POINT$^{2}$: A Polymer Informatics Training and Testing Database
作者: Jiaxin Xu, Gang Liu, Ruilan Guo, Meng Jiang, Tengfei Luo
分类: cond-mat.mtrl-sci, cs.AI, cs.LG
发布日期: 2025-03-30
💡 一句话要点
提出POINT$^{2}$:一个用于聚合物信息学训练和测试的综合数据库与基准协议。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 聚合物信息学 机器学习 数据库 基准测试 聚合物性能预测
📋 核心要点
- 现有聚合物信息学方法缺乏对预测精度、不确定性量化、模型可解释性和聚合物可合成性的综合考虑。
- POINT$^{2}$通过构建包含真实和虚拟聚合物的数据库,并结合多种机器学习模型和聚合物表征方法,提供了一个全面的基准测试平台。
- 该研究在气体渗透性、热导率等多种聚合物属性上进行了实验,验证了POINT$^{2}$在聚合物发现和优化方面的潜力。
📝 摘要(中文)
聚合物信息学的进步得益于机器学习(ML)技术的融合,能够快速预测聚合物性能并加速高性能聚合物材料的发现。然而,该领域缺乏一个包含预测精度、不确定性量化、ML可解释性和聚合物可合成性的标准化工作流程。本研究引入POINT$^{2}$ (POlymer INformatics Training and Testing),这是一个综合的基准数据库和协议,旨在应对这些关键挑战。利用现有的标记数据集和未标记的PI1M数据集(包含约一百万个通过循环神经网络生成的虚拟聚合物),我们开发了一系列ML模型,包括分位数随机森林、带dropout的多层感知器、图神经网络和预训练的大型语言模型。这些模型与多种聚合物表示(如Morgan、MACCS、RDKit、拓扑、原子对指纹和基于图的描述符)相结合,以实现气体渗透性、热导率、玻璃化转变温度、熔融温度、自由体积和密度等多种属性的预测、不确定性估计、模型可解释性和基于模板的聚合可合成性。POINT$^{2}$数据库可以作为聚合物信息学界进行聚合物发现和优化的宝贵资源。
🔬 方法详解
问题定义:该论文旨在解决聚合物信息学领域缺乏标准化工作流程的问题,现有方法在预测聚合物性能时,往往只关注预测精度,而忽略了不确定性量化、模型可解释性和聚合物的可合成性。此外,缺乏一个统一的、包含足够多数据(包括真实和虚拟聚合物)的基准数据集,阻碍了不同算法之间的公平比较和发展。
核心思路:论文的核心思路是构建一个名为POINT$^{2}$的综合数据库和基准协议,该数据库包含真实聚合物数据集和通过生成模型(RNN)生成的虚拟聚合物数据集。同时,结合多种机器学习模型(如分位数随机森林、多层感知器、图神经网络和预训练语言模型)和聚合物表征方法(如Morgan指纹、图描述符等),以实现对聚合物性能的全面评估,包括预测精度、不确定性估计、模型可解释性和可合成性。
技术框架:POINT$^{2}$的技术框架主要包括以下几个模块:1) 数据集构建:收集现有的标记聚合物数据集,并使用RNN生成大量的虚拟聚合物数据(PI1M数据集)。2) 特征工程:使用多种方法对聚合物进行表征,包括基于指纹的描述符(Morgan, MACCS, RDKit, Topological, Atom Pair fingerprints)和基于图的描述符。3) 模型训练:训练多种机器学习模型,包括分位数随机森林、带dropout的多层感知器、图神经网络和预训练的大型语言模型。4) 性能评估:在POINT$^{2}$数据库上评估不同模型的性能,包括预测精度、不确定性估计、模型可解释性和可合成性。
关键创新:该论文的关键创新在于:1) 构建了一个包含真实和虚拟聚合物的综合数据库POINT$^{2}$,为聚合物信息学研究提供了一个统一的基准测试平台。2) 提出了一个综合的评估框架,不仅关注预测精度,还考虑了不确定性量化、模型可解释性和聚合物的可合成性。3) 结合了多种机器学习模型和聚合物表征方法,为聚合物性能预测提供了更全面的解决方案。
关键设计:论文中关于模型和参数的具体设计细节未知。但可以推测,对于RNN生成模型,其网络结构和训练方式(例如损失函数、优化器等)会影响生成虚拟聚合物的质量。对于不同的机器学习模型,其参数设置(例如随机森林的树的数量、神经网络的层数和dropout率等)会影响模型的预测性能。此外,如何有效地结合不同的聚合物表征方法也是一个关键的设计问题。
🖼️ 关键图片

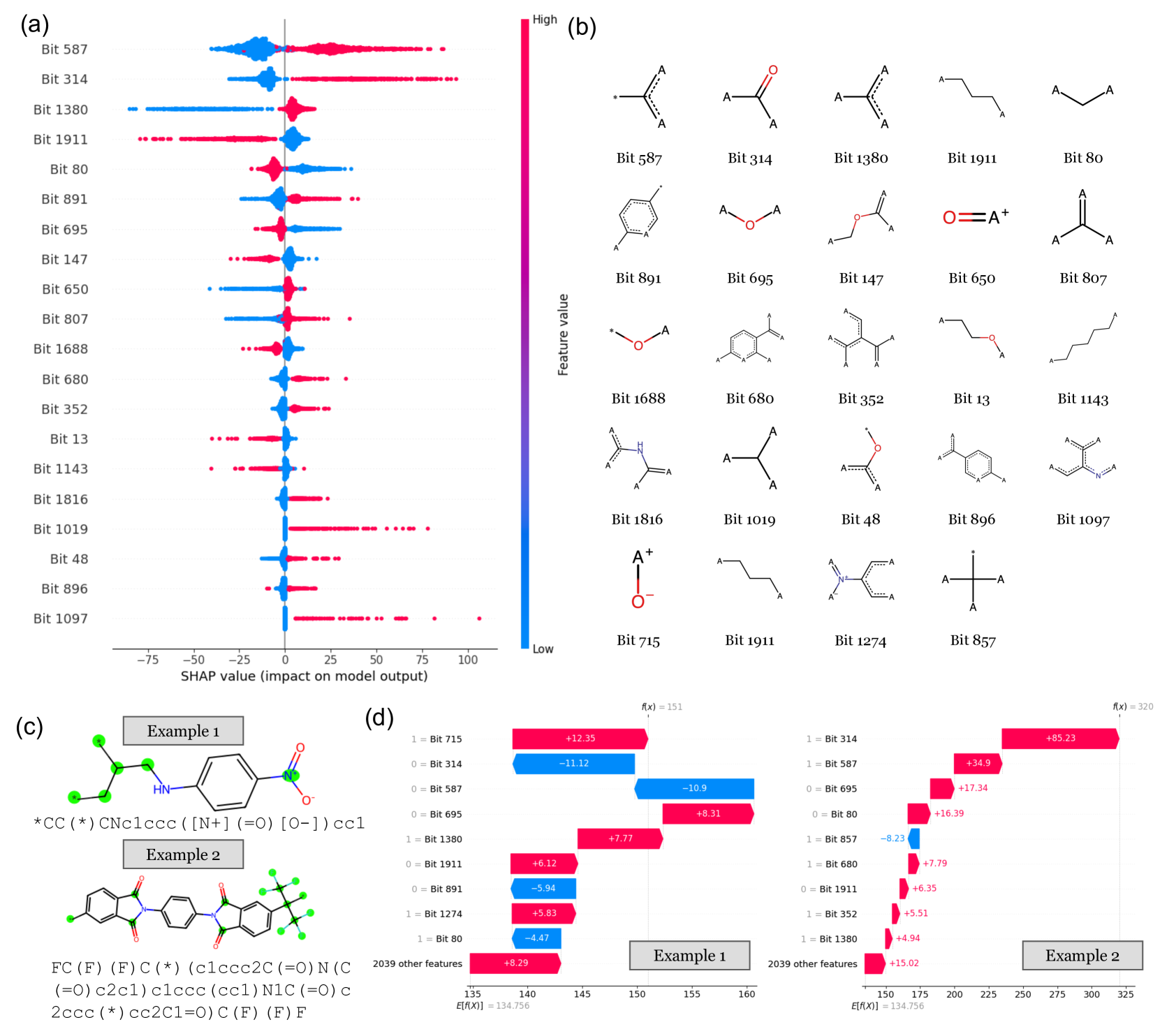

📊 实验亮点
由于论文摘要中没有提供具体的实验数据,因此无法总结实验亮点。但可以推测,该研究通过实验验证了POINT$^{2}$数据库和基准协议的有效性,并比较了不同机器学习模型和聚合物表征方法在预测聚合物性能方面的表现。未来的研究可以关注在特定聚合物属性预测上的性能数据、对比基线以及提升幅度。
🎯 应用场景
POINT$^{2}$数据库和基准协议可广泛应用于聚合物材料的发现和优化。研究人员可以利用该平台快速预测聚合物的各种性能,筛选出具有特定性能的候选材料,并指导实验合成。此外,该平台还可以用于评估和比较不同的机器学习模型和聚合物表征方法,促进聚合物信息学领域的发展。
📄 摘要(原文)
The advancement of polymer informatics has been significantly propelled by the integration of machine learning (ML) techniques, enabling the rapid prediction of polymer properties and expediting the discovery of high-performance polymeric materials. However, the field lacks a standardized workflow that encompasses prediction accuracy, uncertainty quantification, ML interpretability, and polymer synthesizability. In this study, we introduce POINT$^{2}$ (POlymer INformatics Training and Testing), a comprehensive benchmark database and protocol designed to address these critical challenges. Leveraging the existing labeled datasets and the unlabeled PI1M dataset, a collection of approximately one million virtual polymers generated via a recurrent neural network trained on the realistic polymers, we develop an ensemble of ML models, including Quantile Random Forests, Multilayer Perceptrons with dropout, Graph Neural Networks, and pretrained large language models. These models are coupled with diverse polymer representations such as Morgan, MACCS, RDKit, Topological, Atom Pair fingerprints, and graph-based descriptors to achieve property predictions, uncertainty estimations, model interpretability, and template-based polymerization synthesizability across a spectrum of properties, including gas permeability, thermal conductivity, glass transition temperature, melting temperature, fractional free volume, and density. The POINT$^{2}$ database can serve as a valuable resource for the polymer informatics community for polymer discovery and optimization.