MAVERIX: Multimodal Audio-Visual Evaluation and Recognition IndeX
作者: Liuyue Xie, Avik Kuthiala, George Z. Wei, Ce Zheng, Ananya Bal, Mosam Dabhi, Liting Wen, Taru Rustagi, Ethan Lai, Sushil Khyalia, Rohan Choudhury, Morteza Ziyadi, Xu Zhang, Hao Yang, László A. Jeni
分类: cs.MM, cs.AI, cs.CV, cs.SD, eess.AS
发布日期: 2025-03-27 (更新: 2025-12-06)
期刊: AAAI 2026
💡 一句话要点
MAVERIX:多模态视听评估与识别基准,用于评估LLM的视频理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视听融合 视频理解 大型语言模型 评估基准
📋 核心要点
- 现有模型在视听理解方面进步显著,但缺乏标准化的跨模态理解评估框架,难以全面评估模型性能。
- MAVERIX基准通过构建包含视听信息的问答数据集,模拟人类感知体验,从而评估模型对多模态信息的整合能力。
- 实验表明,现有SOTA模型在MAVERIX上的表现与人类专家存在显著差距,为未来研究提供了明确的提升方向。
📝 摘要(中文)
本文提出了MAVERIX(多模态视听评估与识别索引),这是一个统一的基准,旨在探测多模态LLM中的视频理解能力,涵盖视频、音频、文本输入,并提供人类表现基线。尽管最近在具有视觉和音频理解能力的模型方面取得了显著进展,但该领域缺乏一个标准化的评估框架来彻底评估其跨模态理解性能。MAVERIX从700个视频中整理了2556个问题,以多项选择和开放式格式呈现,专门设计用于通过需要紧密集成视频和音频信息的问题来评估多模态模型,涵盖了广泛的智能体场景。MAVERIX独特地为模型提供了视听问题,密切模仿了人类在推理和决策过程中可获得的多模态感知体验。据我们所知,MAVERIX是第一个旨在如此细粒度地评估全面视听集成的基准。使用最先进的模型(包括Qwen 2.5 Omni和Gemini 2.5 Flash-Lite)进行的实验表明,准确率约为64%,而人类专家的表现接近上限,达到92.8%,这表明与人类水平的理解之间存在巨大差距。通过标准化的评估协议、严格注释的流程和公共工具包,MAVERIX为推进视听多模态智能建立了一个具有挑战性的测试平台。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)在处理多模态信息,特别是视听信息时,缺乏一个统一且具有挑战性的评估基准。现有的评估方法可能无法充分测试模型对视频和音频信息进行深度融合和推理的能力,导致模型在实际应用中表现不佳。
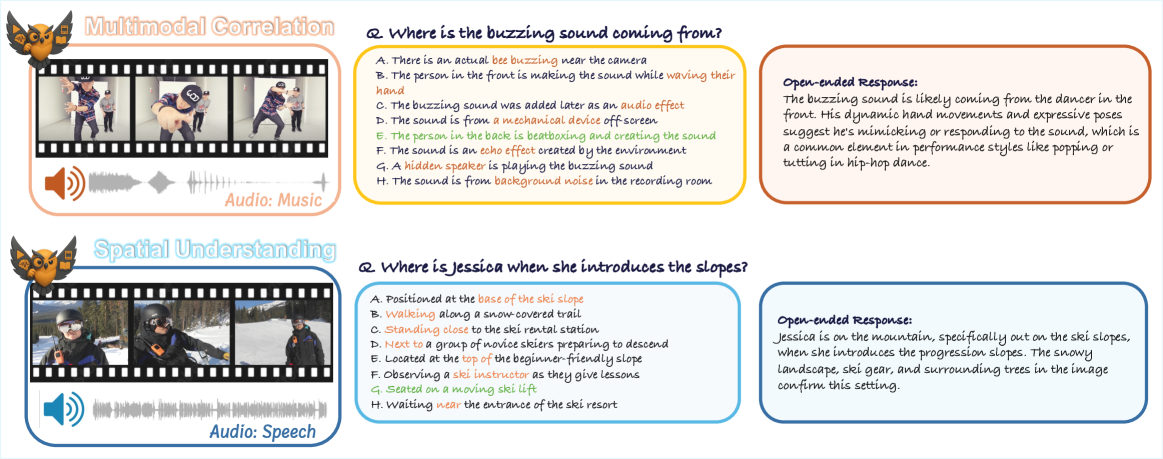
核心思路:MAVERIX的核心思路是构建一个高质量的视听问答数据集,该数据集中的问题需要模型同时理解和整合视频和音频信息才能正确回答。通过模拟人类的视听感知体验,MAVERIX能够更真实地评估模型的多模态理解能力。
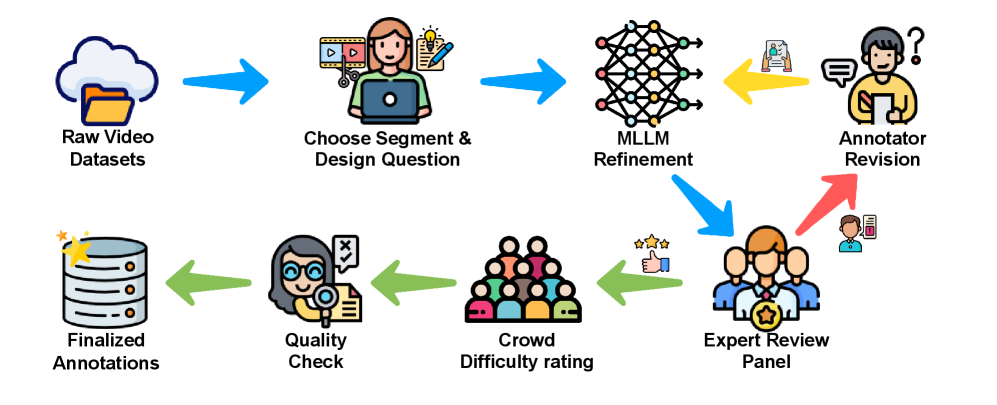
技术框架:MAVERIX的整体框架包括以下几个主要阶段:1) 数据收集:从各种来源收集包含丰富视听信息的视频。2) 问题生成:人工标注人员根据视频内容设计需要视听信息融合才能回答的问题,包括多项选择题和开放式问题。3) 数据验证:对生成的问题进行审核和验证,确保问题的质量和准确性。4) 模型评估:使用MAVERIX数据集评估各种多模态LLM的性能,并与人类表现进行比较。
关键创新:MAVERIX的关键创新在于其专注于视听信息的深度融合。与以往的基准测试相比,MAVERIX更加强调模型对视频和音频信息之间关系的理解和推理能力。此外,MAVERIX还提供了人类表现基线,为模型性能评估提供了一个更可靠的参考。
关键设计:MAVERIX在问题设计上,特别关注需要模型进行时间推理、因果关系判断、以及对声音事件和视觉事件进行关联的问题。数据集包含多种场景,例如:动作识别、场景理解、对话理解等。数据集的标注流程经过严格设计,以确保标注质量和一致性。未知
🖼️ 关键图片

📊 实验亮点
实验结果表明,当前最先进的多模态模型(如Qwen 2.5 Omni和Gemini 2.5 Flash-Lite)在MAVERIX上的准确率约为64%,而人类专家可以达到92.8%的准确率。这表明,尽管现有模型在多模态理解方面取得了进展,但与人类水平的理解能力仍然存在显著差距。MAVERIX为未来的研究提供了一个明确的性能目标。
🎯 应用场景
MAVERIX基准的潜在应用领域包括智能助手、视频监控、自动驾驶等。通过提高模型对视听信息的理解能力,可以提升这些应用在复杂环境中的感知和决策能力。未来,MAVERIX可以促进多模态LLM在实际场景中的应用,例如:帮助听障人士理解视频内容,或辅助自动驾驶系统识别紧急情况。
📄 摘要(原文)
We introduce MAVERIX (Multimodal audiovisual Evaluation and Recognition IndeX), a unified benchmark to probe the video understanding in multimodal LLMs, encompassing video, audio, text inputs with human performance baselines. Although recent advancements in models with vision and audio understanding capabilities have shown substantial progress, the field lacks a standardized evaluation framework to thoroughly assess their cross-modality comprehension performance. MAVERIX curates 2,556 questions from 700 videos, in the form of both multiple-choice and open-ended formats, explicitly designed to evaluate multimodal models through questions that necessitate tight integration of video and audio information, spanning a broad spectrum of agentic scenarios. MAVERIX uniquely provides models with audiovisual questions, closely mimicking the multimodal perceptual experiences available to humans during inference and decision-making processes. To our knowledge, MAVERIX is the first benchmark aimed explicitly at assessing comprehensive audiovisual integration in such granularity. Experiments with state-of-the-art models, including Qwen 2.5 Omni and Gemini 2.5 Flash-Lite, show performance around 64% accuracy, while human experts reach near-ceiling performance of 92.8%, exposing a substantial gap to human-level comprehension. With standardized evaluation protocols, a rigorously annotated pipeline, and a public toolkit, MAVERIX establishes a challenging testbed for advancing audiovisual multimodal intelligence.