FinAudio: A Benchmark for Audio Large Language Models in Financial Applications
作者: Yupeng Cao, Haohang Li, Yangyang Yu, Shashidhar Reddy Javaji, Yueru He, Jimin Huang, Qianqian Xie, Fabrizio Dimino, Xiao-yang Liu, K. P. Subbalakshmi, Meikang Qiu, Sophia Ananiadou, Jian-Yun Nie
分类: cs.CE, cs.AI, cs.MM
发布日期: 2025-03-26 (更新: 2025-12-18)
💡 一句话要点
FinAudio:金融场景下音频大语言模型评测基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 金融音频 音频大语言模型 评测基准 自动语音识别 音频摘要 金融分析 投资决策
📋 核心要点
- 现有音频大语言模型在金融领域的应用缺乏专门的评测基准,无法有效评估其在金融音频数据上的性能。
- 论文构建了FinAudio基准,包含短/长金融音频的语音识别和长金融音频摘要三个任务,以全面评估模型能力。
- 通过在FinAudio上评估现有AudioLLMs,揭示了它们在金融领域的不足,并为未来的模型改进提供了方向。
📝 摘要(中文)
音频大语言模型(AudioLLMs)在对话、音频理解和自动语音识别(ASR)等音频任务中取得了显著进展。然而,目前缺乏针对金融场景下AudioLLMs的评估基准。在金融领域,盈利电话会议和CEO演讲等音频数据对于金融分析和投资决策至关重要。本文提出了 extsc{FinAudio},这是首个旨在评估AudioLLMs在金融领域能力的基准。我们首先根据金融领域的独特特征定义了三个任务:1) 短金融音频的ASR,2) 长金融音频的ASR,以及3) 长金融音频的摘要。然后,我们分别整理了两个短音频和两个长音频数据集,并开发了一个用于金融音频摘要的新数据集,构成了 extsc{FinAudio}基准。我们评估了七个流行的AudioLLMs在 extsc{FinAudio}上的表现。评估结果揭示了现有AudioLLMs在金融领域的局限性,并为改进AudioLLMs提供了见解。所有数据集和代码都将发布。
🔬 方法详解
问题定义:现有音频大语言模型(AudioLLMs)在通用音频任务上表现出色,但在金融领域的应用受限于缺乏专门的评估基准。金融音频数据,如盈利电话会议和CEO演讲,具有独特的领域特征,现有方法难以有效评估模型在这些数据上的性能。因此,需要一个专门的基准来评估AudioLLMs在金融领域的语音识别和理解能力。
核心思路:论文的核心思路是构建一个专门针对金融音频的评测基准,即FinAudio。该基准包含多个任务,覆盖了金融音频处理的关键方面,如短音频和长音频的语音识别,以及长音频的摘要生成。通过在FinAudio上评估现有AudioLLMs,可以系统地分析它们的优势和不足,并为未来的模型改进提供指导。
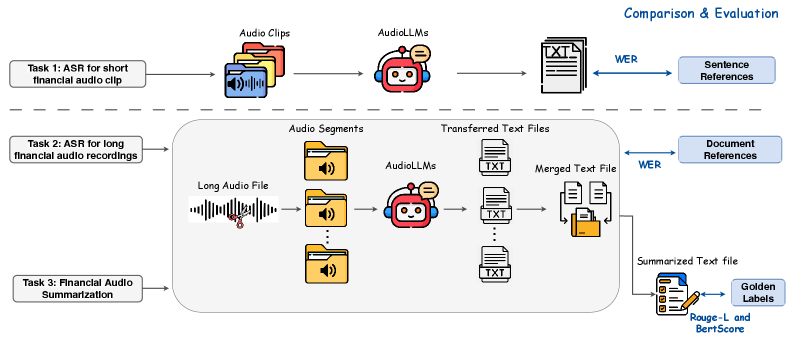
技术框架:FinAudio基准主要包含三个任务:1) 短金融音频的自动语音识别(ASR),2) 长金融音频的ASR,以及3) 长金融音频的摘要。为了支持这些任务,论文整理了两个短音频数据集和两个长音频数据集,并开发了一个新的金融音频摘要数据集。整个流程包括数据收集、数据清洗、任务定义和数据集构建。
关键创新:FinAudio是首个专门针对金融音频的AudioLLM评测基准。其创新之处在于:1) 针对金融领域的特点设计了评测任务,如长音频摘要,更贴合实际应用需求;2) 构建了高质量的金融音频数据集,为模型评估提供了可靠的数据基础;3) 通过对现有AudioLLMs的全面评估,揭示了它们在金融领域的局限性,为未来的研究方向提供了指导。
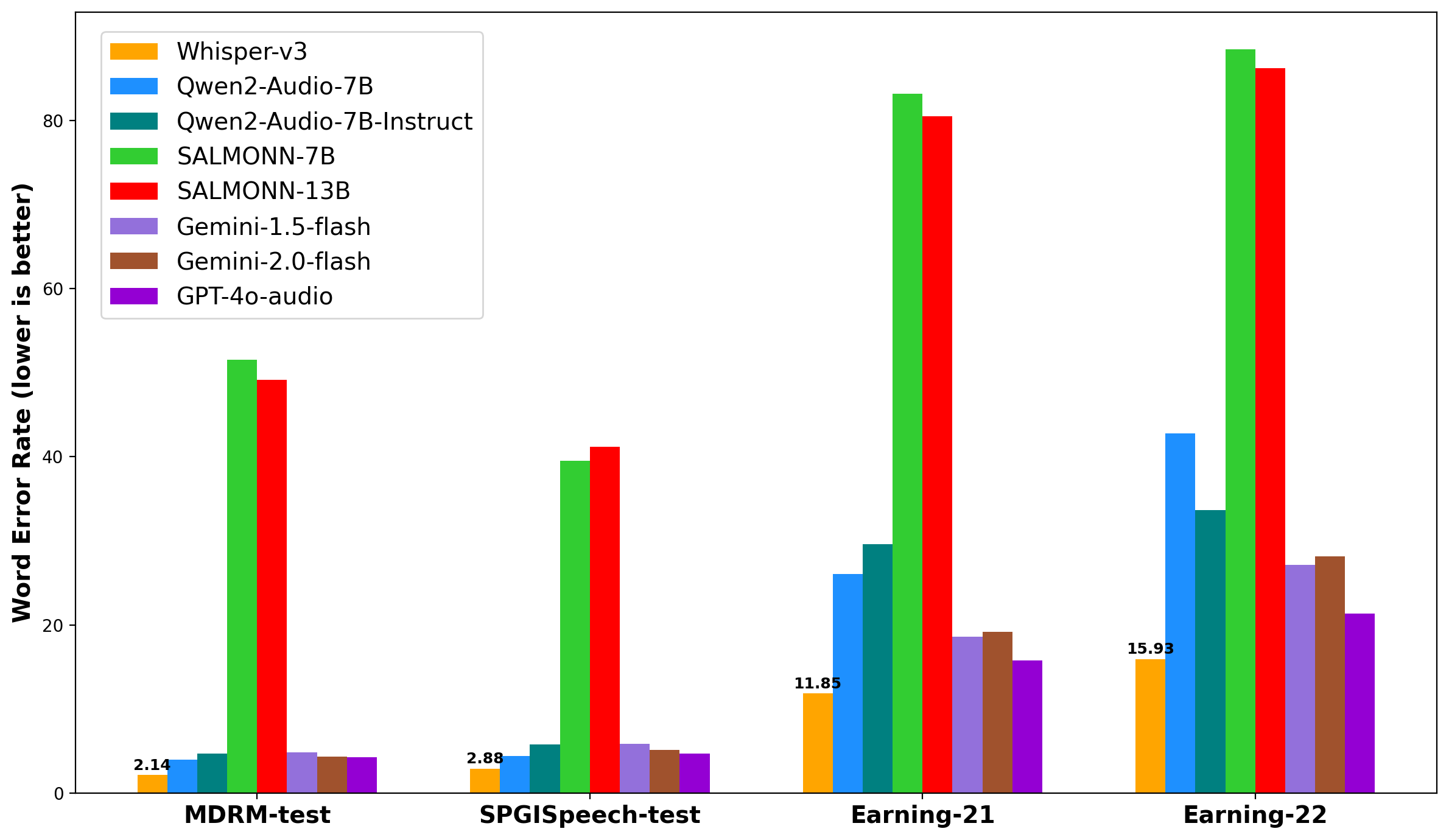
关键设计:数据集构建方面,论文收集了公开可用的金融音频数据,并进行了人工标注和验证,以保证数据的质量。在模型评估方面,论文采用了标准的语音识别和摘要评估指标,如词错误率(WER)和ROUGE分数,以客观地衡量模型的性能。具体的参数设置和网络结构取决于被评估的AudioLLMs,论文主要关注的是模型在FinAudio上的整体表现。
🖼️ 关键图片

📊 实验亮点
论文在FinAudio基准上评估了七个流行的AudioLLMs,结果表明现有模型在金融音频处理方面存在明显的局限性。例如,在长音频摘要任务上,模型的性能远低于人类水平。这些结果突出了针对金融领域优化AudioLLMs的必要性,并为未来的研究提供了明确的方向。
🎯 应用场景
该研究成果可应用于金融信息处理、智能投顾、风险管理等领域。通过提升AudioLLMs在金融音频数据上的性能,可以更有效地从盈利电话会议、CEO演讲等音频信息中提取关键信息,辅助投资决策,提高金融分析的效率和准确性。未来,该基准可以促进金融领域AudioLLM的进一步发展。
📄 摘要(原文)
Audio Large Language Models (AudioLLMs) have received widespread attention and have significantly improved performance on audio tasks such as conversation, audio understanding, and automatic speech recognition (ASR). Despite these advancements, there is an absence of a benchmark for assessing AudioLLMs in financial scenarios, where audio data, such as earnings conference calls and CEO speeches, are crucial resources for financial analysis and investment decisions. In this paper, we introduce \textsc{FinAudio}, the first benchmark designed to evaluate the capacity of AudioLLMs in the financial domain. We first define three tasks based on the unique characteristics of the financial domain: 1) ASR for short financial audio, 2) ASR for long financial audio, and 3) summarization of long financial audio. Then, we curate two short and two long audio datasets, respectively, and develop a novel dataset for financial audio summarization, comprising the \textsc{FinAudio} benchmark. Then, we evaluate seven prevalent AudioLLMs on \textsc{FinAudio}. Our evaluation reveals the limitations of existing AudioLLMs in the financial domain and offers insights for improving AudioLLMs. All datasets and codes will be released.