Innate Reasoning is Not Enough: In-Context Learning Enhances Reasoning Large Language Models with Less Overthinking
作者: Yuyao Ge, Shenghua Liu, Yiwei Wang, Lingrui Mei, Lizhe Chen, Baolong Bi, Xueqi Cheng
分类: cs.AI
发布日期: 2025-03-25
💡 一句话要点
上下文学习增强推理大语言模型,减少过度思考
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推理大语言模型 思维链提示 上下文学习 数学推理 过度思考 注意力机制
📋 核心要点
- 现有推理大语言模型(RLLM)过度依赖内在推理能力,可能导致过度思考和性能瓶颈。
- 该研究探索了思维链(CoT)提示对RLLM的影响,旨在通过外部指导优化其推理过程。
- 实验表明,CoT提示能显著提升RLLM在数学推理任务中的性能,并有效控制思考token和推理步骤。
📝 摘要(中文)
大型语言模型(LLM)的最新进展引入了推理大型语言模型(RLLM),它采用扩展的思考过程,具有反思和自我纠正能力,展示了测试时扩展的有效性。RLLM表现出从训练中获得的内在思维链(CoT)推理能力,从而引出一个自然的问题:“CoT提示,一种流行的聊天LLM的上下文学习(ICL)方法,是否需要增强RLLM的推理能力?” 在这项工作中,我们首次全面分析了零样本CoT和少样本CoT对RLLM在数学推理任务中的影响。我们检查了参数范围从1.5B到32B的模型,发现与担忧相反,CoT提示在大多数情况下显着提高了RLLM的性能。我们的结果揭示了不同的模式:大容量模型在简单任务上的改进最小,但在复杂问题上获得了显着收益,而较小的模型则表现出相反的行为。进一步的分析表明,CoT提示有效地控制了思考token和推理步骤数量的分布,在某些情况下将过度反思减少了约90%。此外,注意力logits分析揭示了RLLM对与反思相关的词的过度拟合,而外部CoT指导可以缓解这种情况。值得注意的是,我们的实验表明,对于RLLM,单样本CoT始终优于少样本CoT方法。我们的发现为通过适当的提示策略优化RLLM的性能提供了重要的见解。
🔬 方法详解
问题定义:论文旨在解决RLLM在推理过程中过度依赖内在推理能力,导致在某些任务上表现不佳的问题。现有方法,即完全依赖RLLM自身训练获得的推理能力,可能导致过度思考,尤其是在简单任务上,从而影响效率和准确性。
核心思路:论文的核心思路是通过引入上下文学习中的思维链(CoT)提示,为RLLM提供外部指导,从而优化其推理过程。CoT提示通过提供中间推理步骤的示例,帮助RLLM更好地组织和控制其思考过程,减少过度反思,并提高推理的准确性。
技术框架:该研究的技术框架主要包括以下几个步骤:首先,选择不同规模的RLLM(1.5B到32B参数)作为研究对象。其次,在数学推理任务上,分别使用零样本CoT和少样本CoT提示对RLLM进行测试。然后,分析RLLM在不同提示下的性能表现,包括准确率、思考token数量和推理步骤数量。最后,通过注意力logits分析,研究RLLM对反思相关词汇的过度拟合情况,以及CoT提示对这种过度拟合的缓解作用。
关键创新:该研究的关键创新在于首次全面分析了CoT提示对RLLM的影响,并揭示了CoT提示在控制RLLM思考过程、减少过度反思方面的作用。此外,研究还发现单样本CoT在RLLM上通常优于少样本CoT,这与传统LLM的经验有所不同。
关键设计:研究中关键的设计包括:1) 选择具有代表性的数学推理任务作为评估基准;2) 设计零样本CoT和少样本CoT提示,并控制提示的质量和数量;3) 使用准确率、思考token数量和推理步骤数量等指标来全面评估RLLM的性能;4) 通过注意力logits分析,深入了解RLLM的内部运作机制。
🖼️ 关键图片

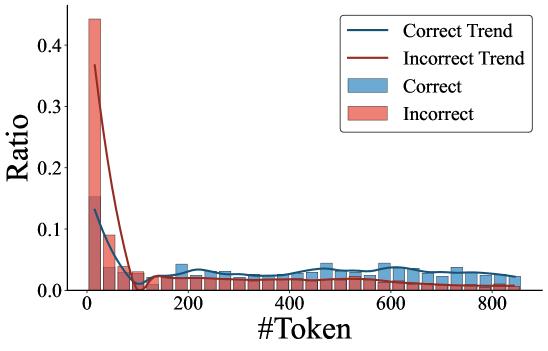
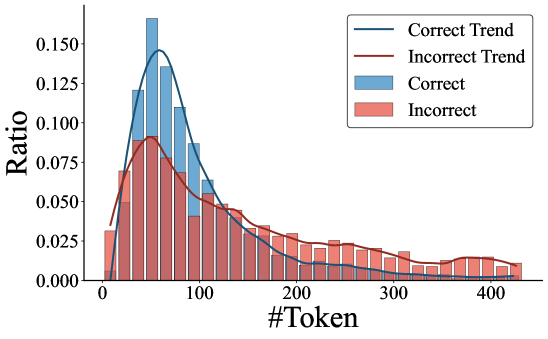
📊 实验亮点
实验结果表明,CoT提示显著提升了RLLM在数学推理任务中的性能。例如,在复杂问题上,大容量模型通过CoT提示获得了显著的性能提升;CoT提示还能有效控制思考token和推理步骤的数量,在某些情况下将过度反思减少了约90%。此外,研究发现单样本CoT通常优于少样本CoT。
🎯 应用场景
该研究成果可应用于各种需要复杂推理能力的场景,例如智能客服、金融分析、科学研究等。通过优化RLLM的推理过程,可以提高这些应用场景的效率和准确性,并降低计算成本。未来,该研究可以扩展到其他类型的推理任务和语言模型,为构建更智能、更可靠的人工智能系统提供理论指导。
📄 摘要(原文)
Recent advances in Large Language Models (LLMs) have introduced Reasoning Large Language Models (RLLMs), which employ extended thinking processes with reflection and self-correction capabilities, demonstrating the effectiveness of test-time scaling. RLLMs exhibit innate Chain-of-Thought (CoT) reasoning capability obtained from training, leading to a natural question: "Is CoT prompting, a popular In-Context Learning (ICL) method for chat LLMs, necessary to enhance the reasoning capability of RLLMs?" In this work, we present the first comprehensive analysis of the impacts of Zero-shot CoT and Few-shot CoT on RLLMs across mathematical reasoning tasks. We examine models ranging from 1.5B to 32B parameters, finding that contrary to concerns, CoT prompting significantly enhances RLLMs' performance in most scenarios. Our results reveal distinct patterns: large-capacity models show minimal improvement on simple tasks but substantial gains on complex problems, while smaller models exhibit the opposite behavior. Further analysis demonstrates that CoT prompting effectively controls the distribution of the numbers of thinking tokens and reasoning steps, reducing excessive reflections by approximately 90% in some cases. Moreover, attention logits analysis reveals the RLLMs' overfitting to reflection-related words, which is mitigated by external CoT guidance. Notably, our experiments indicate that for RLLMs, one-shot CoT consistently yields superior performance compared to Few-shot CoT approaches. Our findings provide important insights for optimizing RLLMs' performance through appropriate prompting strategies.