QuestBench: Can LLMs ask the right question to acquire information in reasoning tasks?
作者: Belinda Z. Li, Been Kim, Zi Wang
分类: cs.AI, cs.CL, cs.LG
发布日期: 2025-03-28 (更新: 2025-10-24)
备注: Code and dataset are available at \url{https://github.com/google-deepmind/questbench}
期刊: 39th Conference on Neural Information Processing Systems (NeurIPS 2025) Track on Datasets and Benchmarks
💡 一句话要点
QuestBench:评估LLM在不完备信息下提问以完成推理任务的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 信息获取 推理任务 约束满足问题 基准测试 不完备信息 主动提问
📋 核心要点
- 现有LLM在明确定义的推理任务上表现出色,但在现实世界中,任务往往不明确,需要主动获取信息才能解决。
- QuestBench将信息获取问题形式化为约束满足问题,通过评估LLM提问以补全缺失信息的能力来衡量其推理能力。
- 实验表明,即使LLM能解决完备信息下的推理问题,在QuestBench上表现仍然欠佳,凸显了信息获取能力的重要性。
📝 摘要(中文)
大型语言模型(LLM)在数学和逻辑等推理基准测试中表现出令人印象深刻的性能。然而,许多工作主要假设任务是明确定义的,但现实世界的查询通常是不明确的,只有通过获取缺失的信息才能解决。本文将这种信息收集问题形式化为一个具有缺失变量赋值的约束满足问题(CSP)。在一个仅缺失一个必要变量赋值的特殊情况下,可以评估LLM识别所需最小必要问题的能力。本文提出了QuestBench,这是一组可以通过最多提问一个问题来解决的不明确推理任务,包括:(1)Logic-Q:具有一个缺失命题的逻辑推理任务,(2)Planning-Q:具有部分观察到的初始状态的PDDL规划问题,(3)GSM-Q:具有一个未知变量的人工标注的小学数学问题,以及(4)GSME-Q:GSM-Q的基于方程的版本。LLM必须从多个选项中选择正确的澄清问题。虽然当前的模型擅长GSM-Q和GSME-Q,但在Logic-Q和Planning-Q上仅达到40-50%的准确率。分析表明,解决明确定义的推理问题的能力不足以在本文的基准测试中取得成功:即使模型可以解决完全指定的版本,它们也难以识别正确的问题。这突出了专门优化模型的信息获取能力的必要性。
🔬 方法详解
问题定义:论文旨在解决LLM在信息不完备情况下进行有效推理的问题。现有方法通常假设任务定义明确,忽略了现实世界中任务常常需要主动提问以获取缺失信息才能解决的情况。这种忽略导致LLM在实际应用中表现受限。
核心思路:论文的核心思路是将信息获取过程建模为一个约束满足问题(CSP),其中部分变量的赋值缺失。通过设计一系列需要LLM主动提问以获取缺失信息的推理任务,来评估LLM的信息获取能力。这种方法能够更真实地反映LLM在实际应用中的表现。
技术框架:QuestBench包含四个子任务:Logic-Q(逻辑推理)、Planning-Q(规划问题)、GSM-Q(小学数学题)和GSME-Q(小学数学题的方程版本)。每个任务都设计成缺失一个关键信息,LLM需要从多个选项中选择最合适的提问,以获取该信息并完成推理。整体流程包括:1. 给定不完备信息的推理任务;2. LLM从候选问题集中选择一个问题;3. 根据回答补全信息;4. LLM基于完备信息进行推理并给出答案。
关键创新:论文的关键创新在于提出了QuestBench,这是一个专门用于评估LLM在信息不完备情况下进行推理和信息获取能力的基准测试。与以往侧重于评估LLM在明确定义任务上的推理能力不同,QuestBench更关注LLM主动获取信息的能力,这更贴近现实世界的应用场景。
关键设计:QuestBench的关键设计在于其任务的构造方式。每个任务都经过精心设计,确保只缺失一个关键信息,并且提供多个候选问题,其中只有一个是正确的。这使得可以精确地评估LLM识别和选择正确问题的能力。此外,GSM-Q和GSME-Q任务使用了人工标注和方程两种形式,可以更全面地评估LLM在不同类型任务上的表现。
🖼️ 关键图片

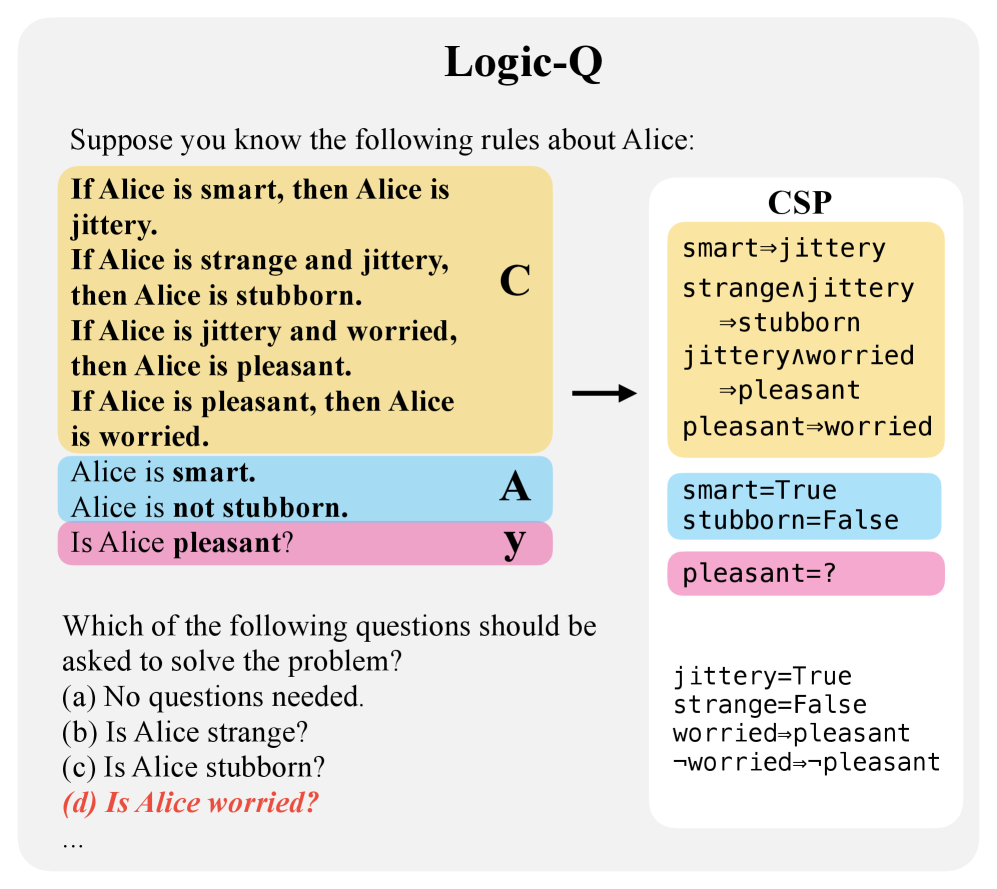
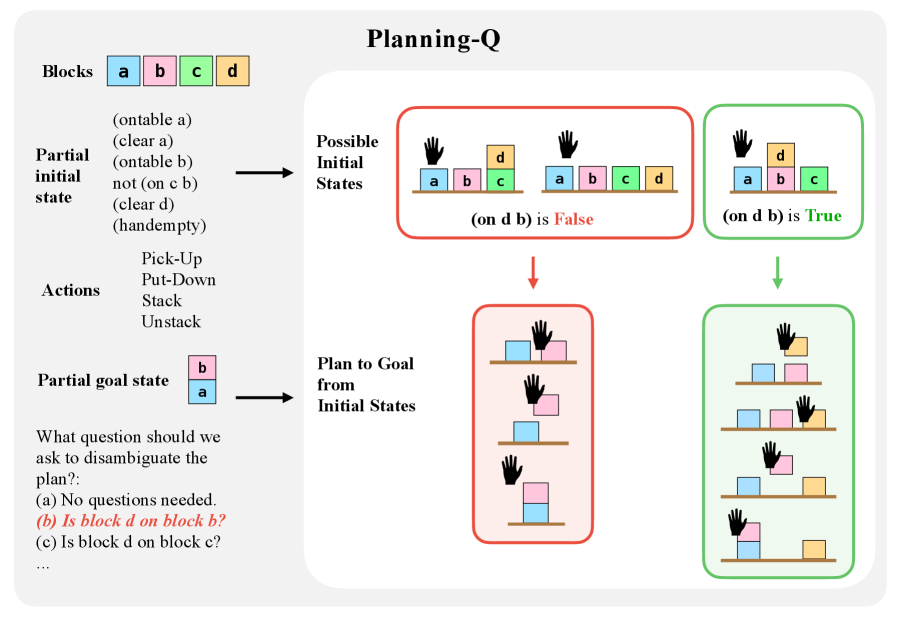
📊 实验亮点
实验结果表明,虽然LLM在GSM-Q和GSME-Q上表现良好,但在Logic-Q和Planning-Q上的准确率仅为40-50%。这表明,即使LLM能够解决完备信息下的推理问题,其信息获取能力仍然不足。该研究强调了专门优化LLM信息获取能力的重要性。
🎯 应用场景
该研究成果可应用于智能助手、问答系统、自动化规划等领域。通过提升LLM在信息不完备情况下的推理能力,可以使其更好地理解用户意图,主动获取所需信息,从而提供更准确、更有效的服务。未来,该研究有望推动LLM在更广泛的实际场景中应用。
📄 摘要(原文)
Large language models (LLMs) have shown impressive performance on reasoning benchmarks like math and logic. While many works have largely assumed well-defined tasks, real-world queries are often underspecified and only solvable by acquiring missing information. We formalize this information-gathering problem as a constraint satisfaction problem (CSP) with missing variable assignments. Using a special case where only one necessary variable assignment is missing, we can evaluate an LLM's ability to identify the minimal necessary question to ask. We present QuestBench, a set of underspecified reasoning tasks solvable by asking at most one question, which includes: (1) Logic-Q: logical reasoning tasks with one missing proposition, (2) Planning-Q: PDDL planning problems with partially-observed initial states, (3) GSM-Q: human-annotated grade school math problems with one unknown variable, and (4) GSME-Q: equation-based version of GSM-Q. The LLM must select the correct clarification question from multiple options. While current models excel at GSM-Q and GSME-Q, they achieve only 40-50% accuracy on Logic-Q and Planning-Q. Analysis shows that the ability to solve well-specified reasoning problems is not sufficient for success on our benchmark: models struggle to identify the right question even when they can solve the fully specified version. This highlights the need for specifically optimizing models' information acquisition capabilities.