Large Language Models in Numberland: A Quick Test of Their Numerical Reasoning Abilities
作者: Roussel Rahman
分类: cs.AI
发布日期: 2025-03-31
💡 一句话要点
提出Numberland基准测试,评估大语言模型在数值推理上的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 数值推理 基准测试 数感 数学能力
📋 核心要点
- 现有方法主要关注LLM在高层次数学问题上的推理能力,忽略了对其基础数感的评估,导致对其数值推理能力的理解不足。
- 论文提出了Numberland基准测试,包含基本运算、高级计算、素数检查和24点游戏等任务,旨在全面评估LLM的数值推理能力。
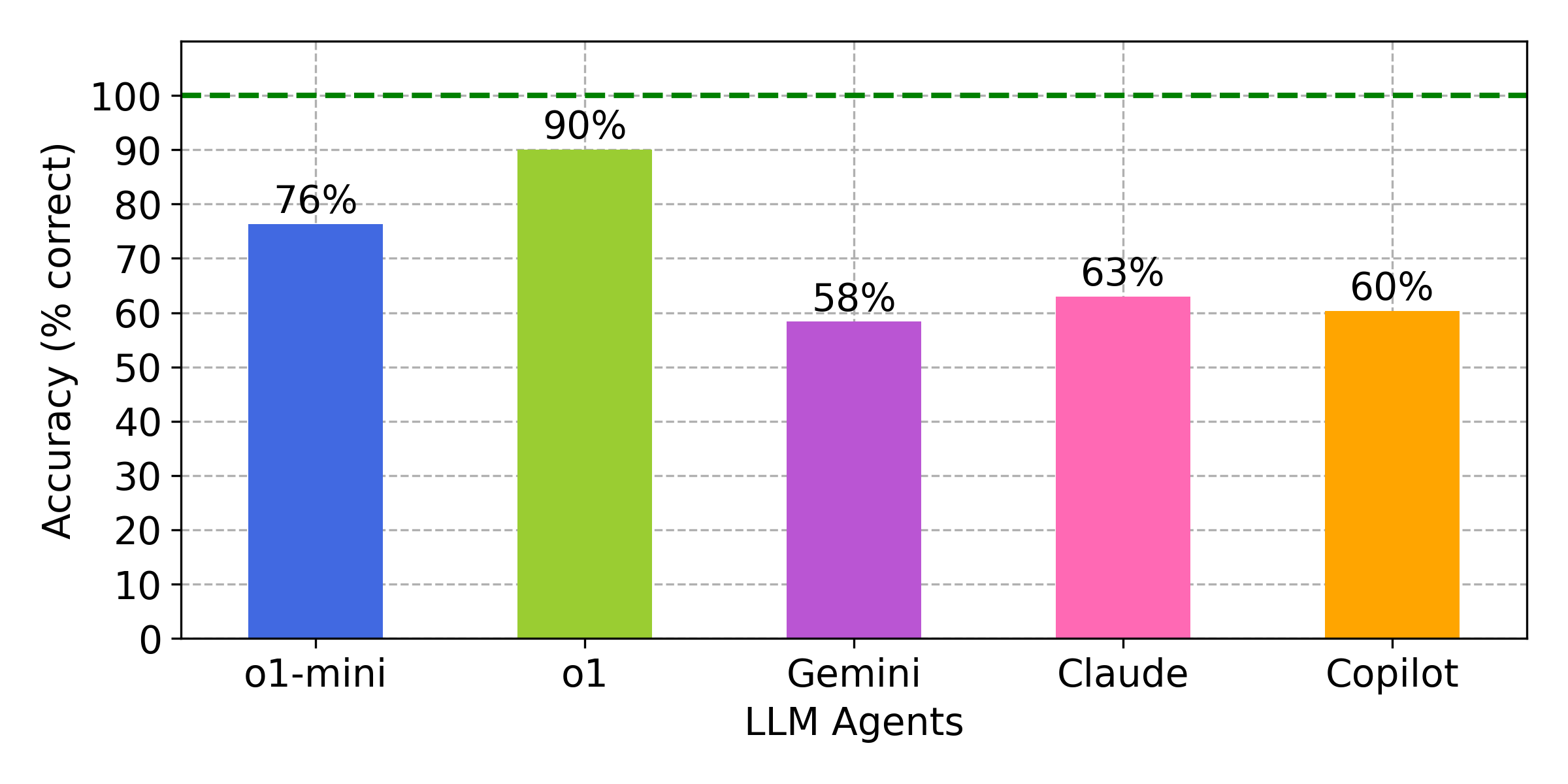
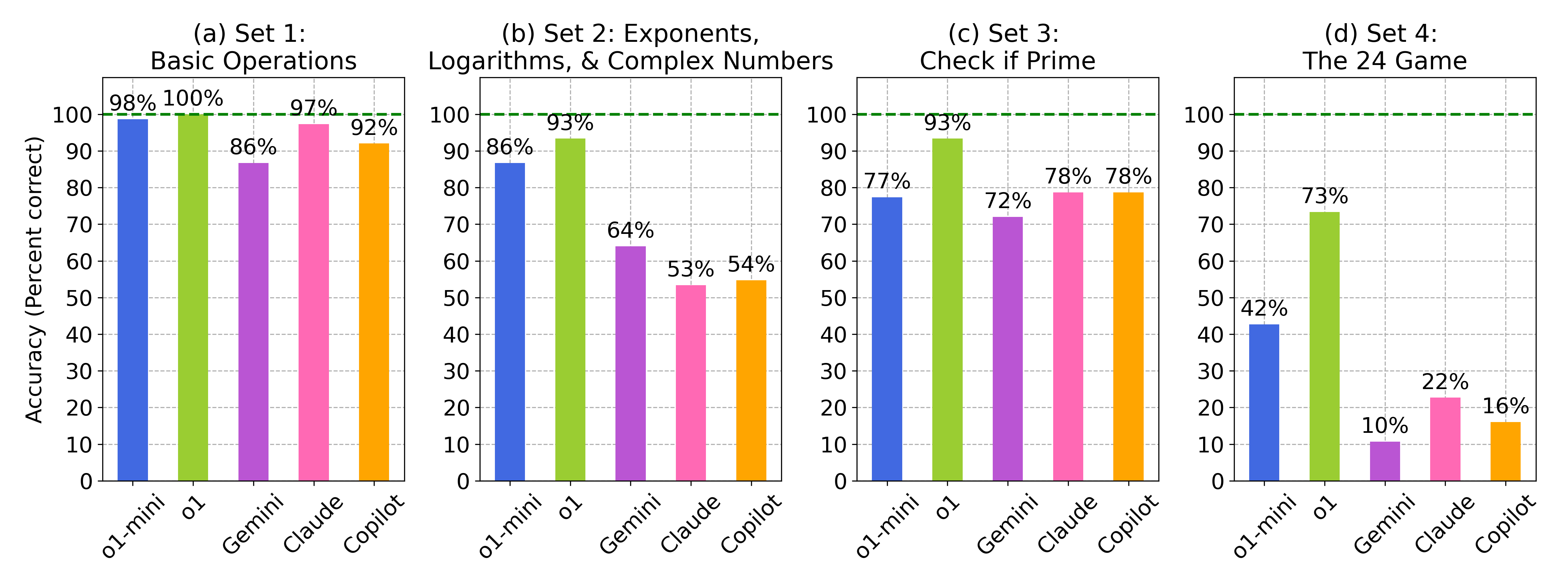
- 实验结果表明,LLM在确定性任务上表现良好,但在需要搜索的任务(如24点游戏)中性能显著下降,揭示了LLM数值推理的脆弱性。
📝 摘要(中文)
人类数学推理的一个重要组成部分是我们的数感——对数字及其关系的抽象理解——这使得我们能够使用有限的计算资源来解决涉及广阔数字空间的问题。大语言模型(LLM)的数学推理能力通常在高层次问题(如奥林匹克挑战、几何、文字问题和谜题)上进行测试,但其低层次的数感仍然较少被探索。我们引入了“Numberland”,这是一个包含100个问题的测试,旨在评估基于LLM的智能体的数值推理能力。这些任务——基本运算、高级计算(例如,求幂、复数)、素数检查和24点游戏——旨在测试基本技能及其在解决复杂和不确定问题中的整合。我们评估了五个基于LLM的智能体:OpenAI的o1和o1-mini、Google Gemini、Microsoft Copilot和Anthropic Claude。它们在前三个允许确定性步骤求解的任务中得分74-95%。在需要反复试验搜索的24点游戏中,性能下降到10-73%。我们测试了最好的24点求解器(o1,准确率为73%)在25个更难的问题上,其得分下降到27%,证实了搜索是一个瓶颈。这些结果,以及错误的类型,表明LLM的数字能力是脆弱的,考虑到它们在具有挑战性的基准测试中的能力,这有点令人惊讶。LLM数值推理的局限性突出了简单、有针对性的测试在评估和解释LLM数学技能以确保安全使用方面的范围。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLM)的数值推理能力评估问题。现有方法主要集中于高层次的数学问题,忽略了对LLM基础数感的考察。这导致我们对LLM在处理基本数值运算、复杂计算以及需要搜索的问题时的能力缺乏清晰的认识。现有评估方法难以准确反映LLM在实际应用中可能遇到的数值推理挑战。
核心思路:论文的核心思路是设计一个专门用于评估LLM数值推理能力的基准测试,即Numberland。该基准测试包含一系列精心设计的任务,涵盖了从基本运算到复杂计算的不同难度级别,旨在全面考察LLM在数值推理方面的能力。通过分析LLM在这些任务上的表现,可以更深入地了解其数值推理的优势和局限性。
技术框架:Numberland基准测试包含100个问题,分为四个主要任务:基本运算、高级计算(如指数运算、复数运算)、素数检查和24点游戏。每个任务都旨在测试LLM在不同方面的数值推理能力。实验中,作者选择了五个主流的LLM进行评估:OpenAI的o1和o1-mini、Google Gemini、Microsoft Copilot和Anthropic Claude。通过比较这些LLM在Numberland上的表现,可以评估它们在数值推理方面的相对优劣。
关键创新:该论文的关键创新在于提出了Numberland基准测试,这是一个专门用于评估LLM数值推理能力的综合性测试集。与以往主要关注高层次数学问题的评估方法不同,Numberland更加注重考察LLM的基础数感和在不同难度级别任务上的表现。此外,论文还深入分析了LLM在不同任务上的错误类型,为进一步改进LLM的数值推理能力提供了有价值的 insights。
关键设计:Numberland基准测试的任务设计考虑了不同难度级别和不同类型的数值推理挑战。例如,24点游戏需要LLM进行搜索和尝试,考察其在不确定性环境下的推理能力。实验中,作者没有对LLM进行额外的微调,而是直接使用其预训练模型进行评估,以反映其真实的数值推理能力。对于24点游戏,作者还测试了性能最佳的LLM在更难问题上的表现,以进一步验证其搜索能力的瓶颈。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LLM在确定性数值计算任务中表现良好(74-95%),但在需要搜索的24点游戏中性能显著下降(10-73%)。对最佳24点求解器(o1)在更难问题上的测试显示,其准确率从73%降至27%,证实了搜索能力是LLM数值推理的瓶颈。这些结果揭示了LLM在数值推理方面的脆弱性,并强调了针对性测试的重要性。
🎯 应用场景
该研究成果可应用于评估和改进大语言模型在金融分析、科学计算、工程设计等领域的应用。通过Numberland基准测试,可以更好地了解LLM的数值推理能力,从而确保其在关键任务中的安全可靠性。未来的研究可以基于此基准测试,开发更有效的数值推理增强方法。
📄 摘要(原文)
An essential element of human mathematical reasoning is our number sense -- an abstract understanding of numbers and their relationships -- which allows us to solve problems involving vast number spaces using limited computational resources. Mathematical reasoning of Large Language Models (LLMs) is often tested on high-level problems (such as Olympiad challenges, geometry, word problems, and puzzles), but their low-level number sense remains less explored. We introduce "Numberland," a 100-problem test to evaluate the numerical reasoning abilities of LLM-based agents. The tasks -- basic operations, advanced calculations (e.g., exponentiation, complex numbers), prime number checks, and the 24 game -- aim to test elementary skills and their integration in solving complex and uncertain problems. We evaluated five LLM-based agents: OpenAI's o1 and o1-mini, Google Gemini, Microsoft Copilot, and Anthropic Claude. They scored 74-95% on the first three tasks that allow deterministic steps to solutions. In the 24 game, which needs trial-and-error search, performance dropped to 10-73%. We tested the top 24 solver (o1 with 73% accuracy) on 25 harder problems, and its score fell to 27%, confirming search as a bottleneck. These results, along with the types of mistakes, suggest a fragile number of LLMs, which is a bit surprising given their prowess in challenging benchmarks. The limits of LLM numerical reasoning highlight the scope of simple, targeted tests to evaluate and explain LLM math skills to ensure safe use.