Data Poisoning in Deep Learning: A Survey
作者: Pinlong Zhao, Weiyao Zhu, Pengfei Jiao, Di Gao, Ou Wu
分类: cs.CR, cs.AI
发布日期: 2025-03-27
🔗 代码/项目: GITHUB
💡 一句话要点
深度学习数据投毒攻击综述:全面分析与未来方向
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据投毒 深度学习 对抗攻击 模型安全 大型语言模型 机器学习安全 恶意攻击
📋 核心要点
- 深度学习模型易受数据投毒攻击,现有综述缺乏对深度学习中投毒攻击的深入分析。
- 本综述全面回顾深度学习中的数据投毒,从多角度分类攻击,并分析其特征和设计原则。
- 探讨了大型语言模型中的数据投毒,并提出了该领域面临的挑战和未来研究方向。
📝 摘要(中文)
深度学习已成为现代人工智能的基石,在广泛领域实现了变革性应用。作为深度学习的核心要素,训练数据的质量和安全性至关重要,直接影响模型的性能和可靠性。然而,在训练过程中,深度学习模型面临数据投毒的重大威胁,攻击者通过引入恶意操纵的训练数据来降低模型准确性或导致异常行为。现有综述对数据投毒提供了有价值的见解,但通常采用广泛的视角,涵盖攻击和防御,缺乏对深度学习中投毒攻击的专门深入分析。本综述弥补了这一差距,对深度学习中的数据投毒进行了全面而有针对性的回顾。首先,本综述从多个角度对数据投毒攻击进行分类,深入分析其特征和底层设计原则。其次,讨论扩展到大型语言模型(LLM)中新兴的数据投毒领域。最后,我们探讨了该领域面临的关键开放挑战,并提出了潜在的研究方向,以进一步推进该领域的发展。为了支持进一步探索,可在https://github.com/Pinlong-Zhao/Data-Poisoning 获取关于深度学习数据投毒的最新资源。
🔬 方法详解
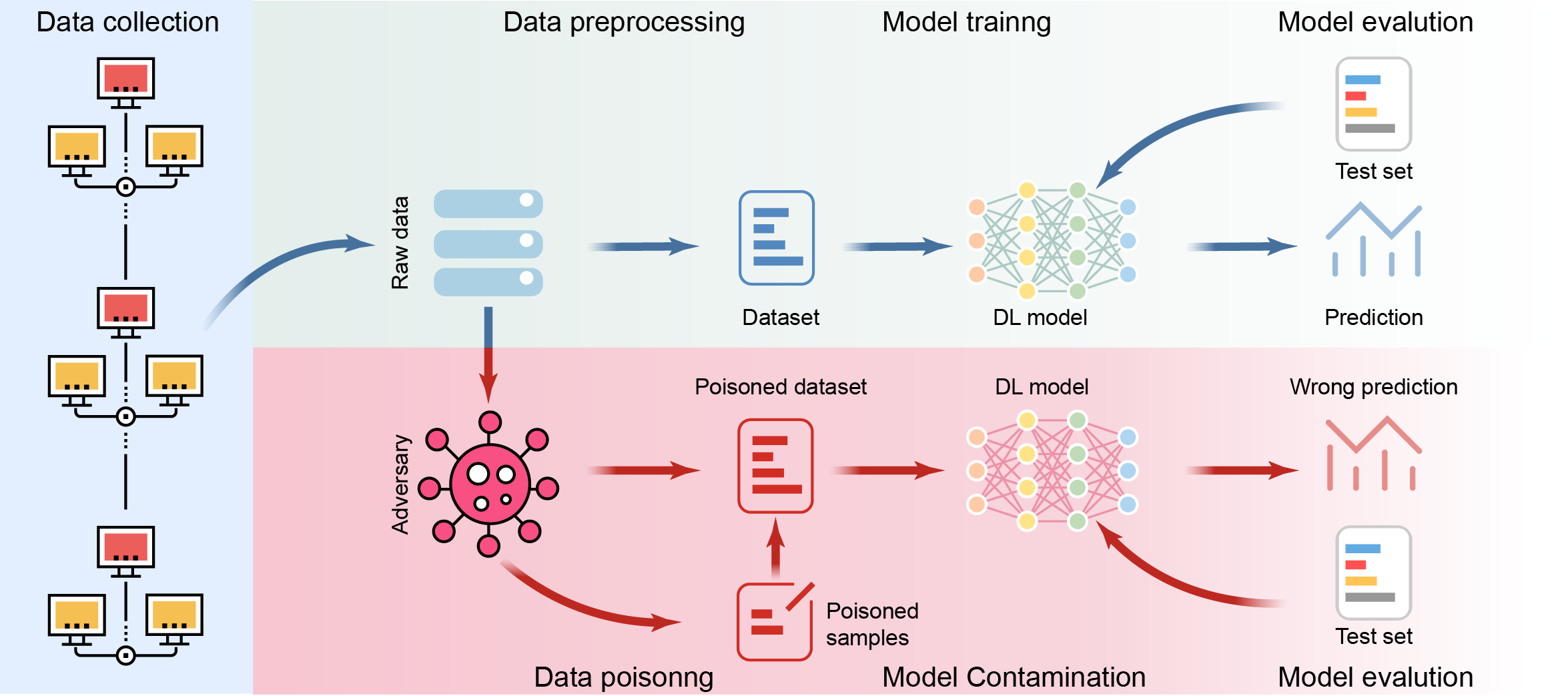
问题定义:论文旨在解决深度学习模型在训练过程中面临的数据投毒攻击问题。现有方法往往泛泛而谈,缺乏针对深度学习模型特点的深入分析,无法有效应对日益复杂的投毒攻击手段。此外,大型语言模型(LLM)的兴起带来了新的投毒挑战,现有研究对此关注不足。
核心思路:论文的核心思路是对深度学习中的数据投毒攻击进行系统性的分类和分析,从而更好地理解攻击的本质和原理。通过对不同类型的攻击进行归纳和总结,可以为防御策略的设计提供理论基础。同时,关注LLM中的数据投毒问题,为该领域的研究提供新的视角。
技术框架:论文的整体框架包括以下几个主要部分:首先,对数据投毒攻击进行定义和分类,从多个角度(例如攻击目标、攻击策略、攻击效果等)对攻击进行划分。其次,深入分析各类攻击的特征和底层设计原则,揭示攻击的内在机制。然后,将讨论扩展到LLM中的数据投毒问题,分析其特殊性和挑战。最后,探讨该领域面临的关键开放挑战,并提出潜在的研究方向。
关键创新:论文的关键创新在于其对深度学习数据投毒攻击的全面性和系统性分析。与现有综述相比,该论文更加专注于深度学习领域,并对攻击的分类和分析更加深入。此外,论文还关注了LLM中的数据投毒问题,为该领域的研究提供了新的视角。
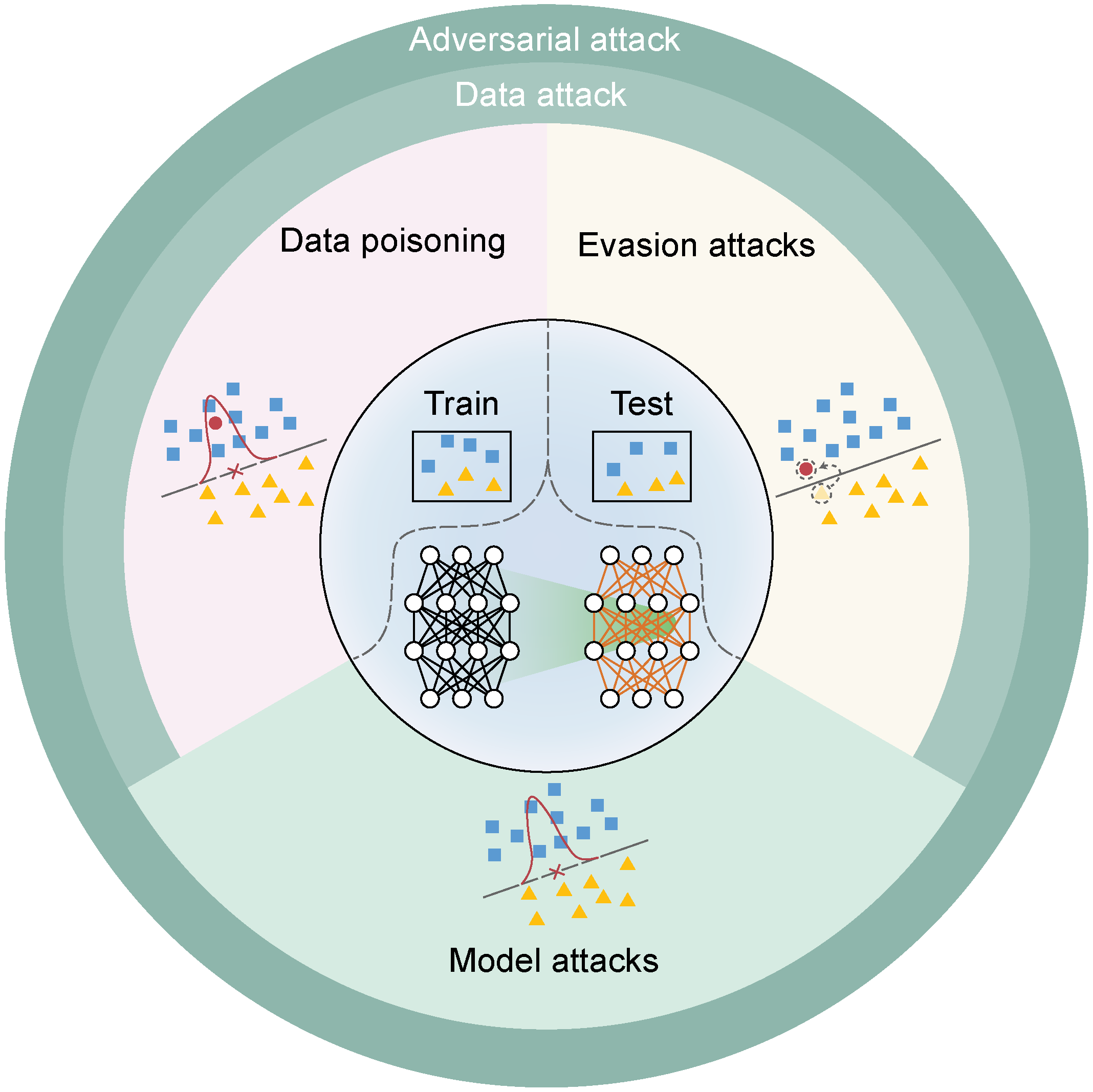
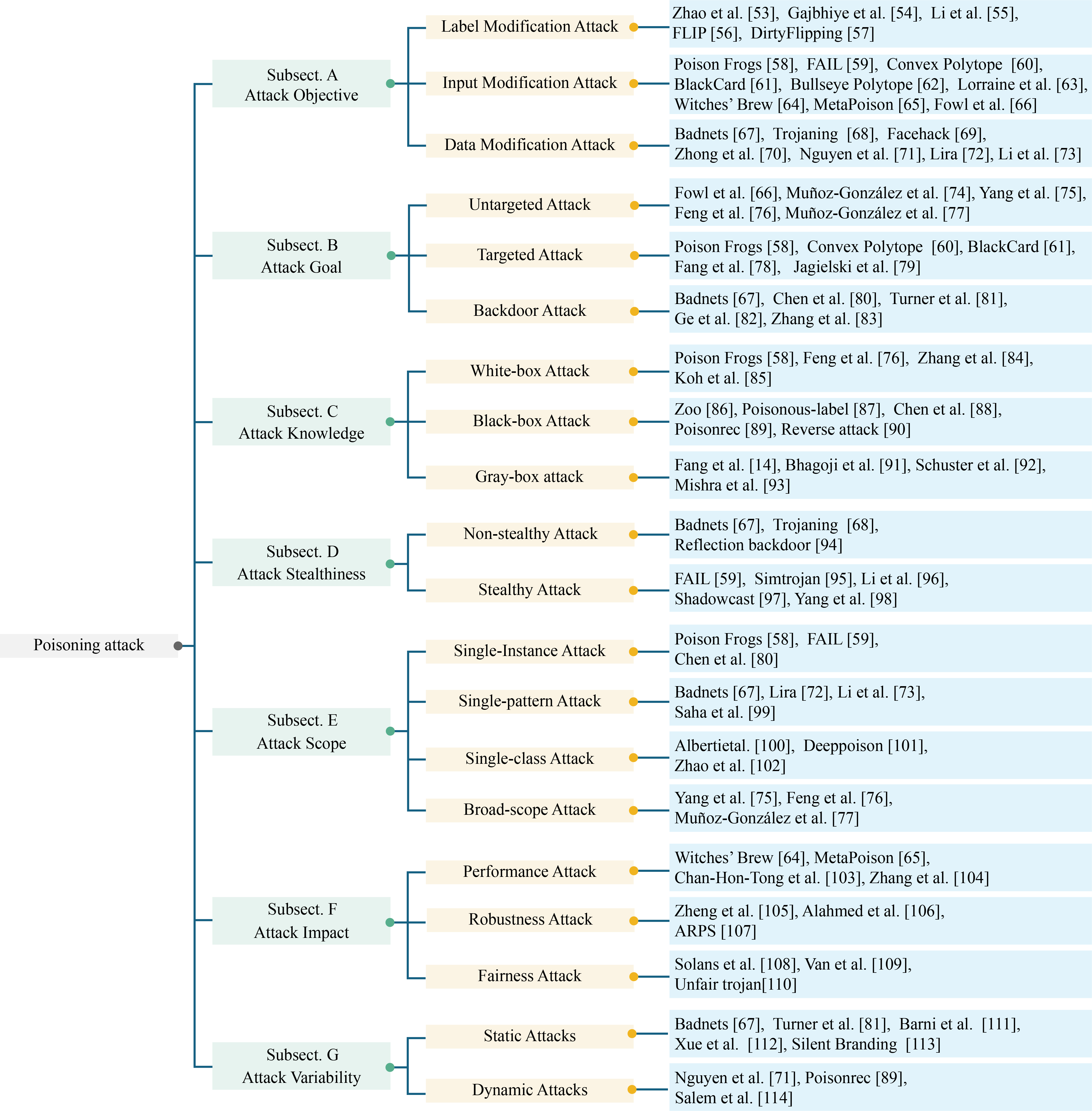
关键设计:论文的关键设计在于其对数据投毒攻击的分类体系。该分类体系从多个角度对攻击进行划分,例如攻击目标(降低模型准确性、导致异常行为等)、攻击策略(修改标签、修改特征等)、攻击效果(后门攻击、对抗样本攻击等)。通过这种分类,可以更清晰地理解不同类型攻击的特点和原理,为防御策略的设计提供指导。
🖼️ 关键图片
📊 实验亮点
该综述论文整理了大量关于深度学习数据投毒攻击的文献,并进行了系统性的分类和分析。论文在github上维护了一个最新的资源库,方便研究人员快速了解该领域的最新进展。该综述为后续研究者提供了宝贵的参考资料,有助于推动数据投毒防御技术的发展。
🎯 应用场景
该研究成果可应用于提升深度学习模型的安全性,尤其是在对安全性要求较高的领域,如自动驾驶、金融风控、医疗诊断等。通过深入理解数据投毒攻击的原理和特点,可以设计更有效的防御策略,保障模型的可靠性和稳定性,从而避免因恶意攻击造成的损失。
📄 摘要(原文)
Deep learning has become a cornerstone of modern artificial intelligence, enabling transformative applications across a wide range of domains. As the core element of deep learning, the quality and security of training data critically influence model performance and reliability. However, during the training process, deep learning models face the significant threat of data poisoning, where attackers introduce maliciously manipulated training data to degrade model accuracy or lead to anomalous behavior. While existing surveys provide valuable insights into data poisoning, they generally adopt a broad perspective, encompassing both attacks and defenses, but lack a dedicated, in-depth analysis of poisoning attacks specifically in deep learning. In this survey, we bridge this gap by presenting a comprehensive and targeted review of data poisoning in deep learning. First, this survey categorizes data poisoning attacks across multiple perspectives, providing an in-depth analysis of their characteristics and underlying design princinples. Second, the discussion is extended to the emerging area of data poisoning in large language models(LLMs). Finally, we explore critical open challenges in the field and propose potential research directions to advance the field further. To support further exploration, an up-to-date repository of resources on data poisoning in deep learning is available at https://github.com/Pinlong-Zhao/Data-Poisoning.