Text2Schema: Filling the Gap in Designing Database Table Structures based on Natural Language
作者: Qin Wang, Youhuan Li, Yansong Feng, Si Chen, Ziming Li, Pan Zhang, Zihui Si, Yixuan Chen, Zhichao Shi, Zebin Huang, Guo Chen, Wenqiang Jin
分类: cs.DB, cs.AI
发布日期: 2025-03-31 (更新: 2025-10-17)
备注: 19 pages, 16 figures
💡 一句话要点
提出SchemaAgent框架,解决从自然语言文本直接生成数据库表结构的问题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: Text2Schema 数据库模式生成 自然语言处理 多智能体系统 大型语言模型
📋 核心要点
- 现有方法依赖预先设计的数据库模式,而模式设计本身需要领域专业知识,直接从文本需求生成模式的研究尚待探索。
- SchemaAgent框架通过模拟人工模式设计流程,分配专门角色给智能体,并进行有效协作,从而优化子任务。
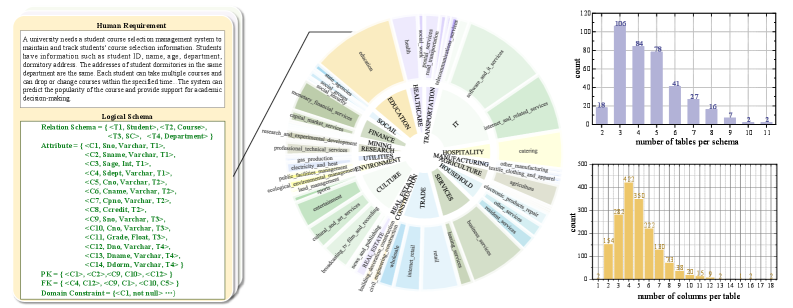
- 论文构建并开源了包含381对需求描述和模式的基准,实验结果验证了SchemaAgent方法优于现有方法。
📝 摘要(中文)
本文系统性地定义了一个新问题,称为Text2Schema,旨在将自然语言文本需求转换为关系数据库模式。该技术使得非技术人员能够轻松地使用自然语言创建数据库表结构,并利用现有的Text2SQL技术执行数据操作,从而显著缩小了非技术人员与高效、通用的关系数据库系统之间的差距。为此,我们提出了SchemaAgent,一个基于LLM的多智能体框架用于Text2Schema。我们通过为智能体分配专门的角色并实现有效的协作来模拟手动模式设计的工作流程,以改进各自的子任务。我们还加入了用于反思和检查的专用角色,以及创新的错误检测和纠正机制,以识别和纠正各个阶段的问题。此外,我们构建并开源了一个包含381对需求描述和模式的基准。实验结果表明,我们的方法优于对比工作。
🔬 方法详解
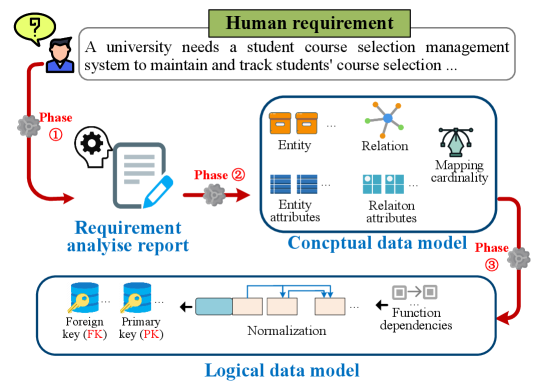
问题定义:本文旨在解决Text2Schema问题,即从自然语言文本描述直接生成关系数据库模式。现有Text2SQL方法都假设数据库模式已经存在,而实际应用中,模式设计需要专业的数据库知识和领域知识,这对于非技术人员来说是一个巨大的障碍。因此,如何让非技术人员也能方便地创建数据库表结构,是本文要解决的核心问题。
核心思路:本文的核心思路是模拟人工设计数据库模式的过程,将复杂的任务分解为多个子任务,并分配给不同的智能体(Agent)来完成。通过智能体之间的协作和反馈,逐步完善数据库模式的设计。这种多智能体协作的方式能够更好地利用大型语言模型(LLM)的能力,提高模式生成的质量。
技术框架:SchemaAgent框架包含多个智能体,每个智能体负责不同的子任务,例如实体识别、关系抽取、属性定义等。框架还包含反思(Reflection)和检查(Inspection)机制,用于检测和纠正智能体在各个阶段产生的错误。整体流程如下:1. 接收自然语言文本需求;2. 各个智能体并行工作,生成初步的数据库模式;3. 反思智能体对初步模式进行评估和改进;4. 检查智能体对模式进行验证和修正;5. 输出最终的数据库模式。
关键创新:本文的关键创新在于提出了基于多智能体协作的Text2Schema框架。与传统的单模型方法相比,SchemaAgent能够更好地利用LLM的知识和推理能力,提高模式生成的准确性和完整性。此外,框架中的反思和检查机制能够有效地检测和纠正错误,进一步提升模式的质量。
关键设计:SchemaAgent框架中,每个智能体的具体实现可以采用不同的LLM模型和技术。例如,实体识别智能体可以使用命名实体识别(NER)模型,关系抽取智能体可以使用关系抽取模型。反思智能体可以根据预定义的规则和知识库对模式进行评估,检查智能体可以使用数据库约束和验证规则对模式进行验证。具体的参数设置、损失函数和网络结构等技术细节取决于所选用的LLM模型和技术。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SchemaAgent框架在Text2Schema任务上取得了显著的性能提升。与现有的基线方法相比,SchemaAgent在模式生成的准确率、完整性和一致性等方面均有明显优势。具体而言,SchemaAgent在自建的基准数据集上,各项指标均优于对比方法,验证了其有效性。
🎯 应用场景
Text2Schema技术可应用于各种需要数据管理的场景,例如企业数据管理、个人数据管理、科研数据管理等。该技术可以帮助非技术人员快速构建数据库,提高数据管理的效率和质量。未来,Text2Schema技术可以与Text2SQL技术结合,实现从自然语言到数据库的全流程自动化。
📄 摘要(原文)
People without a database background usually rely on file systems or tools such as Excel for data management, which often lead to redundancy and data inconsistency. Relational databases possess strong data management capabilities, but require a high level of professional expertise from users. Although there are already many works on Text2SQL to automate the translation of natural language into SQL queries for data manipulation, all of them presuppose that the database schema is pre-designed. In practice, schema design itself demands domain expertise, and research on directly generating schemas from textual requirements remains unexplored. In this paper, we systematically define a new problem, called Text2Schema, to convert a natural language text requirement into a relational database schema. With an effective Text2Schema technique, users can effortlessly create database table structures using natural language, and subsequently leverage existing Text2SQL techniques to perform data manipulations, which significantly narrows the gap between non-technical personnel and highly efficient, versatile relational database systems. We propose SchemaAgent, an LLM-based multi-agent framework for Text2Schema. We emulate the workflow of manual schema design by assigning specialized roles to agents and enabling effective collaboration to refine their respective subtasks. We also incorporate dedicated roles for reflection and inspection, along with an innovative error detection and correction mechanism to identify and rectify issues across various phases. Moreover, we build and open source a benchmark containing 381 pairs of requirement description and schema. Experimental results demonstrate the superiority of our approach over comparative work.