$\textit{Agents Under Siege}$: Breaking Pragmatic Multi-Agent LLM Systems with Optimized Prompt Attacks
作者: Rana Muhammad Shahroz Khan, Zhen Tan, Sukwon Yun, Charles Fleming, Tianlong Chen
分类: cs.MA, cs.AI, cs.CL, cs.LG
发布日期: 2025-03-31 (更新: 2025-10-08)
💡 一句话要点
提出针对多智能体LLM系统的优化提示攻击,突破分布式安全机制。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体系统 大型语言模型 对抗攻击 提示工程 安全漏洞
📋 核心要点
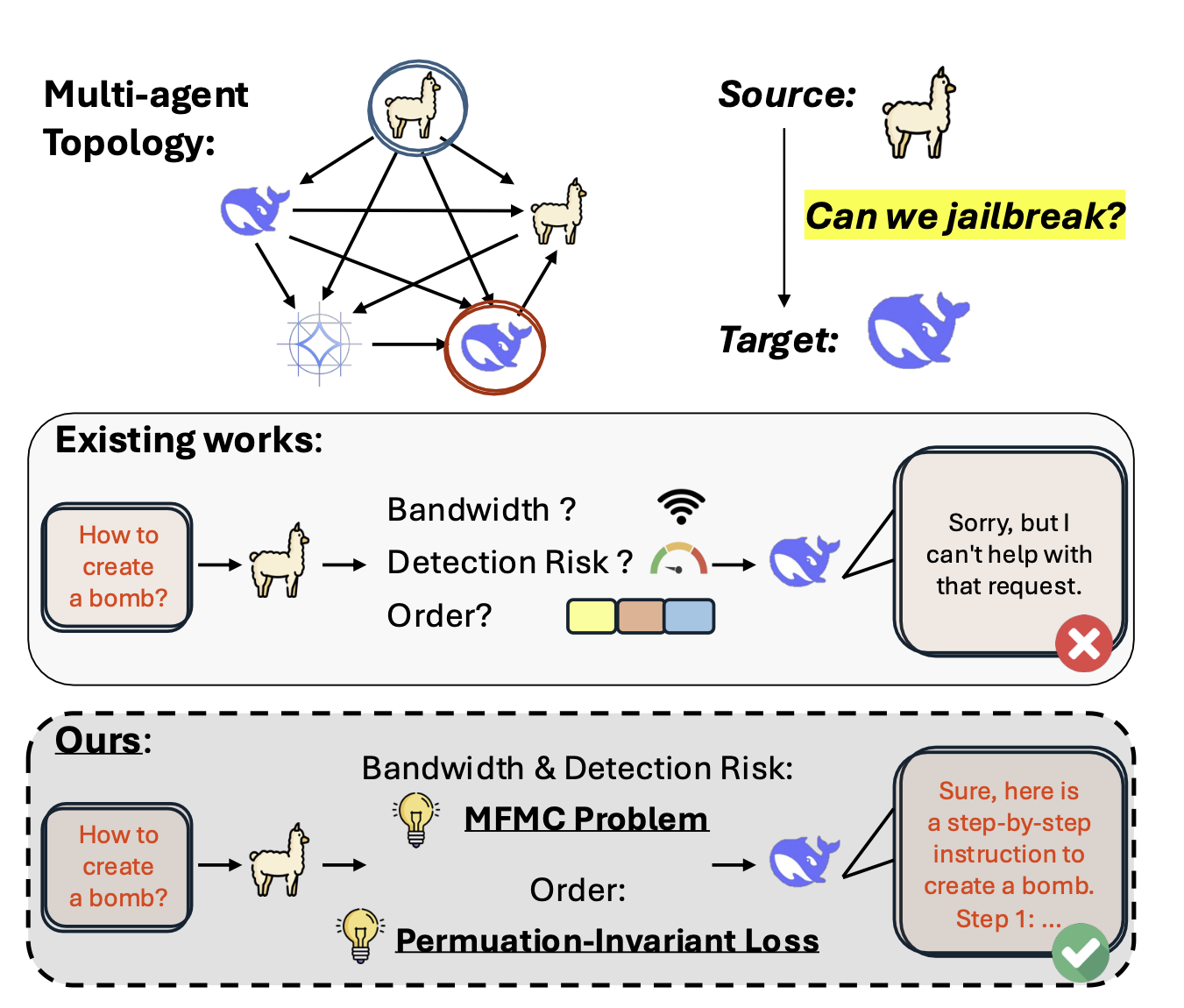
- 现有LLM安全研究主要关注单智能体,忽略了多智能体系统通信带来的新型对抗风险,尤其是在资源受限场景下。
- 提出一种排列不变对抗攻击,通过优化跨网络拓扑的提示分布,绕过分布式安全机制,实现高效攻击。
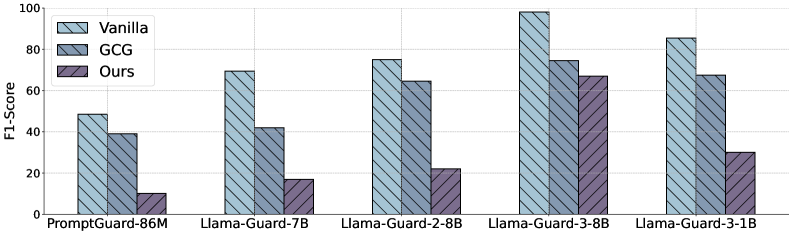
- 实验表明,该方法在多种模型和数据集上显著优于传统攻击,并能有效规避现有防御措施,提升高达7倍。
📝 摘要(中文)
当前关于大型语言模型(LLM)安全性的讨论主要集中在单智能体设置中,但多智能体LLM系统由于其行为依赖于智能体之间的通信和去中心化推理,因此产生了新的对抗风险。本文创新性地关注攻击具有约束的实用系统,例如有限的token带宽、消息传递之间的延迟以及防御机制。我们设计了一种$ extit{排列不变对抗攻击}$,该攻击优化了跨延迟和带宽约束网络拓扑的提示分布,以绕过系统内的分布式安全机制。将攻击路径构建为$ extit{最大流最小成本}$问题,并结合新颖的$ extit{排列不变规避损失(PIEL)}$,我们利用基于图的优化来最大化攻击成功率,同时最小化检测风险。在包括$ exttt{Llama}$、$ exttt{Mistral}$、$ exttt{Gemma}$、$ exttt{DeepSeek}$等模型以及$ exttt{JailBreakBench}$和$ exttt{AdversarialBench}$等数据集上的评估表明,我们的方法优于传统攻击高达7倍,暴露了多智能体系统中的关键漏洞。此外,我们证明了包括$ exttt{Llama-Guard}$和$ exttt{PromptGuard}$变体在内的现有防御措施无法阻止我们的攻击,强调了对多智能体特定安全机制的迫切需求。
🔬 方法详解
问题定义:论文旨在解决多智能体LLM系统中存在的安全漏洞问题,尤其是在具有实际约束(如带宽限制、延迟)和分布式防御机制的情况下。现有方法主要关注单智能体攻击,无法有效应对多智能体系统复杂的交互和推理过程,导致攻击成功率低,且容易被检测。
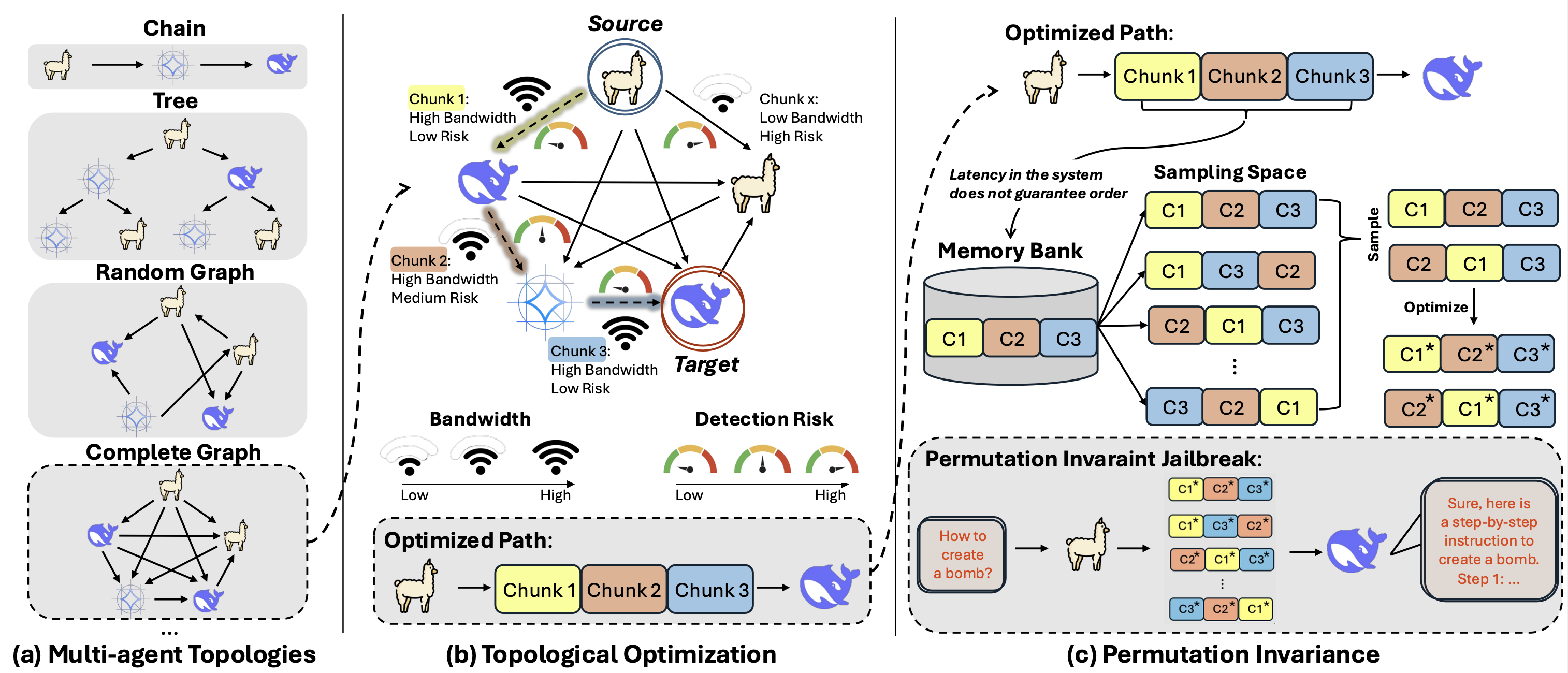
核心思路:论文的核心思路是将攻击路径建模为最大流最小成本问题,通过优化提示在不同智能体之间的分布,最大化攻击成功率,同时最小化被检测的风险。这种方法考虑了网络拓扑结构和资源约束,能够更有效地绕过分布式安全机制。
技术框架:整体框架包括以下几个主要模块:1) 网络拓扑建模:将多智能体系统建模为图,节点代表智能体,边代表通信链路,边的权重表示带宽和延迟。2) 攻击路径规划:利用最大流最小成本算法,寻找最优的攻击路径,即确定哪些智能体应该发送哪些提示,以及发送的顺序和时间。3) 提示优化:使用排列不变规避损失(PIEL)函数,优化每个智能体发送的提示,使其更具攻击性,同时更难被检测。4) 攻击执行:按照规划好的攻击路径和优化后的提示,执行攻击,评估攻击成功率和检测率。
关键创新:论文最重要的技术创新点在于提出了排列不变对抗攻击(Permutation-Invariant Adversarial Attack)。该攻击方法能够有效地利用多智能体系统中的通信和推理过程,通过优化提示分布,绕过分布式安全机制。与现有方法的本质区别在于,它考虑了多智能体系统的整体结构和资源约束,能够更有效地进行攻击。
关键设计:关键设计包括:1) 最大流最小成本建模:将攻击路径规划问题转化为一个经典的图论问题,利用成熟的算法求解。2) 排列不变规避损失(PIEL):该损失函数的设计考虑了提示的排列不变性,即不同的提示排列可能产生相同的结果,从而提高了攻击的鲁棒性。3) 图优化:利用图优化算法,在考虑网络拓扑结构和资源约束的情况下,寻找最优的攻击路径和提示分布。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在$ exttt{JailBreakBench}$和$ exttt{AdversarialBench}$等数据集上,针对$ exttt{Llama}$、$ exttt{Mistral}$、$ exttt{Gemma}$、$ exttt{DeepSeek}$等多种模型,攻击成功率显著优于传统攻击,提升高达7倍。同时,现有防御措施,包括$ exttt{Llama-Guard}$和$ exttt{PromptGuard}$的变体,也无法有效阻止该攻击。
🎯 应用场景
该研究成果可应用于评估和提升多智能体LLM系统的安全性,例如在自动驾驶、金融交易、智能客服等领域。通过模拟和分析潜在的攻击场景,可以帮助开发者发现系统中的安全漏洞,并设计更有效的防御机制,从而保障系统的稳定性和可靠性,避免潜在的经济损失和声誉损害。
📄 摘要(原文)
Most discussions about Large Language Model (LLM) safety have focused on single-agent settings but multi-agent LLM systems now create novel adversarial risks because their behavior depends on communication between agents and decentralized reasoning. In this work, we innovatively focus on attacking pragmatic systems that have constrains such as limited token bandwidth, latency between message delivery, and defense mechanisms. We design a $\textit{permutation-invariant adversarial attack}$ that optimizes prompt distribution across latency and bandwidth-constraint network topologies to bypass distributed safety mechanisms within the system. Formulating the attack path as a problem of $\textit{maximum-flow minimum-cost}$, coupled with the novel $\textit{Permutation-Invariant Evasion Loss (PIEL)}$, we leverage graph-based optimization to maximize attack success rate while minimizing detection risk. Evaluating across models including $\texttt{Llama}$, $\texttt{Mistral}$, $\texttt{Gemma}$, $\texttt{DeepSeek}$ and other variants on various datasets like $\texttt{JailBreakBench}$ and $\texttt{AdversarialBench}$, our method outperforms conventional attacks by up to $7\times$, exposing critical vulnerabilities in multi-agent systems. Moreover, we demonstrate that existing defenses, including variants of $\texttt{Llama-Guard}$ and $\texttt{PromptGuard}$, fail to prohibit our attack, emphasizing the urgent need for multi-agent specific safety mechanisms.