Inducing Personality in LLM-Based Honeypot Agents: Measuring the Effect on Human-Like Agenda Generation
作者: Lewis Newsham, Ryan Hyland, Daniel Prince
分类: cs.AI, cs.MA
发布日期: 2025-03-25
备注: 11 pages, 1 figure, 6 tables. Accepted to NLPAICS 2024
💡 一句话要点
SANDMAN:利用LLM诱导人格的蜜罐代理,提升网络欺骗效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 网络欺骗 蜜罐 语言代理 大型语言模型 人格五因素模型 行为模拟 提示工程
📋 核心要点
- 现有网络欺骗技术难以长时间、高保真地与攻击者交互,限制了攻击行为的观察和分析。
- SANDMAN架构利用语言代理模拟具有不同人格的人类替身,通过角色驱动的行为生成,实现更逼真的交互。
- 实验表明,基于人格五因素模型的提示模式能够有效诱导LLM产生不同的人格,提升网络欺骗策略。
📝 摘要(中文)
本文提出了一种名为SANDMAN的网络欺骗架构,该架构利用语言代理来模拟逼真的人类替身。我们的“欺骗代理”作为高级网络诱饵,旨在通过延长攻击行为的观察期来实现与攻击者的高保真交互。通过实验、测量和分析,我们展示了基于人格五因素模型的提示模式如何系统地在大型语言模型中诱导出不同的“人格”。我们的结果突出了基于角色驱动的语言代理在生成多样化、真实行为方面的可行性,最终改善了网络欺骗策略。
🔬 方法详解
问题定义:当前的网络欺骗技术,例如蜜罐,在与攻击者交互时,往往缺乏真实性和持久性。攻击者容易识别出这些诱饵,从而缩短交互时间,导致无法充分观察和分析攻击行为。现有的方法难以模拟出具有复杂人格特征的人类行为,使得欺骗效果大打折扣。
核心思路:本文的核心思路是利用大型语言模型(LLM)强大的生成能力,通过精心设计的提示工程,赋予LLM不同的人格特征。这些具有特定人格的LLM代理可以模拟真实用户的行为模式,从而迷惑攻击者,延长交互时间,为安全分析提供更多信息。这种方法的核心在于将心理学中的人格模型与LLM相结合,创造出更具欺骗性的网络诱饵。
技术框架:SANDMAN架构包含以下几个主要模块:1) 人格建模模块:基于人格五因素模型(Big Five personality traits),定义不同的人格特征。2) 提示生成模块:根据定义的人格特征,生成用于引导LLM行为的提示语。3) 语言代理模块:使用LLM作为核心,接收提示语并生成相应的行为响应。4) 交互模块:负责与攻击者进行交互,并将交互数据记录下来。整个流程是:首先确定需要模拟的人格类型,然后根据该人格类型生成相应的提示语,接着将提示语输入到LLM中,LLM根据提示语生成相应的行为,最后将生成的行为呈现给攻击者。
关键创新:该论文的关键创新在于将人格五因素模型与LLM相结合,创造出具有不同人格特征的欺骗代理。这种方法能够生成更加多样化和真实的行为,从而提高网络欺骗的有效性。与传统的蜜罐技术相比,SANDMAN架构能够模拟更复杂的人类行为,使得攻击者更难识别出诱饵。
关键设计:提示工程是SANDMAN架构的关键设计之一。论文作者设计了一种基于人格五因素模型的提示模式,通过调整提示语中的关键词和语气,来控制LLM生成不同人格特征的行为。例如,对于外向型人格,提示语中会包含更多积极、社交相关的词汇;对于内向型人格,提示语则会更加谨慎、保守。此外,论文还对LLM的参数进行了微调,以进一步增强其人格模拟能力。具体的参数设置和损失函数信息未知。
🖼️ 关键图片
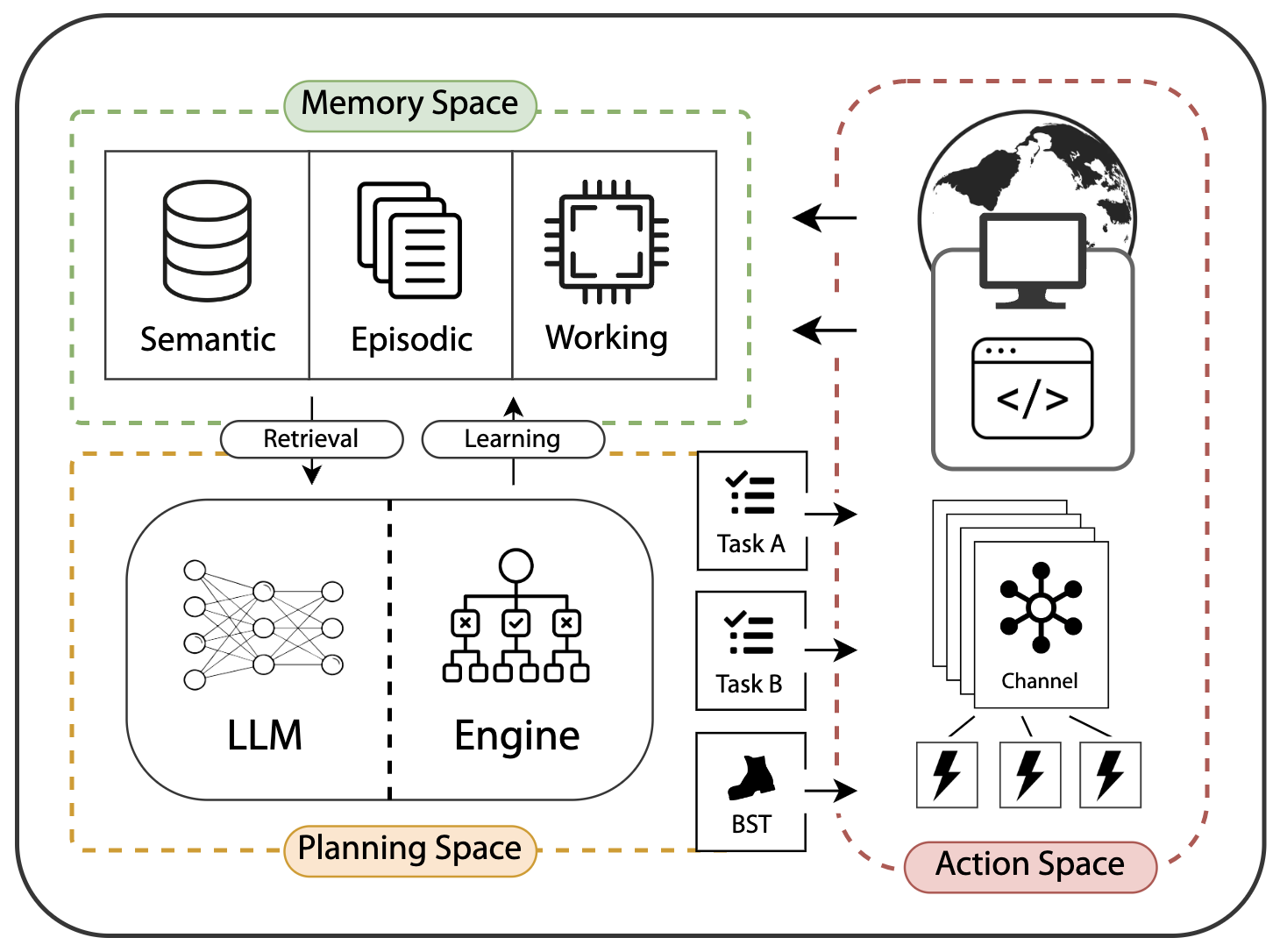
📊 实验亮点
实验结果表明,基于人格五因素模型的提示模式能够有效诱导LLM产生不同的人格特征,生成的行为更具多样性和真实性。具体性能数据未知,但论文强调了该方法在提升网络欺骗策略方面的可行性。与传统方法相比,SANDMAN架构能够更好地模拟人类行为,从而提高蜜罐的欺骗效果。
🎯 应用场景
该研究成果可应用于构建更高级的网络蜜罐系统,用于诱捕和分析恶意攻击行为。通过模拟不同类型用户的行为,可以更有效地迷惑攻击者,延长攻击周期,从而为安全分析人员提供更多有价值的情报。此外,该技术还可用于安全意识培训,模拟真实的网络攻击场景,提高用户的安全防范意识。
📄 摘要(原文)
This paper presents SANDMAN, an architecture for cyber deception that leverages Language Agents to emulate convincing human simulacra. Our 'Deceptive Agents' serve as advanced cyber decoys, designed for high-fidelity engagement with attackers by extending the observation period of attack behaviours. Through experimentation, measurement, and analysis, we demonstrate how a prompt schema based on the five-factor model of personality systematically induces distinct 'personalities' in Large Language Models. Our results highlight the feasibility of persona-driven Language Agents for generating diverse, realistic behaviours, ultimately improving cyber deception strategies.