Analyzable Chain-of-Musical-Thought Prompting for High-Fidelity Music Generation
作者: Max W. Y. Lam, Yijin Xing, Weiya You, Jingcheng Wu, Zongyu Yin, Fuqiang Jiang, Hangyu Liu, Feng Liu, Xingda Li, Wei-Tsung Lu, Hanyu Chen, Tong Feng, Tianwei Zhao, Chien-Hung Liu, Xuchen Song, Yang Li, Yahui Zhou
分类: cs.SD, cs.AI, cs.MM, eess.AS, eess.SP
发布日期: 2025-03-25
备注: Preprint
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出MusiCoT:一种可分析的音乐思维链提示方法,用于高保真音乐生成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音乐生成 思维链提示 自回归模型 CLAP模型 音乐结构分析 风格迁移 高保真音乐
📋 核心要点
- 现有自回归音乐生成模型与人类创作过程不符,影响生成音乐的连贯性和音乐性。
- MusiCoT通过思维链提示,先生成音乐结构概要,再生成音频token,提升音乐的连贯性和创造性。
- MusiCoT利用CLAP模型建立音乐思想链,无需人工标注数据,并支持音乐结构分析和风格参考。
📝 摘要(中文)
自回归(AR)模型在生成高保真音乐方面表现出令人印象深刻的能力。然而,AR模型中传统的下一个token预测范式与人类音乐创作过程不一致,可能会影响生成样本的音乐性。为了克服这个限制,我们引入了MusiCoT,一种为音乐生成量身定制的新型思维链(CoT)提示技术。MusiCoT使AR模型能够在生成音频token之前首先概述整体音乐结构,从而增强了生成作品的连贯性和创造性。通过利用对比语言-音频预训练(CLAP)模型,我们建立了一个“音乐思想”链,使MusiCoT具有可扩展性,并且独立于人工标注数据,这与传统的CoT方法不同。此外,MusiCoT允许对音乐结构进行深入分析,例如乐器编排,并支持音乐参考——接受可变长度的音频输入作为可选的风格参考。这种创新方法有效地解决了复制问题,使MusiCoT成为音乐提示的一个重要的实用方法。我们的实验结果表明,MusiCoT在客观和主观指标上始终取得优异的性能,产生可与最先进的生成模型相媲美的音乐质量。
🔬 方法详解
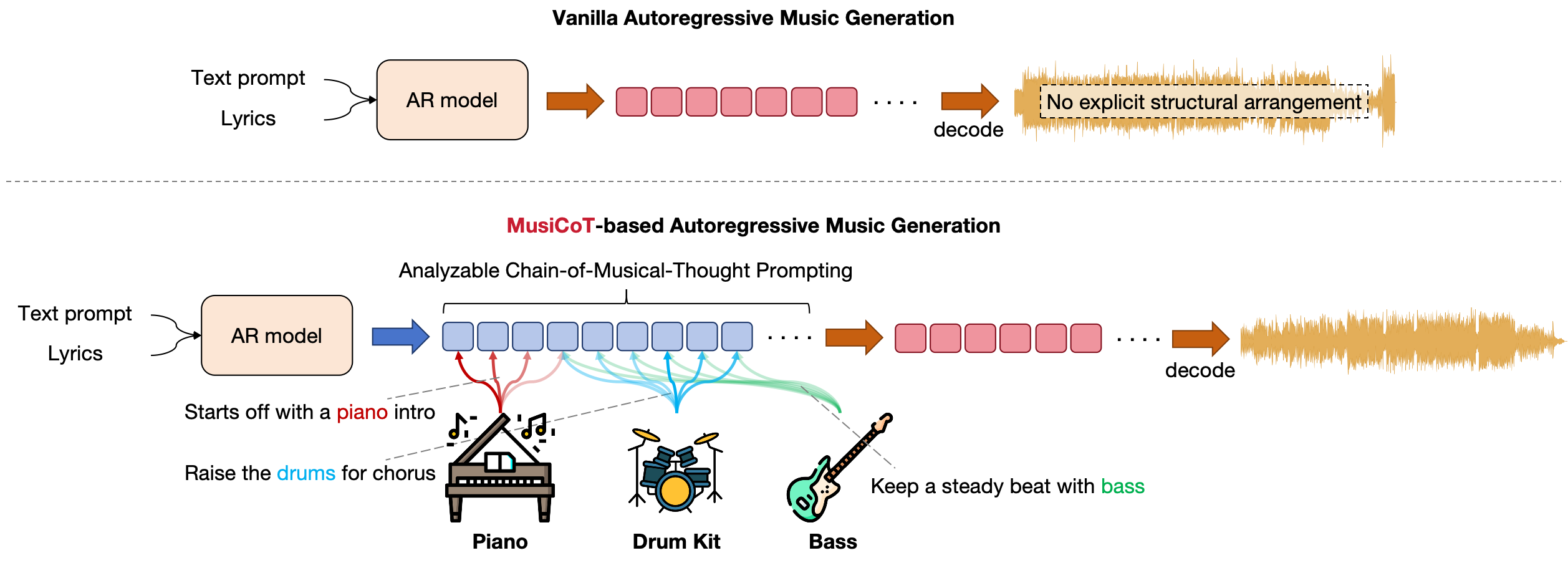
问题定义:论文旨在解决自回归音乐生成模型中,传统的token预测方式与人类音乐创作过程不一致的问题。这种不一致导致生成的音乐缺乏连贯性和创造性,难以达到高保真音乐的水平。现有方法难以对音乐的整体结构进行建模,并且容易出现复制问题。
核心思路:论文的核心思路是引入思维链(Chain-of-Thought, CoT)提示技术,让模型在生成音频token之前,先生成一个音乐结构的概要。这样,模型可以更好地理解音乐的整体结构,从而生成更连贯、更具创造性的音乐。通过模仿人类作曲家先构思整体框架再填充细节的过程,提高生成音乐的质量。
技术框架:MusiCoT的技术框架主要包含以下几个阶段:1) 音乐结构概要生成:利用CoT提示,模型首先生成音乐的整体结构,例如乐器编排、和弦进行等。2) 音频token生成:基于生成的音乐结构概要,模型逐步生成音频token,填充音乐的细节。3) 风格参考(可选):MusiCoT支持接受可变长度的音频输入作为风格参考,从而影响生成音乐的风格。4) CLAP模型辅助:利用对比语言-音频预训练(CLAP)模型,建立“音乐思想”链,用于指导音乐结构概要的生成。
关键创新:MusiCoT最重要的技术创新点在于将思维链提示技术应用于音乐生成领域,并利用CLAP模型建立可分析的音乐思想链。与传统的CoT方法不同,MusiCoT无需人工标注数据,而是通过CLAP模型自动提取音乐特征,从而实现可扩展性和灵活性。此外,MusiCoT还支持音乐结构分析和风格参考,进一步提升了生成音乐的质量和可控性。
关键设计:MusiCoT的关键设计包括:1) CoT提示的设计:如何有效地提示模型生成有意义的音乐结构概要。2) CLAP模型的应用:如何利用CLAP模型提取音乐特征,并将其融入到音乐生成过程中。3) 风格参考的实现:如何将可变长度的音频输入作为风格参考,并影响生成音乐的风格。具体的参数设置、损失函数和网络结构等细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,MusiCoT在客观和主观指标上均优于现有音乐生成模型。具体而言,MusiCoT生成的音乐在音乐性、连贯性和创造性方面都得到了显著提升。主观评价结果显示,MusiCoT生成的音乐质量可以与最先进的生成模型相媲美。论文提供了在线demo,展示了MusiCoT的强大生成能力。
🎯 应用场景
MusiCoT在音乐创作、音乐教育、游戏开发、广告制作等领域具有广泛的应用前景。它可以帮助音乐家快速生成音乐原型,为音乐教育提供个性化的学习资源,为游戏和广告提供定制化的背景音乐,甚至可以用于音乐治疗。MusiCoT的出现有望降低音乐创作的门槛,促进音乐产业的创新。
📄 摘要(原文)
Autoregressive (AR) models have demonstrated impressive capabilities in generating high-fidelity music. However, the conventional next-token prediction paradigm in AR models does not align with the human creative process in music composition, potentially compromising the musicality of generated samples. To overcome this limitation, we introduce MusiCoT, a novel chain-of-thought (CoT) prompting technique tailored for music generation. MusiCoT empowers the AR model to first outline an overall music structure before generating audio tokens, thereby enhancing the coherence and creativity of the resulting compositions. By leveraging the contrastive language-audio pretraining (CLAP) model, we establish a chain of "musical thoughts", making MusiCoT scalable and independent of human-labeled data, in contrast to conventional CoT methods. Moreover, MusiCoT allows for in-depth analysis of music structure, such as instrumental arrangements, and supports music referencing -- accepting variable-length audio inputs as optional style references. This innovative approach effectively addresses copying issues, positioning MusiCoT as a vital practical method for music prompting. Our experimental results indicate that MusiCoT consistently achieves superior performance across both objective and subjective metrics, producing music quality that rivals state-of-the-art generation models. Our samples are available at https://MusiCoT.github.io/.