SPIO: Ensemble and Selective Strategies via LLM-Based Multi-Agent Planning in Automated Data Science
作者: Wonduk Seo, Juhyeon Lee, Yanjun Shao, Qingshan Zhou, Seunghyun Lee, Yi Bu
分类: cs.AI, cs.CL, cs.LG, cs.MA
发布日期: 2025-03-30 (更新: 2026-01-07)
备注: Under Review
💡 一句话要点
SPIO:基于LLM多智能体规划的集成与选择策略,用于自动化数据科学
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动化数据科学 多智能体系统 大型语言模型 集成学习 模型选择 特征工程 超参数调优
📋 核心要点
- 现有自动化数据科学方法依赖于僵化的单路径工作流程,限制了策略探索和优化。
- SPIO采用基于LLM的多智能体系统,在数据科学流程的各个模块生成并优化多个候选策略。
- 实验表明,SPIO在多个基准测试中显著优于现有方法,平均性能提升5.6%。
📝 摘要(中文)
大型语言模型(LLMs)已在自动化数据分析中实现了动态推理,但最近的多智能体系统仍然受到僵化的单路径工作流程的限制,这限制了战略探索,并经常导致次优结果。为了克服这些限制,我们提出了SPIO(Sequential Plan Integration and Optimization),该框架用自适应的多路径规划取代了僵化的工作流程,涵盖四个核心模块:数据预处理、特征工程、模型选择和超参数调优。在每个模块中,专门的智能体生成多样化的候选策略,这些策略由优化智能体级联和细化。SPIO提供两种操作模式:SPIO-S用于选择单个最佳pipeline,SPIO-E用于集成top-k pipeline以最大化鲁棒性。在Kaggle和OpenML基准上的广泛评估表明,SPIO始终优于最先进的基线,平均性能提升5.6%。通过显式地探索和集成多个解决方案路径,SPIO为自动化数据科学提供了更灵活、准确和可靠的基础。
🔬 方法详解
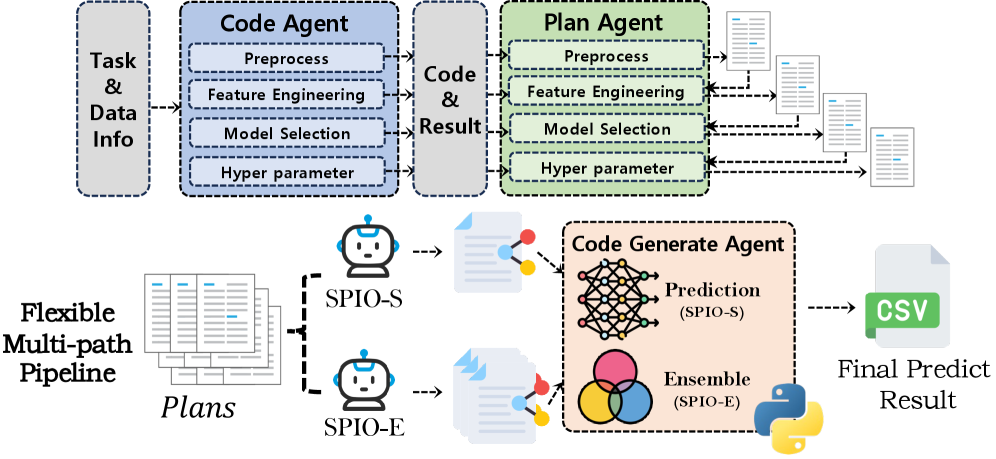
问题定义:自动化数据科学旨在自动构建数据分析pipeline,但现有方法通常采用预定义的、单一的流程,缺乏灵活性,难以适应不同数据集和任务的需求。这种僵化的流程限制了对多种策略的探索,导致最终性能受限。现有方法难以在数据预处理、特征工程、模型选择和超参数调优等各个阶段进行有效的策略组合和优化。
核心思路:SPIO的核心思路是利用大型语言模型(LLMs)驱动的多智能体系统,在数据科学pipeline的各个阶段并行探索多种候选策略。通过集成和优化这些策略,SPIO能够找到更优的pipeline配置,并提高模型的鲁棒性。这种多路径探索的思想借鉴了集成学习的优势,通过组合多个模型的预测结果来提高整体性能。
技术框架:SPIO框架包含四个核心模块:数据预处理、特征工程、模型选择和超参数调优。每个模块都由多个专门的智能体组成,这些智能体负责生成不同的候选策略。一个优化智能体负责评估和选择这些策略,并将其组合成完整的pipeline。SPIO提供两种操作模式:SPIO-S选择单个最佳pipeline,SPIO-E集成top-k pipeline。整个流程是顺序执行的,每个模块的输出作为下一个模块的输入。
关键创新:SPIO的关键创新在于其基于LLM的多智能体规划方法,它将自动化数据科学流程分解为多个可并行探索的阶段,并利用LLM的推理能力生成多样化的候选策略。与传统的单路径方法相比,SPIO能够更全面地探索解决方案空间,并找到更优的pipeline配置。此外,SPIO的集成模式能够提高模型的鲁棒性,减少对特定数据集的过拟合。
关键设计:SPIO使用LLM作为智能体的核心驱动力,通过prompt engineering来指导LLM生成候选策略。优化智能体使用验证集上的性能指标来评估和选择策略。SPIO-E模式使用加权平均的方式集成top-k pipeline的预测结果,权重根据验证集上的性能确定。具体的LLM选择、prompt设计和优化算法的选择是影响SPIO性能的关键因素,但论文中没有详细说明这些细节,属于未知信息。
🖼️ 关键图片


📊 实验亮点
SPIO在Kaggle和OpenML基准测试中取得了显著的性能提升。在这些基准测试中,SPIO平均优于最先进的基线5.6%。具体而言,SPIO-E模式通常优于SPIO-S模式,表明集成多个pipeline可以提高模型的鲁棒性。实验结果表明,SPIO能够有效地探索和集成多个解决方案路径,从而提高自动化数据科学的性能。
🎯 应用场景
SPIO可应用于各种需要自动化数据分析的场景,例如金融风险评估、医疗诊断、市场营销等。它可以帮助数据科学家快速构建高性能的模型,并减少人工干预的需求。SPIO的自适应性和鲁棒性使其能够适应不同的数据集和任务,具有广泛的应用前景。未来,SPIO可以进一步扩展到支持更多的数据类型和模型,并与其他自动化机器学习工具集成。
📄 摘要(原文)
Large Language Models (LLMs) have enabled dynamic reasoning in automated data analytics, yet recent multi-agent systems remain limited by rigid, single-path workflows that restrict strategic exploration and often lead to suboptimal outcomes. To overcome these limitations, we propose SPIO (Sequential Plan Integration and Optimization), a framework that replaces rigid workflows with adaptive, multi-path planning across four core modules: data preprocessing, feature engineering, model selection, and hyperparameter tuning. In each module, specialized agents generate diverse candidate strategies, which are cascaded and refined by an optimization agent. SPIO offers two operating modes: SPIO-S for selecting a single optimal pipeline, and SPIO-E for ensembling top-k pipelines to maximize robustness. Extensive evaluations on Kaggle and OpenML benchmarks show that SPIO consistently outperforms state-of-the-art baselines, achieving an average performance gain of 5.6%. By explicitly exploring and integrating multiple solution paths, SPIO delivers a more flexible, accurate, and reliable foundation for automated data science.