Exploiting Temporal State Space Sharing for Video Semantic Segmentation
作者: Syed Ariff Syed Hesham, Yun Liu, Guolei Sun, Henghui Ding, Jing Yang, Ender Konukoglu, Xue Geng, Xudong Jiang
分类: eess.IV, cs.AI, cs.LG
发布日期: 2025-03-26
备注: IEEE/CVF Conference on Computer Vision and Pattern Recognition 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出TV3S架构,利用时序状态空间共享提升视频语义分割性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 视频语义分割 时序建模 状态空间模型 Mamba 长视频理解
📋 核心要点
- 传统视频语义分割方法缺乏长时序上下文建模能力,计算冗余且内存需求高,限制了其在长视频上的应用。
- TV3S架构利用Mamba状态空间模型进行时序特征共享,通过选择性门控机制高效传播信息,无需大量内存的特征池。
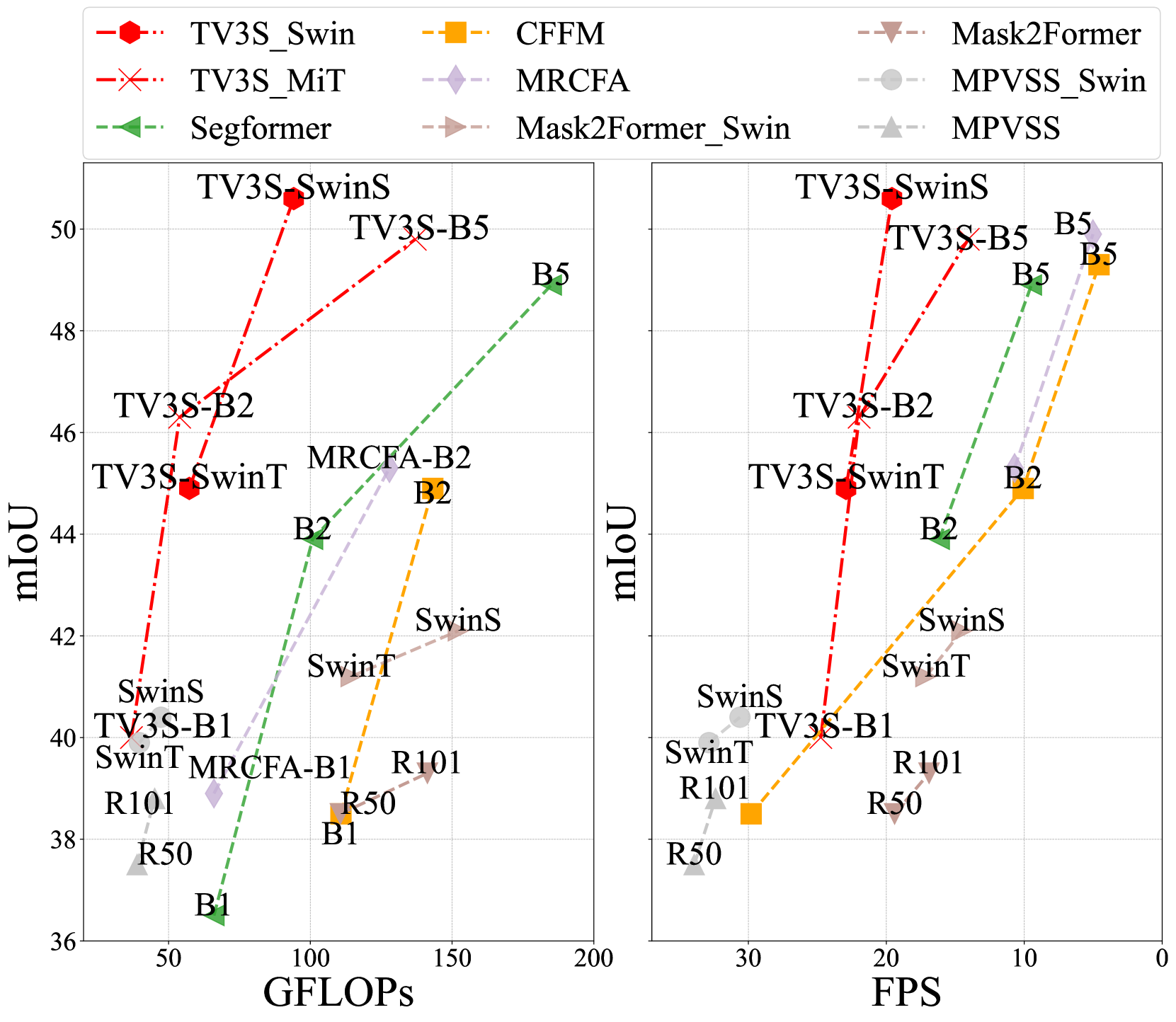
- 实验表明,TV3S在VSPW和Cityscapes数据集上超越了现有最佳方法,为长视频语义分割设立了新标准。
📝 摘要(中文)
视频语义分割(VSS)在理解场景的时序演变中起着至关重要的作用。传统方法通常逐帧或在短时窗内分割视频,导致时序上下文有限、计算冗余和内存需求大。为此,我们引入了一种时序视频状态空间共享(TV3S)架构,利用Mamba状态空间模型进行时序特征共享。我们的模型具有选择性门控机制,可以有效地在视频帧之间传播相关信息,无需占用大量内存的特征池。通过独立处理空间patch并结合移位操作,TV3S支持训练和推理阶段的高度并行计算,从而减少了顺序状态空间处理的延迟,并提高了长视频序列的可扩展性。此外,TV3S在推理过程中结合了来自先前帧的信息,实现了长程时序一致性和对扩展序列的卓越适应性。在VSPW和Cityscapes数据集上的评估表明,我们的方法优于当前最先进的方法,为VSS建立了新的标准,并在长视频序列中取得了始终如一的结果。通过在准确性和效率之间取得良好的平衡,TV3S在时空建模方面取得了显著进步,为高效视频分析铺平了道路。
🔬 方法详解
问题定义:视频语义分割旨在对视频的每一帧像素进行语义标注。现有方法主要存在三个痛点:一是缺乏对长时序信息的有效利用,通常只关注短时窗口内的信息;二是计算冗余,对每一帧或窗口内的帧进行重复计算;三是内存需求大,需要存储大量的中间特征。
核心思路:TV3S的核心思路是利用状态空间模型(特别是Mamba)来建模视频的时序依赖关系,并通过状态共享机制减少计算冗余和内存需求。通过将视频帧视为一个时序序列,状态空间模型可以学习到视频的时序动态,从而更好地进行语义分割。
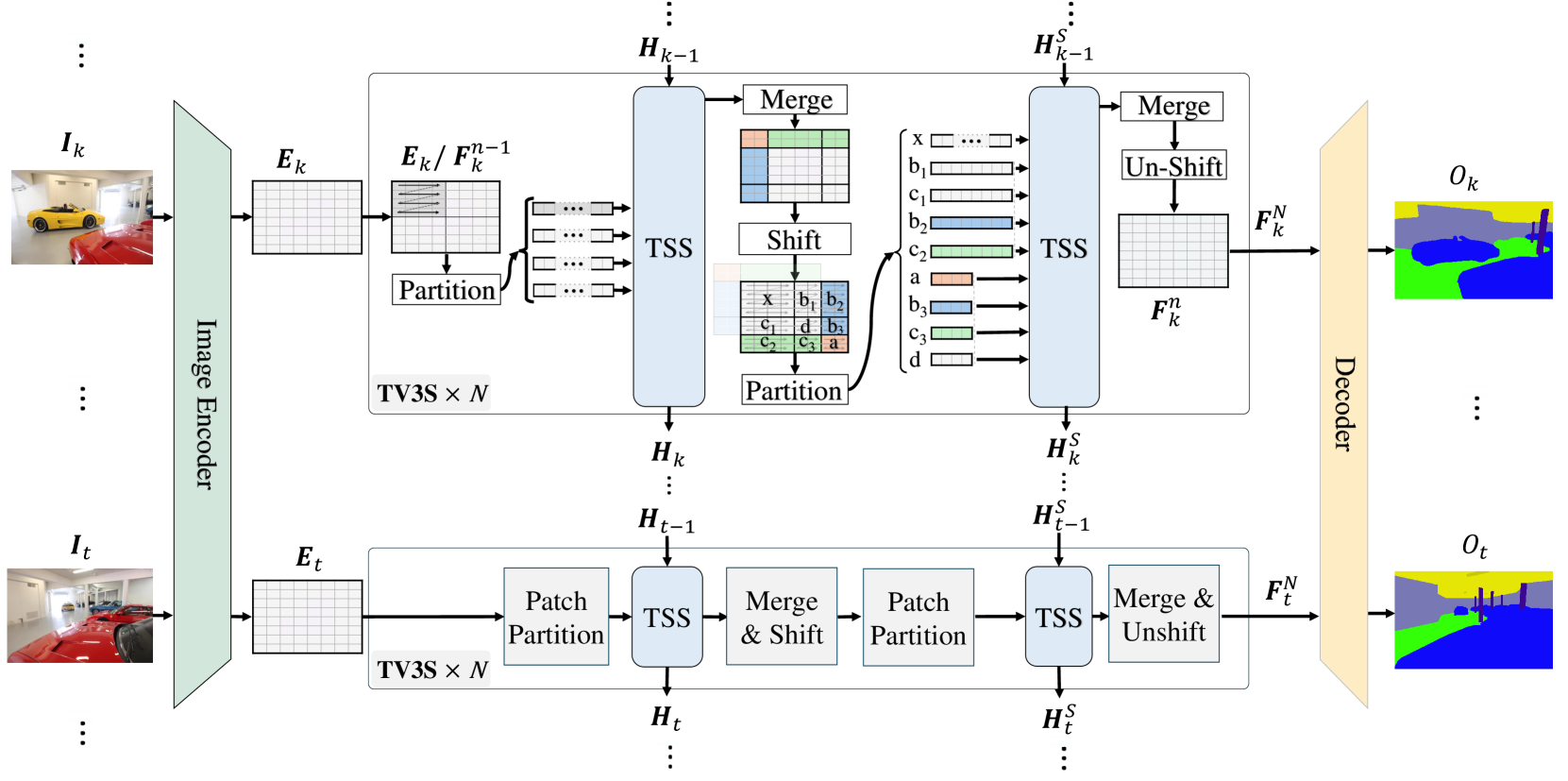
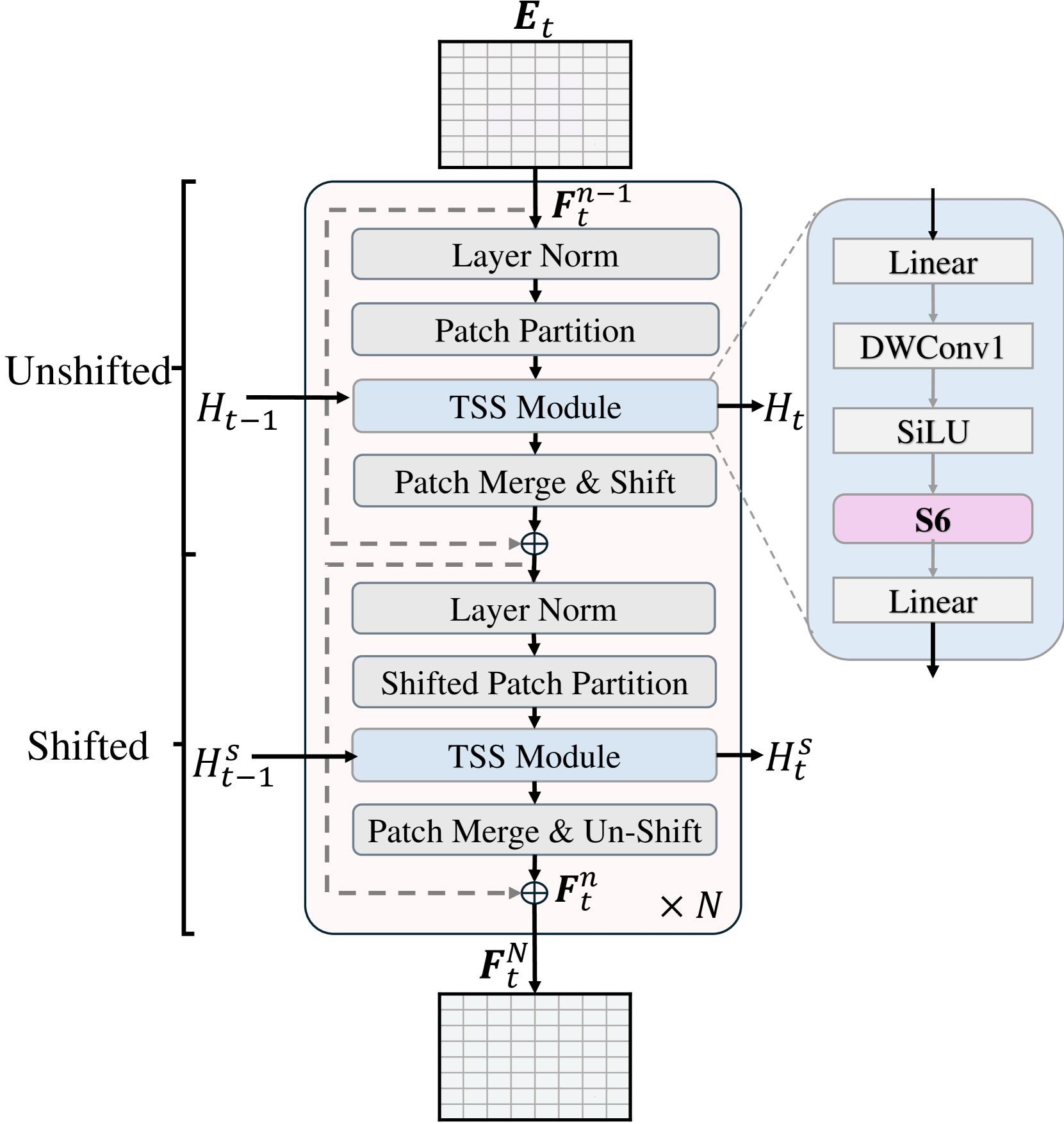
技术框架:TV3S的整体架构包括以下几个主要模块:1) 空间特征提取模块:用于提取每一帧图像的空间特征。2) 时序状态空间共享模块:利用Mamba状态空间模型对时序特征进行建模,并通过选择性门控机制控制信息的流动。3) 分类模块:基于时序特征进行像素级别的语义分类。
关键创新:TV3S的关键创新在于时序状态空间共享机制。传统的状态空间模型通常需要对每一个时间步进行独立的计算,而TV3S通过共享状态空间,减少了计算冗余。此外,选择性门控机制可以有效地控制信息的流动,避免了无关信息的干扰。
关键设计:TV3S的关键设计包括:1) 使用Mamba作为状态空间模型,Mamba具有高效的计算能力和良好的时序建模能力。2) 设计选择性门控机制,用于控制信息的流动。3) 采用独立处理空间patch并结合移位操作,支持训练和推理阶段的高度并行计算。4) 在推理阶段,利用先前帧的信息,实现长程时序一致性。
🖼️ 关键图片
📊 实验亮点
TV3S在VSPW和Cityscapes数据集上取得了显著的性能提升。在VSPW数据集上,TV3S超越了现有最佳方法,并在长视频序列中取得了始终如一的结果。在Cityscapes数据集上,TV3S也取得了具有竞争力的性能。实验结果表明,TV3S在准确性和效率之间取得了良好的平衡,为视频语义分割提供了一种新的解决方案。
🎯 应用场景
TV3S在视频监控、自动驾驶、机器人导航等领域具有广泛的应用前景。它可以用于理解视频场景中的动态变化,提高对复杂环境的感知能力。例如,在自动驾驶中,TV3S可以帮助车辆更好地理解周围环境,从而做出更安全的决策。在视频监控中,TV3S可以用于检测异常事件,提高安全防范能力。
📄 摘要(原文)
Video semantic segmentation (VSS) plays a vital role in understanding the temporal evolution of scenes. Traditional methods often segment videos frame-by-frame or in a short temporal window, leading to limited temporal context, redundant computations, and heavy memory requirements. To this end, we introduce a Temporal Video State Space Sharing (TV3S) architecture to leverage Mamba state space models for temporal feature sharing. Our model features a selective gating mechanism that efficiently propagates relevant information across video frames, eliminating the need for a memory-heavy feature pool. By processing spatial patches independently and incorporating shifted operation, TV3S supports highly parallel computation in both training and inference stages, which reduces the delay in sequential state space processing and improves the scalability for long video sequences. Moreover, TV3S incorporates information from prior frames during inference, achieving long-range temporal coherence and superior adaptability to extended sequences. Evaluations on the VSPW and Cityscapes datasets reveal that our approach outperforms current state-of-the-art methods, establishing a new standard for VSS with consistent results across long video sequences. By achieving a good balance between accuracy and efficiency, TV3S shows a significant advancement in spatiotemporal modeling, paving the way for efficient video analysis. The code is publicly available at https://github.com/Ashesham/TV3S.git.