Rubric Is All You Need: Enhancing LLM-based Code Evaluation With Question-Specific Rubrics
作者: Aditya Pathak, Rachit Gandhi, Vaibhav Uttam, Arnav Ramamoorthy, Pratyush Ghosh, Aaryan Raj Jindal, Shreyash Verma, Aditya Mittal, Aashna Ased, Chirag Khatri, Yashwanth Nakka, Devansh, Jagat Sesh Challa, Dhruv Kumar
分类: cs.SE, cs.AI
发布日期: 2025-03-31 (更新: 2025-08-06)
备注: Accepted in ICER 2025
💡 一句话要点
提出基于问题特定评分标准的LLM代码评估方法,提升教育场景下的逻辑评估效果。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码评估 大型语言模型 问题特定评分标准 多代理系统 教育应用
📋 核心要点
- 现有基于LLM的代码评估方法通常采用问题无关的评分标准,难以准确评估代码的逻辑正确性。
- 论文提出使用问题特定的评分标准,针对每个问题定制评估细则,从而更准确地评估代码的逻辑。
- 通过在数据结构与算法以及面向对象编程数据集上的实验,证明了该方法能显著提升代码逻辑评估的准确性。
📝 摘要(中文)
随着GPT-3和ChatGPT等大型语言模型(LLMs)的普及,LLMs在编程相关任务中展现出卓越的潜力。虽然使用LLMs进行代码生成已成为热门的研究领域,但基于LLMs的代码评估仍未得到充分探索。本文侧重于基于LLM的代码评估,并试图填补现有的空白。我们提出了一种新颖的多代理方法,使用针对问题陈述量身定制的问题特定评分标准,认为这些方法在逻辑评估方面优于使用问题无关评分标准的现有方法。为了解决缺乏合适的评估数据集的问题,我们引入了两个数据集:一个包含来自流行的数据结构和算法练习网站的150个学生提交的数据结构和算法数据集,以及一个包含来自本科计算机科学课程的80个学生提交的面向对象编程数据集。除了使用标准指标(Spearman相关性,Cohen's Kappa)外,我们还提出了一种称为Leniency的新指标,该指标量化了相对于专家评估的评估严格程度。我们的综合分析表明,问题特定评分标准显著增强了教育环境中代码的逻辑评估,提供了与教学目标更一致的反馈,而不仅仅是句法正确性。
🔬 方法详解
问题定义:论文旨在解决现有基于LLM的代码评估方法在逻辑评估方面的不足。现有方法通常采用问题无关的评分标准,无法针对特定问题的逻辑要点进行有效评估,导致评估结果与专家评估存在偏差。
核心思路:论文的核心思路是使用问题特定的评分标准(Question-Specific Rubrics)。针对每个代码评估问题,设计一套详细的评分细则,明确指出需要评估的逻辑要点、边界条件和潜在错误。通过这种方式,LLM能够更准确地理解问题的要求,并对代码的逻辑进行更细致的评估。
技术框架:论文采用多代理(Multi-Agentic)架构。具体流程为:首先,根据问题描述生成问题特定的评分标准;然后,利用LLM作为评估代理,根据评分标准对代码进行评估;最后,将评估结果与专家评估进行比较,并使用Spearman相关性、Cohen's Kappa和Leniency等指标进行评估。
关键创新:最重要的技术创新点在于问题特定评分标准的设计和应用。与现有方法使用通用的、问题无关的评分标准不同,该方法能够针对每个问题定制评估细则,从而更准确地评估代码的逻辑正确性。此外,论文还提出了Leniency指标,用于量化评估的严格程度。
关键设计:论文的关键设计包括:1) 如何根据问题描述自动生成问题特定的评分标准(具体实现细节未知);2) 如何将评分标准有效地融入LLM的评估过程中(具体实现细节未知);3) Leniency指标的计算方法(具体公式未知)。
🖼️ 关键图片
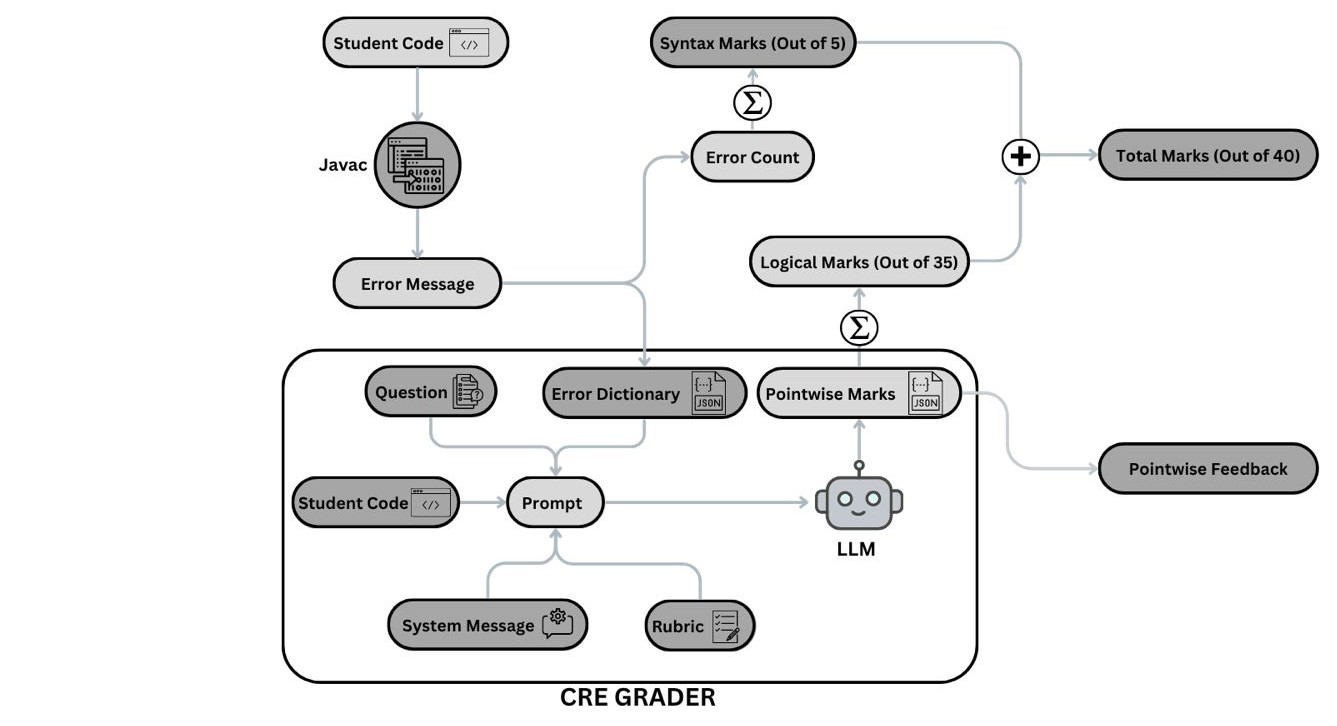
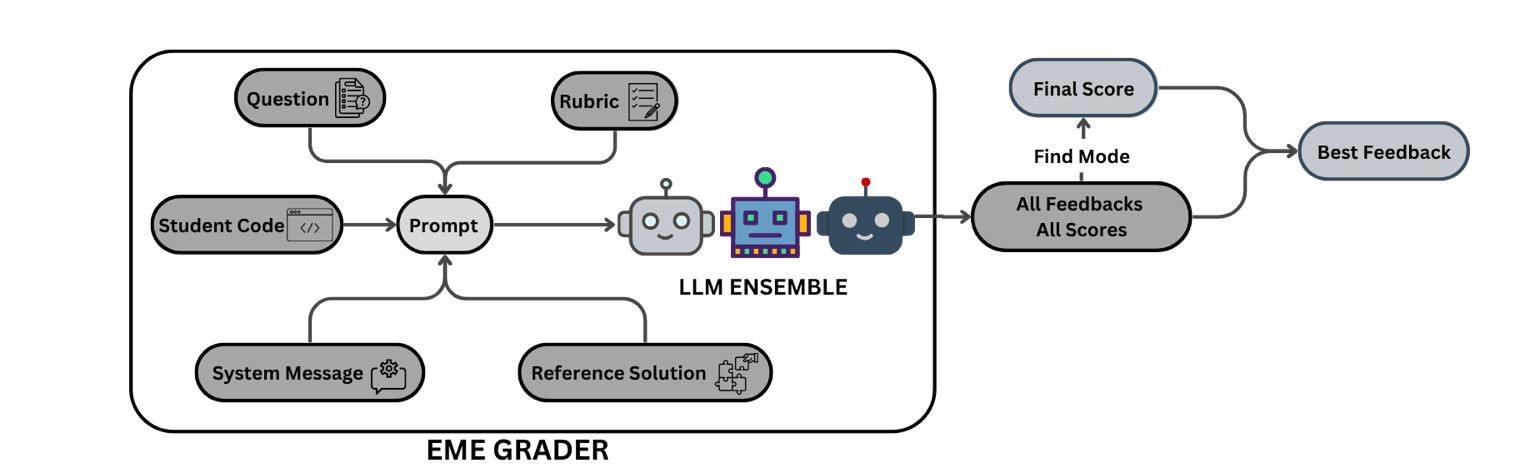
📊 实验亮点
实验结果表明,使用问题特定评分标准的LLM代码评估方法在数据结构与算法以及面向对象编程数据集上均取得了显著的提升。具体性能数据未知,但该方法在逻辑评估方面优于使用问题无关评分标准的现有方法,并且评估结果与专家评估更一致。
🎯 应用场景
该研究成果可应用于在线编程教育平台、代码评审工具和自动评分系统等领域。通过提供更准确、更细致的代码评估反馈,可以帮助学生更好地理解编程概念,提高编程能力。此外,该方法还可以用于自动化代码评审,提高软件开发的效率和质量。
📄 摘要(原文)
Since the emergence of Large Language Models (LLMs) popularized by the release of GPT-3 and ChatGPT, LLMs have shown remarkable promise in programming-related tasks. While code generation using LLMs has become a popular field of research, code evaluation using LLMs remains under-explored. In this paper, we focus on LLM-based code evaluation and attempt to fill in the existing gaps. We propose multi-agentic novel approaches using \emph{question-specific rubrics} tailored to the problem statement, arguing that these perform better for logical assessment than the existing approaches that use \emph{question-agnostic rubrics}. To address the lack of suitable evaluation datasets, we introduce two datasets: a Data Structures and Algorithms dataset containing 150 student submissions from a popular Data Structures and Algorithms practice website, and an Object Oriented Programming dataset comprising 80 student submissions from undergraduate computer science courses. In addition to using standard metrics (Spearman Correlation, Cohen's Kappa), we additionally propose a new metric called as Leniency, which quantifies evaluation strictness relative to expert assessment. Our comprehensive analysis demonstrates that \emph{question-specific rubrics} significantly enhance logical assessment of code in educational settings, providing better feedback aligned with instructional goals beyond mere syntactic correctness.