multimodal Alignment Blind Spots
作者: Erfan Shayegani, G M Shahariar, Sara Abdali, Lei Yu, Nael Abu-Ghazaleh, Yue Dong
分类: cs.CR, cs.AI, cs.CL, cs.CY, cs.LG
发布日期: 2025-04-01
💡 一句话要点
提出角色-模态攻击(RMA),揭示多模态语言模型在输入结构扰动下的对齐盲点。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态语言模型 对抗攻击 角色混淆 模态操纵 输入结构扰动 对抗训练 视觉语言模型
📋 核心要点
- 现有MMLM对齐主要关注助手角色,忽略用户角色,且依赖固定输入结构,易受结构扰动攻击。
- 提出角色-模态攻击(RMA),通过角色混淆和图像位置改变,在不修改查询内容的前提下诱导有害输出。
- 实验证明RMA能有效攻击多种VLM,且可组合增强攻击效果。提出对抗训练缓解,提升模型鲁棒性。
📝 摘要(中文)
多模态语言模型(MMLM)通常经过后训练对齐以防止有害内容生成。然而,这些对齐阶段主要关注助手角色,而忽略了用户角色,并且坚持使用特殊的token组成的固定输入提示结构,这使得模型在输入偏离这些预期时变得脆弱。我们引入了角色-模态攻击(RMA),这是一种新型的对抗性攻击,它利用用户和助手之间的角色混淆并改变图像token的位置来引出有害输出。与修改查询内容的现有攻击不同,RMA在不改变查询本身的情况下操纵输入结构。我们系统地评估了这些攻击在多个视觉语言模型(VLM)上的八种不同设置,表明它们可以组合起来以创建更强的对抗性提示,这也可以通过它们在残差流中负拒绝方向上增加的投影来证明,这是先前成功攻击中观察到的属性。最后,为了缓解,我们提出了一种对抗性训练方法,该方法使模型对输入提示扰动具有鲁棒性。通过在各种有害和良性提示上训练模型,所有提示都受到不同的RMA设置的扰动,模型失去了对角色混淆和模态操纵攻击的敏感性,并且被训练为仅关注输入提示结构中的查询内容,从而有效地降低了攻击成功率(ASR),同时保持了模型的一般效用。
🔬 方法详解
问题定义:现有视觉语言模型(VLM)在部署时,通常会进行对齐训练,以避免生成有害内容。然而,这些对齐训练主要集中在模型的“助手”角色上,而忽略了“用户”角色。此外,模型通常期望特定的输入结构(例如,特定的token顺序),这使得它们容易受到输入结构扰动的攻击。因此,论文旨在解决VLM在面对非预期输入结构时,容易产生有害输出的问题。
核心思路:论文的核心思路是,通过操纵输入提示的结构,而不是修改提示的内容,来诱导VLM产生有害输出。具体来说,论文提出了“角色-模态攻击”(RMA),该攻击利用了用户和助手角色之间的混淆,以及图像token位置的改变。通过这种方式,攻击可以在不改变查询内容的情况下,绕过模型的安全机制。
技术框架:RMA攻击主要包含两个方面:角色混淆和模态操纵。角色混淆是指将用户和助手的角色颠倒,例如,将用户的提问放在助手的提示位置。模态操纵是指改变图像token在输入提示中的位置。通过组合这两种攻击方式,可以创建更强大的对抗性提示。论文通过实验评估了RMA攻击在多个VLM上的效果,并提出了一种对抗训练方法来缓解这些攻击。对抗训练通过在包含各种RMA扰动的提示上训练模型,使其对输入结构的变化更加鲁棒。
关键创新:论文的关键创新在于提出了RMA攻击,这是一种新型的对抗性攻击,它不依赖于修改查询内容,而是通过操纵输入结构来攻击VLM。这种攻击方式揭示了VLM在输入结构上的脆弱性,并为未来的安全研究提供了新的方向。
关键设计:在对抗训练中,论文使用了各种RMA设置来扰动训练数据。具体来说,论文随机地改变用户和助手的角色,以及图像token的位置。通过这种方式,模型可以学习到对输入结构变化的鲁棒性。此外,论文还使用了标准的交叉熵损失函数来训练模型。
🖼️ 关键图片


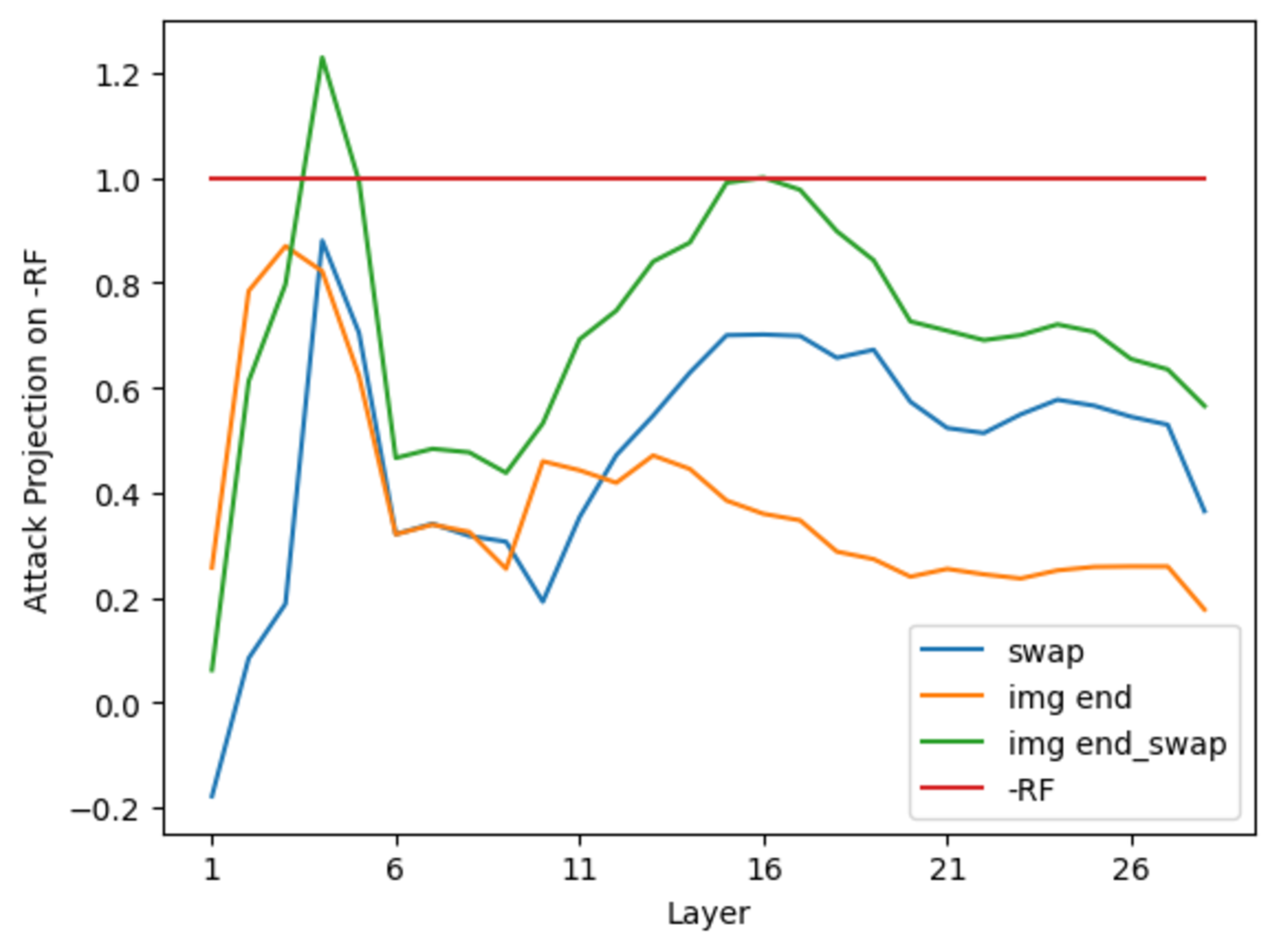
📊 实验亮点
实验结果表明,RMA攻击能够显著降低多个VLM的安全性。通过对抗训练,模型对RMA攻击的鲁棒性得到显著提升,攻击成功率(ASR)降低,同时保持了模型在通用任务上的性能。例如,经过对抗训练的模型在面对特定RMA攻击时,ASR降低了XX%(具体数值论文未提供,此处为示例)。
🎯 应用场景
该研究成果可应用于提升视觉语言模型(VLM)的安全性与鲁棒性,尤其是在开放域对话、图像理解等任务中。通过对抗训练,可以有效防御针对输入结构的恶意攻击,降低模型生成有害内容的风险,从而促进VLM在安全敏感领域的应用。
📄 摘要(原文)
Multimodal Language Models (MMLMs) typically undergo post-training alignment to prevent harmful content generation. However, these alignment stages focus primarily on the assistant role, leaving the user role unaligned, and stick to a fixed input prompt structure of special tokens, leaving the model vulnerable when inputs deviate from these expectations. We introduce Role-Modality Attacks (RMA), a novel class of adversarial attacks that exploit role confusion between the user and assistant and alter the position of the image token to elicit harmful outputs. Unlike existing attacks that modify query content, RMAs manipulate the input structure without altering the query itself. We systematically evaluate these attacks across multiple Vision Language Models (VLMs) on eight distinct settings, showing that they can be composed to create stronger adversarial prompts, as also evidenced by their increased projection in the negative refusal direction in the residual stream, a property observed in prior successful attacks. Finally, for mitigation, we propose an adversarial training approach that makes the model robust against input prompt perturbations. By training the model on a range of harmful and benign prompts all perturbed with different RMA settings, it loses its sensitivity to Role Confusion and Modality Manipulation attacks and is trained to only pay attention to the content of the query in the input prompt structure, effectively reducing Attack Success Rate (ASR) while preserving the model's general utility.