Make Some Noise: Towards LLM audio reasoning and generation using sound tokens
作者: Shivam Mehta, Nebojsa Jojic, Hannes Gamper
分类: eess.AS, cs.AI, cs.SD
发布日期: 2025-03-28
备注: 5 pages, 2 figures, Accepted at ICASSP 2025
DOI: 10.1109/ICASSP49660.2025.10888809
💡 一句话要点
提出基于声音令牌的LLM音频推理与生成方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大型语言模型 音频理解 音频生成 离散令牌 变分量化 条件流匹配 低秩自适应
📋 核心要点
- 现有方法难以将音频理解和生成集成到大型语言模型(LLM)中,主要挑战在于音频的连续性和由此产生的高采样率。
- 该论文提出了一种结合变分量化和条件流匹配的方法,将音频转换为超低比特率的离散令牌,以便与LLM中的文本令牌集成。
- 实验结果表明,该方法在音频理解方面具有竞争力,但音频生成效果不佳,表明需要更大的数据集和更好的评估指标。
📝 摘要(中文)
本文提出了一种新颖的方法,将变分量化与条件流匹配相结合,把音频转换为极低比特率(0.23kbps)的离散令牌,从而实现与LLM中的文本令牌的无缝集成。研究人员使用低秩自适应(LoRA)对预训练的基于文本的LLM进行微调,以评估其在实现真正的多模态能力(即音频理解和生成)方面的有效性。该tokenizer在各种具有不同声学事件的数据集上优于传统的VQ-VAE。尽管通过音频令牌化大量损失了精细的细节,但使用离散令牌训练的多模态LLM在音频理解方面取得了与最先进方法相媲美的结果,但音频生成效果较差。结果表明,需要更大、更多样化的数据集和改进的评估指标来提高多模态LLM的性能。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中音频理解和生成能力不足的问题。现有方法由于音频信号的连续性和高采样率,难以直接将音频信息融入到LLM中,限制了LLM在多模态任务中的应用。
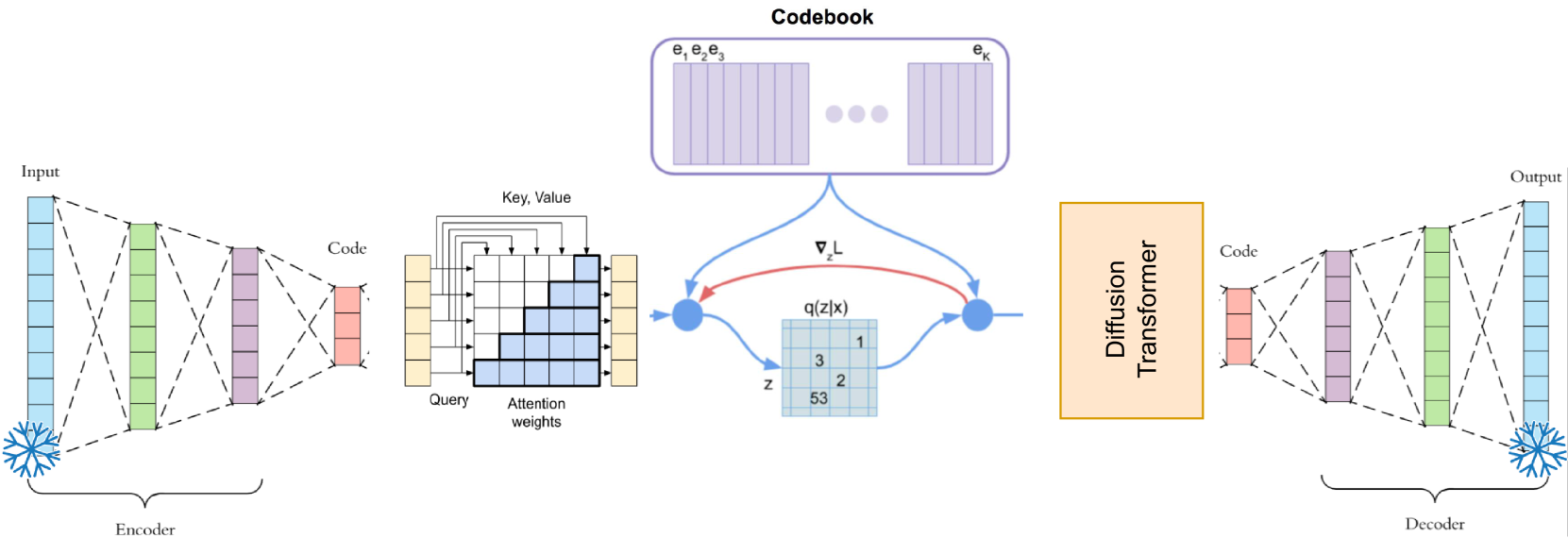
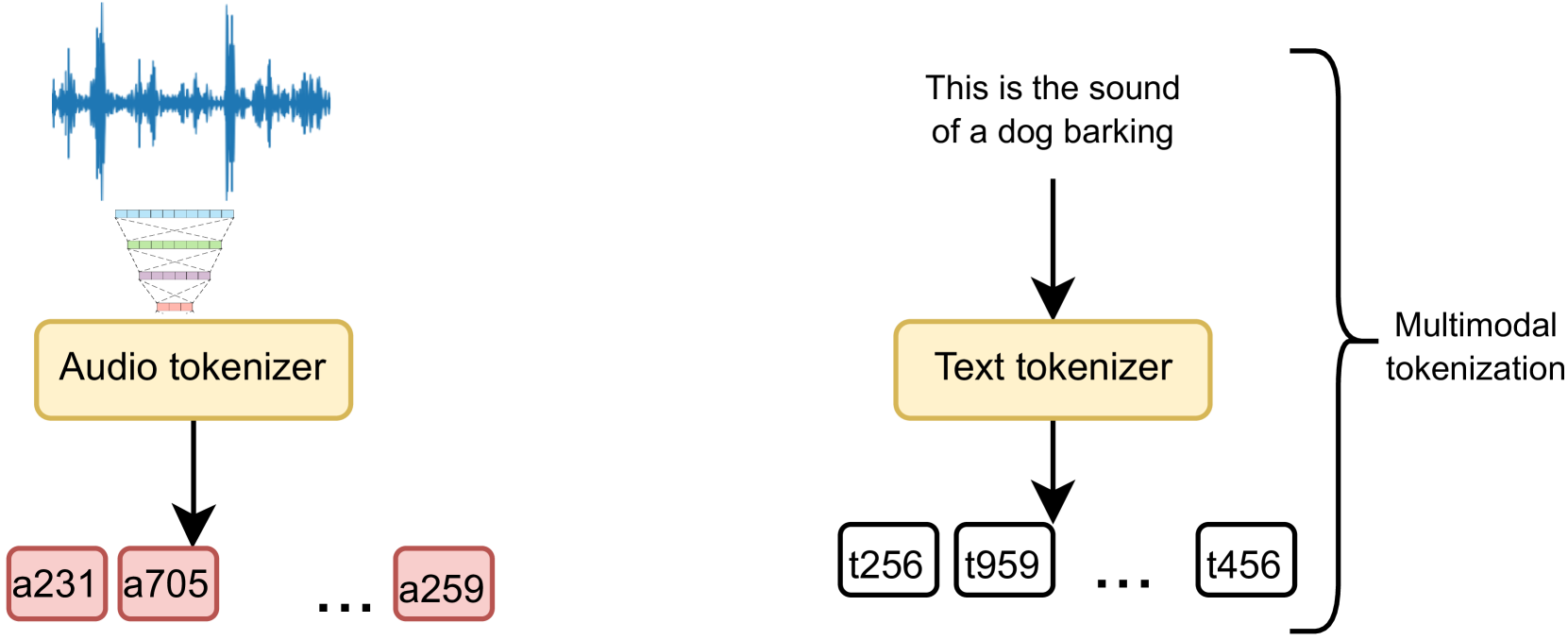
核心思路:论文的核心思路是将连续的音频信号转换为离散的音频令牌,类似于文本令牌,从而使得LLM能够像处理文本一样处理音频。通过将音频转换为低比特率的离散表示,降低了计算复杂度,并使得音频信息能够更容易地与文本信息融合。
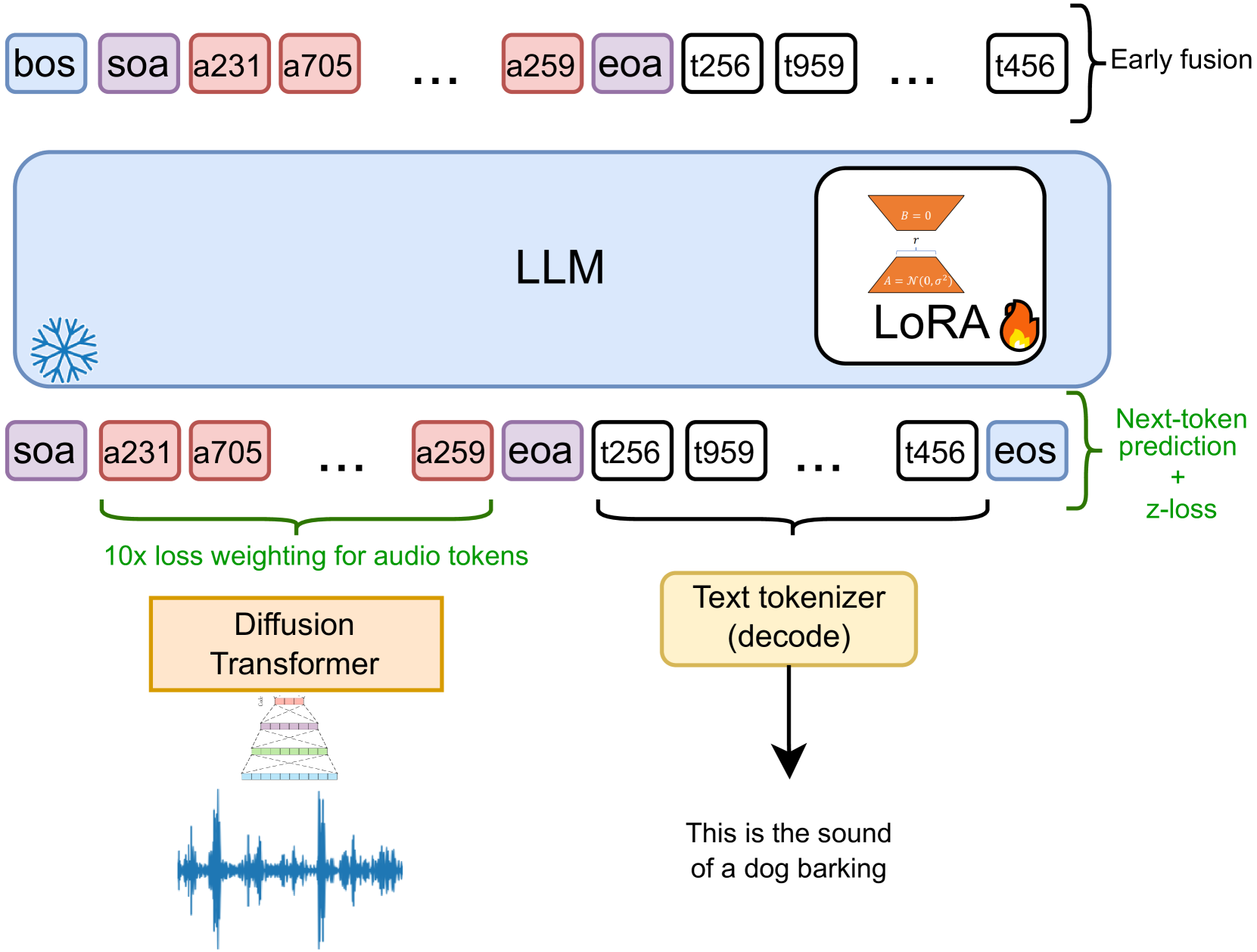
技术框架:整体框架包含两个主要阶段:音频令牌化和多模态LLM微调。首先,使用结合变分量化和条件流匹配的tokenizer将音频转换为离散令牌。然后,使用低秩自适应(LoRA)方法,在预训练的文本LLM上微调,使其能够同时处理文本和音频令牌。微调后的LLM可以用于音频理解和生成任务。
关键创新:该论文的关键创新在于提出了一种有效的音频令牌化方法,能够将音频信号压缩到极低的比特率(0.23kbps),同时保持足够的音频信息,以便LLM进行理解。这种方法结合了变分量化和条件流匹配,能够生成高质量的离散音频令牌。
关键设计:音频令牌化器使用变分量化(VQ)将音频特征映射到离散码本,并使用条件流匹配(CFM)来优化量化过程,从而减少量化误差。LLM的微调使用LoRA,通过引入低秩矩阵来更新LLM的参数,从而降低了计算成本和内存需求。损失函数包括语言模型损失和音频重建损失,用于优化LLM的文本和音频处理能力。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该论文提出的音频令牌化方法在各种数据集上优于传统的VQ-VAE。尽管音频令牌化过程损失了部分细节,但使用离散令牌训练的多模态LLM在音频理解方面取得了与最先进方法相媲美的结果。虽然音频生成效果不佳,但该研究为多模态LLM的发展提供了有价值的思路。
🎯 应用场景
该研究成果可应用于语音助手、智能客服、多媒体内容创作等领域。例如,可以构建能够理解语音指令并生成相应音频反馈的智能助手,或者开发能够根据文本描述生成逼真音效的多媒体编辑工具。未来,该技术有望促进人机交互方式的变革,并推动多模态人工智能的发展。
📄 摘要(原文)
Integrating audio comprehension and generation into large language models (LLMs) remains challenging due to the continuous nature of audio and the resulting high sampling rates. Here, we introduce a novel approach that combines Variational Quantization with Conditional Flow Matching to convert audio into ultra-low bitrate discrete tokens of 0.23kpbs, allowing for seamless integration with text tokens in LLMs. We fine-tuned a pretrained text-based LLM using Low-Rank Adaptation (LoRA) to assess its effectiveness in achieving true multimodal capabilities, i.e., audio comprehension and generation. Our tokenizer outperforms a traditional VQ-VAE across various datasets with diverse acoustic events. Despite the substantial loss of fine-grained details through audio tokenization, our multimodal LLM trained with discrete tokens achieves competitive results in audio comprehension with state-of-the-art methods, though audio generation is poor. Our results highlight the need for larger, more diverse datasets and improved evaluation metrics to advance multimodal LLM performance.