OAEI-LLM-T: A TBox Benchmark Dataset for Understanding Large Language Model Hallucinations in Ontology Matching
作者: Zhangcheng Qiang, Kerry Taylor, Weiqing Wang, Jing Jiang
分类: cs.AI, cs.CL, cs.IR, cs.LG
发布日期: 2025-03-25 (更新: 2025-05-14)
备注: 14 pages, 4 figures, 4 tables, 2 prompt templates
💡 一句话要点
OAEI-LLM-T:一个用于理解大型语言模型在本体匹配中幻觉现象的TBox基准数据集。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 本体匹配 幻觉 基准数据集 知识图谱 TBox OAEI
📋 核心要点
- 基于LLM的本体匹配系统面临幻觉问题,降低了匹配的准确性和可靠性,现有方法难以有效解决。
- 论文构建OAEI-LLM-T基准数据集,用于分析和理解LLM在本体匹配任务中的幻觉类型和模式。
- 该数据集可用于构建LLM在本体匹配任务中的排行榜,并为微调LLM以减少幻觉提供数据支持。
📝 摘要(中文)
大型语言模型(LLM)在下游任务中常常不可避免地出现幻觉。为了应对基于LLM的本体匹配(OM)系统解决幻觉这一重大挑战,我们引入了一个新的基准数据集OAEI-LLM-T。该数据集由本体对齐评估倡议(OAEI)中的七个TBox数据集演变而来,捕捉了十个不同LLM执行OM任务时的幻觉。这些OM特定的幻觉被组织成两个主要类别和六个子类别。我们展示了该数据集在构建OM任务的LLM排行榜以及微调用于OM任务的LLM方面的实用性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在本体匹配(OM)任务中产生的幻觉问题。现有方法在利用LLM进行OM时,由于LLM本身的局限性,容易产生不准确或不一致的匹配结果,即幻觉。这些幻觉会严重影响OM系统的性能和可靠性,阻碍LLM在知识图谱等领域的应用。
核心思路:论文的核心思路是构建一个专门用于评估和分析LLM在OM任务中幻觉现象的基准数据集OAEI-LLM-T。通过对不同LLM在OM任务中的表现进行评估,识别和分类幻觉类型,从而为开发更有效的幻觉缓解方法提供数据基础和评估标准。
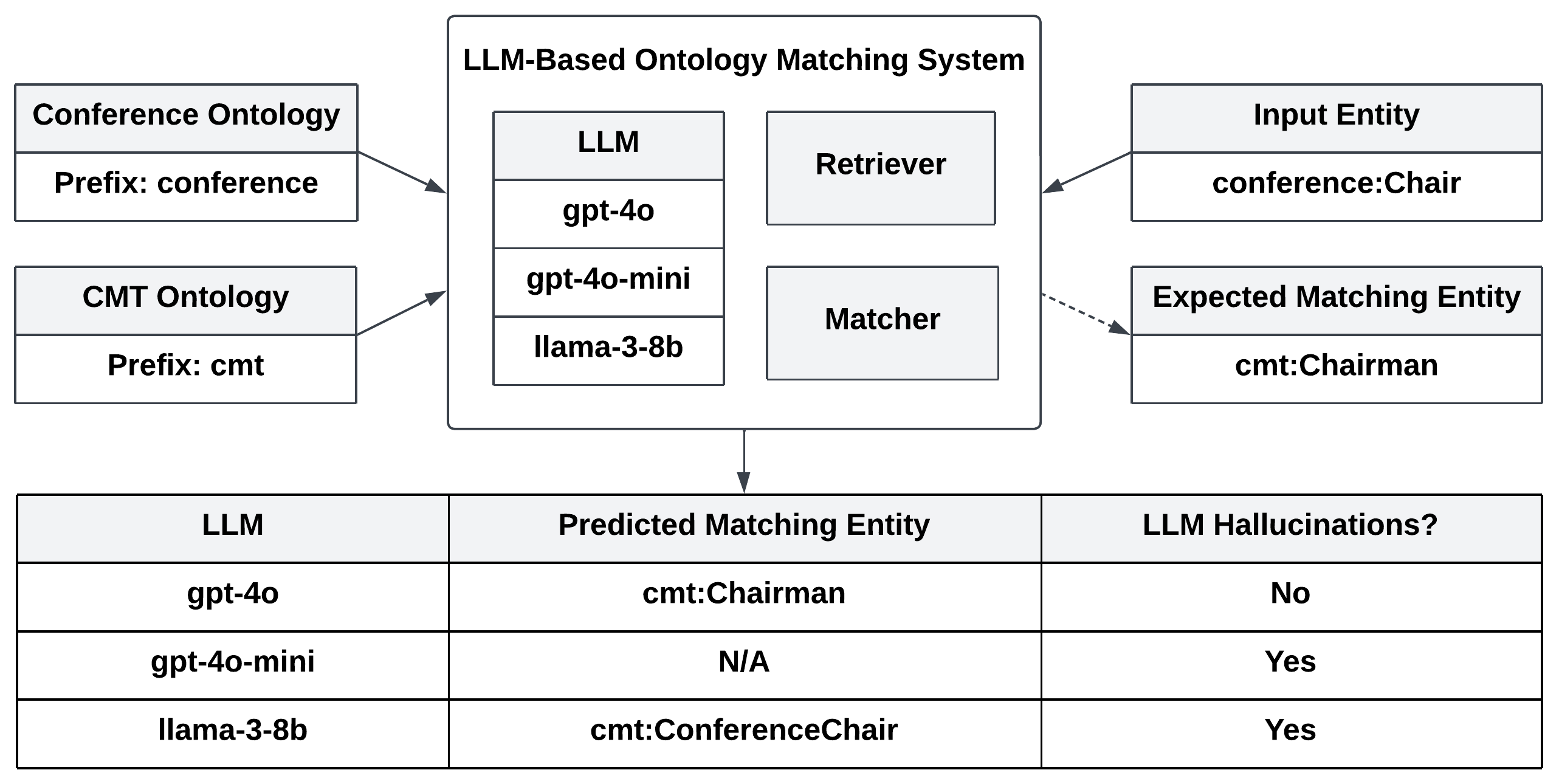
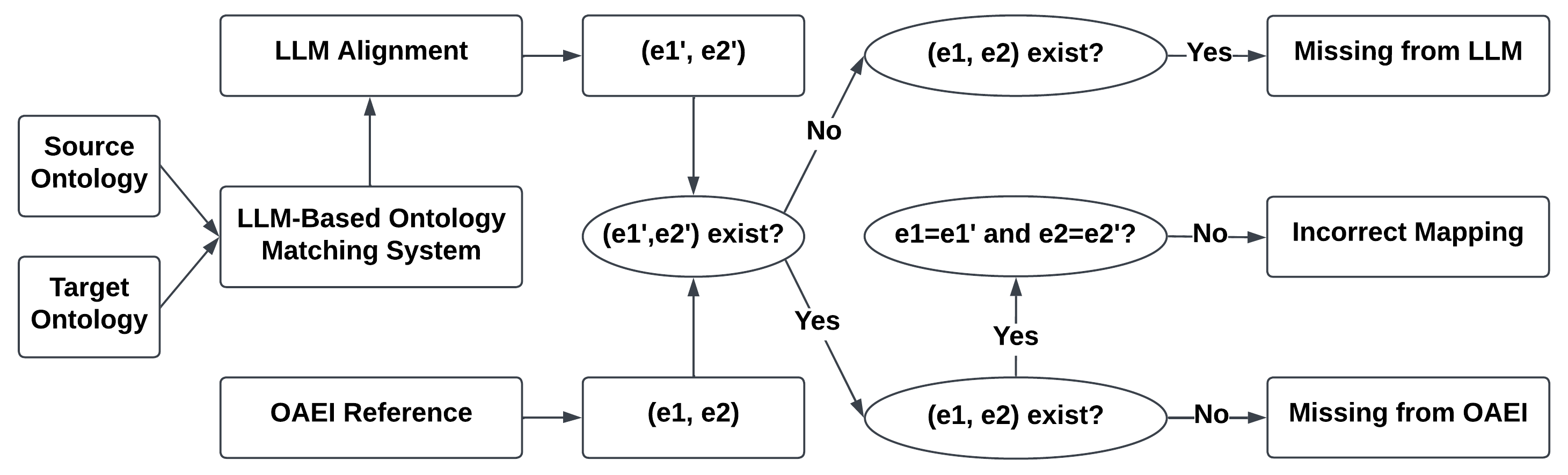
技术框架:OAEI-LLM-T数据集的构建流程主要包括以下几个步骤:1) 从OAEI的七个TBox数据集中提取本体;2) 使用十个不同的LLM执行OM任务,生成匹配结果;3) 人工分析和标注LLM生成的匹配结果,识别和分类幻觉类型;4) 将标注后的数据整理成OAEI-LLM-T数据集。该数据集将幻觉分为两个主要类别(未知和不一致)和六个子类别。
关键创新:论文的关键创新在于构建了一个专门针对LLM在本体匹配任务中幻觉现象的基准数据集。与现有的OM数据集不同,OAEI-LLM-T侧重于捕捉和分类LLM产生的幻觉,为研究人员提供了一个评估和比较不同LLM在幻觉缓解方面的性能的平台。
关键设计:OAEI-LLM-T数据集的关键设计包括:1) 基于OAEI的TBox数据集,保证了数据集的质量和多样性;2) 选择了十个具有代表性的LLM,覆盖了不同架构和规模的模型;3) 设计了清晰的幻觉分类体系,方便研究人员进行分析和比较;4) 提供了用于构建LLM排行榜和微调LLM的示例代码和工具。
🖼️ 关键图片
📊 实验亮点
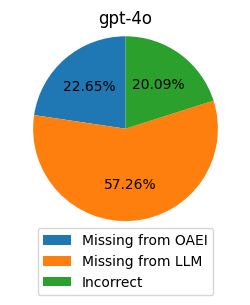
论文构建的OAEI-LLM-T数据集揭示了不同LLM在本体匹配任务中幻觉现象的差异。实验表明,该数据集可用于构建LLM在OM任务中的排行榜,并为微调LLM以减少幻觉提供数据支持。例如,通过在OAEI-LLM-T上微调LLM,可以显著降低其在OM任务中的幻觉率。
🎯 应用场景
该研究成果可应用于知识图谱构建、数据集成、语义搜索等领域。通过利用OAEI-LLM-T数据集,可以评估和改进LLM在本体匹配任务中的性能,减少幻觉,提高匹配的准确性和可靠性。这将有助于更好地利用LLM进行知识图谱的构建和维护,促进知识的共享和利用。
📄 摘要(原文)
Hallucinations are often inevitable in downstream tasks using large language models (LLMs). To tackle the substantial challenge of addressing hallucinations for LLM-based ontology matching (OM) systems, we introduce a new benchmark dataset OAEI-LLM-T. The dataset evolves from seven TBox datasets in the Ontology Alignment Evaluation Initiative (OAEI), capturing hallucinations of ten different LLMs performing OM tasks. These OM-specific hallucinations are organised into two primary categories and six sub-categories. We showcase the usefulness of the dataset in constructing an LLM leaderboard for OM tasks and for fine-tuning LLMs used in OM tasks.