Fundamental Safety-Capability Trade-offs in Fine-tuning Large Language Models
作者: Pin-Yu Chen, Han Shen, Payel Das, Tianyi Chen
分类: stat.ML, cs.AI, cs.CL, cs.LG
发布日期: 2025-03-24
备注: The first two authors contribute equally to this work and are listed in alphabetical order
💡 一句话要点
理论分析揭示LLM微调中安全性和能力之间的根本性权衡
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 微调 安全性 能力 安全-能力权衡
📋 核心要点
- 现有LLM微调方法在提升模型能力的同时,往往会降低模型的安全性,造成安全-能力权衡问题。
- 论文构建理论框架,分析数据相似性、上下文重叠和对齐损失景观对安全-能力权衡的影响。
- 理论结果揭示了LLM微调中安全-能力权衡的根本限制,并通过数值实验验证了理论的有效性。
📝 摘要(中文)
在大语言模型(LLM)上针对特定任务数据集进行微调是LLM的主要应用方式。然而,经验观察表明,这种增强能力的方法不可避免地会损害安全性,这种现象也被称为LLM微调中的安全-能力权衡。本文提出了一个理论框架,用于理解两种主要的安全性感知LLM微调策略中安全性和能力之间的相互作用,从而为数据相似性、上下文重叠和对齐损失景观的影响提供了新的见解。我们的理论结果描述了LLM微调中安全-能力权衡的根本限制,这些限制也通过数值实验得到了验证。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLM)微调过程中出现的安全性和能力之间的权衡问题。现有方法在追求模型能力提升时,往往忽略了安全性,导致模型可能产生有害或不当的输出。这种现象限制了LLM在实际应用中的可靠性和安全性。
核心思路:论文的核心思路是通过建立理论模型,分析影响安全性和能力的关键因素,从而理解安全-能力权衡的根本原因。通过理论分析,可以指导LLM微调策略的设计,在保证安全性的前提下,尽可能提升模型的能力。
技术框架:论文构建了一个理论框架,用于分析两种主要的安全性感知LLM微调策略。该框架考虑了以下几个关键因素:数据相似性(训练数据与安全数据的相似程度)、上下文重叠(训练数据中上下文的重叠程度)和对齐损失景观(对齐损失函数的性质)。通过分析这些因素对模型安全性和能力的影响,可以推导出安全-能力权衡的理论界限。
关键创新:论文最重要的创新在于提出了一个理论框架,用于理解LLM微调中安全性和能力之间的权衡。与以往的经验性研究不同,该框架提供了一个理论基础,可以解释为什么在微调过程中安全性和能力会相互制约。此外,该框架还揭示了数据相似性、上下文重叠和对齐损失景观等因素对安全-能力权衡的影响。
关键设计:论文中涉及的关键设计包括:1) 对数据相似性和上下文重叠的量化方法,用于衡量训练数据与安全数据之间的差异;2) 对对齐损失景观的建模,用于分析损失函数的性质对模型安全性的影响;3) 基于理论分析,推导出安全-能力权衡的理论界限,为LLM微调策略的设计提供指导。
🖼️ 关键图片
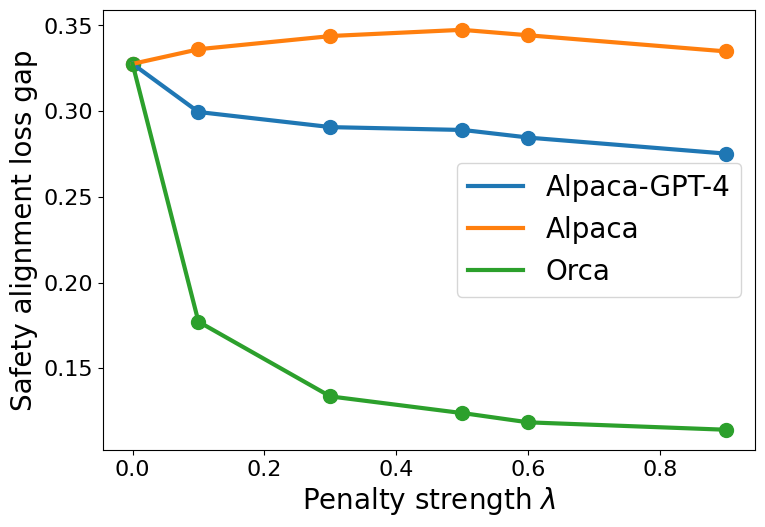
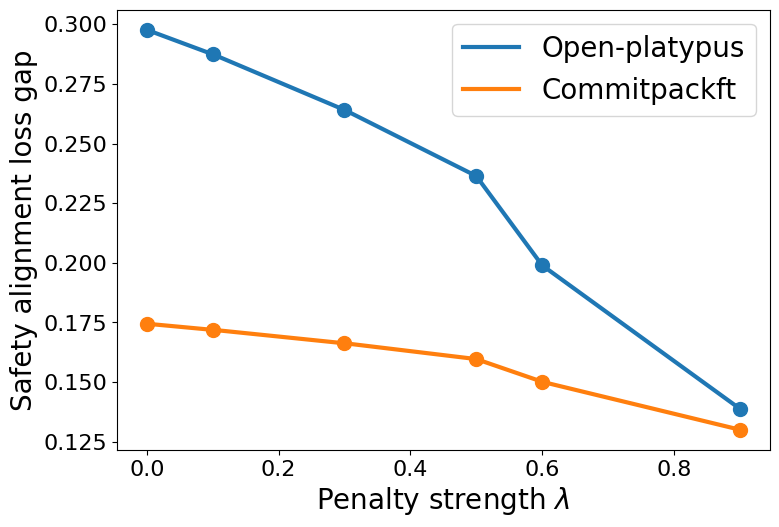

📊 实验亮点
论文通过理论分析和数值实验,验证了LLM微调中安全性和能力之间的权衡关系。实验结果表明,在提升模型能力的同时,模型的安全性会受到损害。此外,实验还验证了数据相似性、上下文重叠和对齐损失景观等因素对安全-能力权衡的影响。这些实验结果为LLM微调策略的设计提供了重要的参考依据。
🎯 应用场景
该研究成果可应用于各种需要安全可靠的大语言模型应用场景,例如智能客服、内容生成、教育辅导等。通过理解安全-能力权衡的根本原因,可以设计更有效的微调策略,在保证模型安全性的前提下,提升模型的能力,从而提高LLM在实际应用中的价值和可靠性。未来的研究可以进一步探索更复杂的微调策略和更精细的安全评估方法。
📄 摘要(原文)
Fine-tuning Large Language Models (LLMs) on some task-specific datasets has been a primary use of LLMs. However, it has been empirically observed that this approach to enhancing capability inevitably compromises safety, a phenomenon also known as the safety-capability trade-off in LLM fine-tuning. This paper presents a theoretical framework for understanding the interplay between safety and capability in two primary safety-aware LLM fine-tuning strategies, providing new insights into the effects of data similarity, context overlap, and alignment loss landscape. Our theoretical results characterize the fundamental limits of the safety-capability trade-off in LLM fine-tuning, which are also validated by numerical experiments.