QualiSpeech: A Speech Quality Assessment Dataset with Natural Language Reasoning and Descriptions
作者: Siyin Wang, Wenyi Yu, Xianzhao Chen, Xiaohai Tian, Jun Zhang, Lu Lu, Yu Tsao, Junichi Yamagishi, Yuxuan Wang, Chao Zhang
分类: eess.AS, cs.AI, cs.CL, cs.SD
发布日期: 2025-03-26 (更新: 2025-06-15)
备注: 22 pages, 10 figures
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
QualiSpeech:提出一种基于自然语言推理和描述的语音质量评估数据集。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音质量评估 自然语言处理 听觉大型语言模型 语音理解 数据集 推理 噪声识别
📋 核心要点
- 现有语音质量评估方法依赖数值评分,缺乏细致的反馈和推理能力。
- QualiSpeech 提出利用自然语言描述进行语音质量评估,提供更丰富的上下文信息。
- 实验表明,微调后的听觉 LLM 能够生成噪声和失真的详细描述,提升评估准确性。
📝 摘要(中文)
本文探索了一种利用自然语言描述进行语音质量评估的新视角,相比传统的数值评分方法,它提供了更丰富、更细致的见解。自然语言反馈能够提供指导性的建议和详细的评估,但现有的数据集缺乏支持这种方法所需的全面标注。为了弥补这一差距,我们推出了 QualiSpeech,这是一个全面的低级别语音质量评估数据集,涵盖了 11 个关键方面,并包含详细的自然语言评论,包括推理和上下文见解。此外,我们提出了 QualiSpeech 基准,以评估听觉大型语言模型 (LLM) 的低级别语音理解能力。实验结果表明,经过微调的听觉 LLM 可以可靠地生成噪声和失真的详细描述,有效地识别它们的类型和时间特征。结果进一步突出了结合推理来提高质量评估的准确性和可靠性的潜力。该数据集将在 https://huggingface.co/datasets/tsinghua-ee/QualiSpeech 上发布。
🔬 方法详解
问题定义:现有的语音质量评估方法主要依赖于数值评分,例如 MOS (Mean Opinion Score)。这种方法的痛点在于缺乏细致的反馈和推理能力,难以提供指导性的建议和详细的评估,无法充分理解语音质量的复杂性,例如噪声类型、失真程度以及它们的时间特性。
核心思路:论文的核心思路是利用自然语言描述来增强语音质量评估。通过提供详细的自然语言评论,包括推理和上下文信息,可以更全面地理解语音质量,并为改进语音处理系统提供更有效的指导。这种方法借鉴了人类专家评估语音质量的方式,即不仅给出评分,还会解释原因。
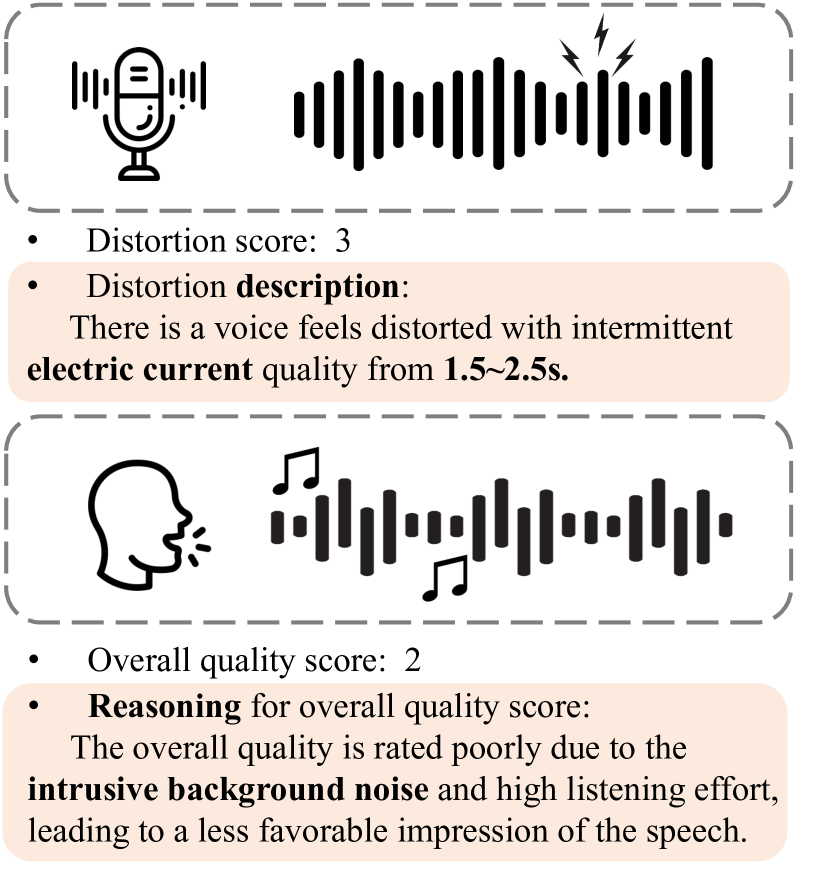
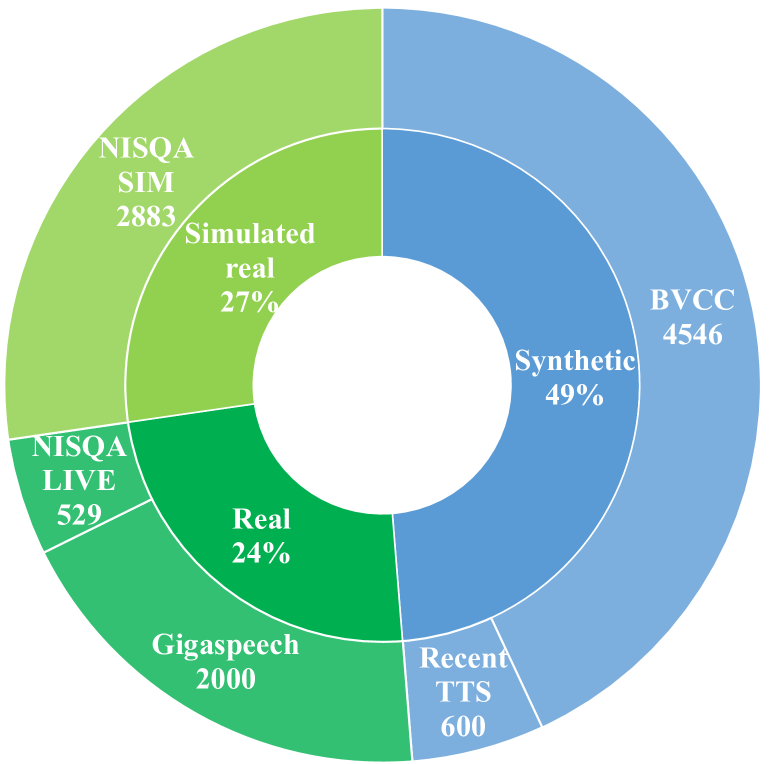
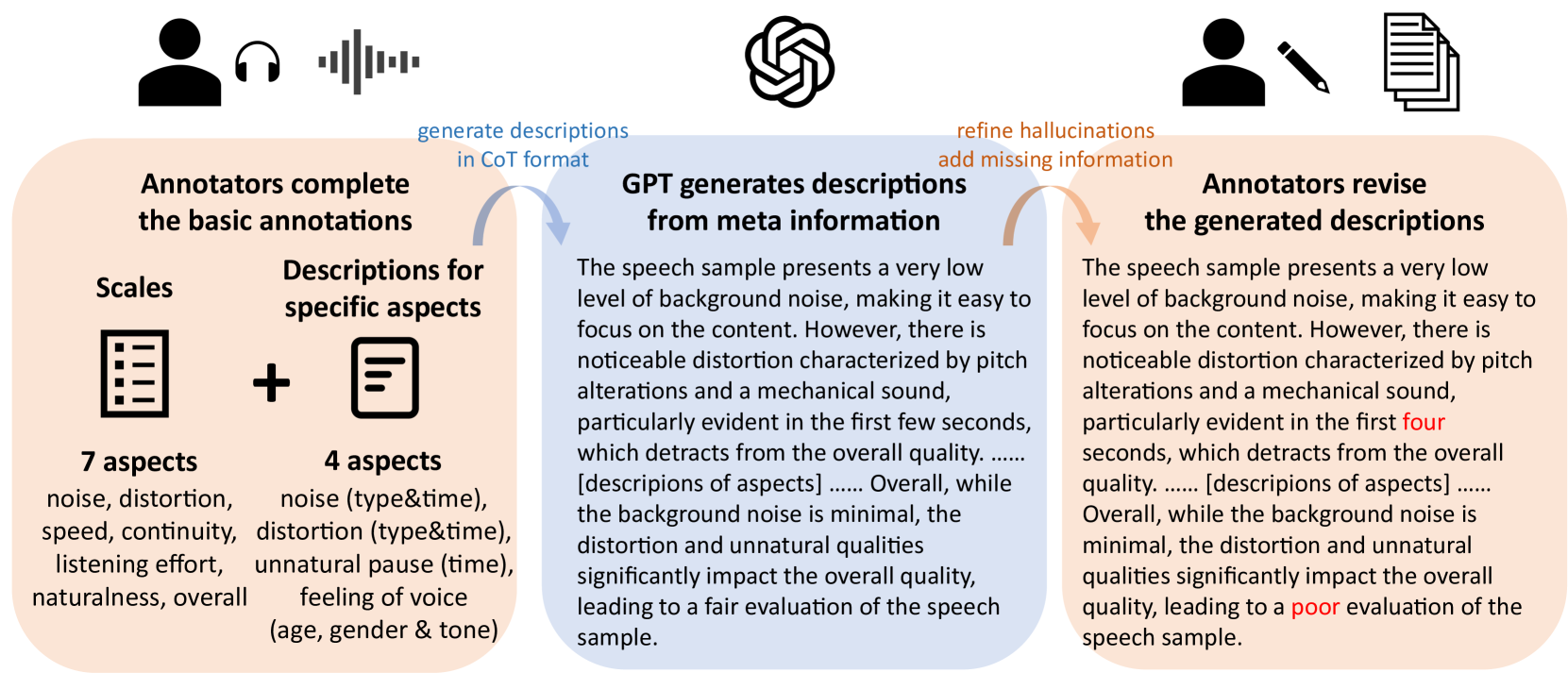
技术框架:QualiSpeech 数据集包含以下几个关键组成部分:1) 涵盖 11 个关键方面的低级别语音质量评估;2) 详细的自然语言评论,包括推理和上下文见解;3) QualiSpeech 基准,用于评估听觉大型语言模型 (LLM) 的低级别语音理解能力。研究者使用微调后的听觉 LLM 来生成噪声和失真的详细描述,并评估其识别噪声类型和时间特征的能力。
关键创新:该论文的关键创新在于引入了自然语言描述和推理到语音质量评估中。与传统的数值评分方法相比,这种方法提供了更丰富、更细致的见解,能够更全面地理解语音质量。此外,QualiSpeech 数据集的构建和 QualiSpeech 基准的提出,为听觉 LLM 的研究和应用提供了新的资源和方向。
关键设计:QualiSpeech 数据集包含了 11 个关键的语音质量评估方面,具体细节未知。研究者使用了听觉 LLM,并对其进行了微调,以生成噪声和失真的详细描述。具体的网络结构、损失函数和参数设置等技术细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,经过微调的听觉 LLM 可以可靠地生成噪声和失真的详细描述,有效地识别它们的类型和时间特征。这表明听觉 LLM 具有强大的低级别语音理解能力,并且可以通过结合推理来提高质量评估的准确性和可靠性。具体的性能数据和提升幅度在摘要中未给出。
🎯 应用场景
QualiSpeech 数据集和基准测试可以应用于语音增强、语音编码、语音合成等领域。通过利用自然语言描述进行语音质量评估,可以更有效地改进语音处理系统,提高语音通信的质量和用户体验。此外,该研究还可以促进听觉 LLM 的发展,使其能够更好地理解和处理语音信号。
📄 摘要(原文)
This paper explores a novel perspective to speech quality assessment by leveraging natural language descriptions, offering richer, more nuanced insights than traditional numerical scoring methods. Natural language feedback provides instructive recommendations and detailed evaluations, yet existing datasets lack the comprehensive annotations needed for this approach. To bridge this gap, we introduce QualiSpeech, a comprehensive low-level speech quality assessment dataset encompassing 11 key aspects and detailed natural language comments that include reasoning and contextual insights. Additionally, we propose the QualiSpeech Benchmark to evaluate the low-level speech understanding capabilities of auditory large language models (LLMs). Experimental results demonstrate that finetuned auditory LLMs can reliably generate detailed descriptions of noise and distortion, effectively identifying their types and temporal characteristics. The results further highlight the potential for incorporating reasoning to enhance the accuracy and reliability of quality assessments. The dataset will be released at https://huggingface.co/datasets/tsinghua-ee/QualiSpeech.