BitDecoding: Unlocking Tensor Cores for Long-Context LLMs with Low-Bit KV Cache
作者: Dayou Du, Shijie Cao, Jianyi Cheng, Luo Mai, Ting Cao, Mao Yang
分类: cs.AR, cs.AI, cs.CL, cs.PF
发布日期: 2025-03-24 (更新: 2026-01-05)
🔗 代码/项目: GITHUB
💡 一句话要点
BitDecoding:利用Tensor Core加速低比特KV缓存长文本LLM推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低比特量化 KV缓存 Tensor Core 长文本LLM 推理加速
📋 核心要点
- 长文本LLM推理面临KV缓存带来的内存和带宽瓶颈,现有低比特量化方案未能充分利用GPU上的Tensor Core。
- BitDecoding通过CUDA核心和Tensor Core协同工作,优化数据布局和反量化过程,实现低比特KV缓存的高效解码。
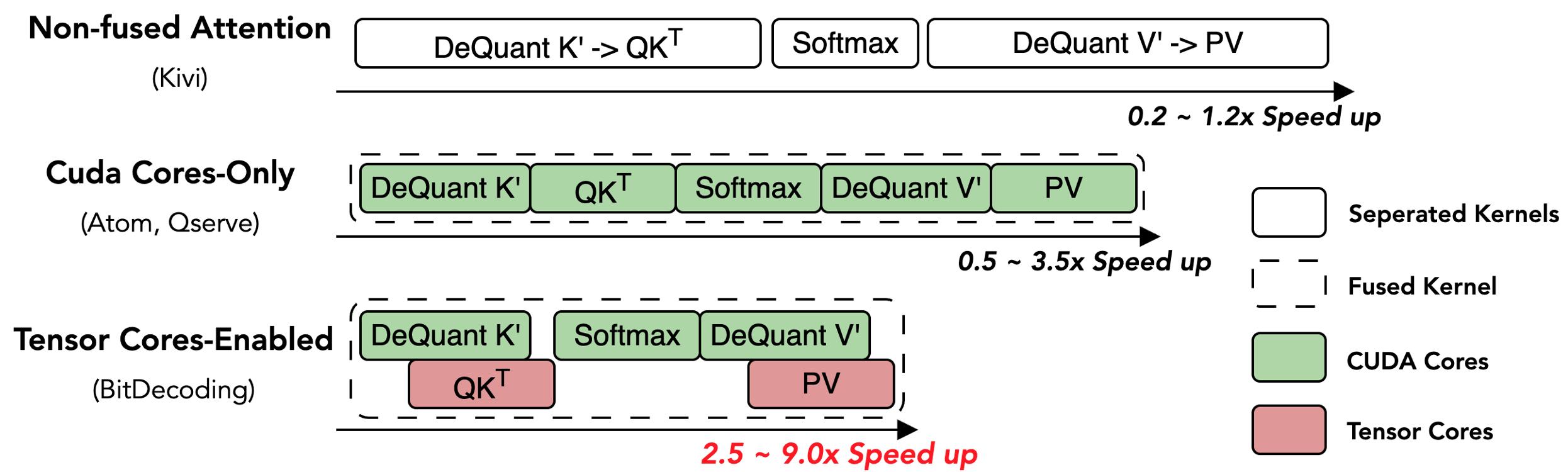
- 实验表明,BitDecoding在多种GPU架构上实现了显著的解码加速,最高可达8.6倍,并降低了长文本推理延迟。
📝 摘要(中文)
长文本大型语言模型(LLM)的增长显著增加了自回归解码期间的内存和带宽压力,这是由于不断扩展的键值(KV)缓存造成的。虽然保持精度的KV缓存量化(例如,4比特或2比特)减少了内存占用,但现有系统仅依赖CUDA核心进行解码,效率低下,未能充分利用Tensor Core——GPU上的主要计算资源。我们提出了BitDecoding,这是第一个通过协同利用CUDA核心和Tensor Core来有效解码低比特KV缓存的推理系统。BitDecoding巧妙地引入了Tensor Core友好的布局,引入了warp级反量化并行性,并通过查询转换、高性能张量和通道级量化以及支持混合精度执行的软件流水线反量化内核,提供了统一的系统支持。架构感知优化进一步利用了Hopper的warpgroup张量指令和Blackwell的NVFP4 (MXFP4)张量格式。在Blackwell、Hopper和Ampere GPU上进行评估,BitDecoding实现了比FP16 FlashDecoding-v2平均7.5倍的解码加速,在Blackwell上使用NVFP4时高达8.6倍,比最先进的方法高达4.3倍。在使用128K上下文的LLaMA-3.1-8B上,BitDecoding将单批解码延迟降低了3倍。BitDecoding已在https://github.com/OpenBitSys/BitDecoding上开源。
🔬 方法详解
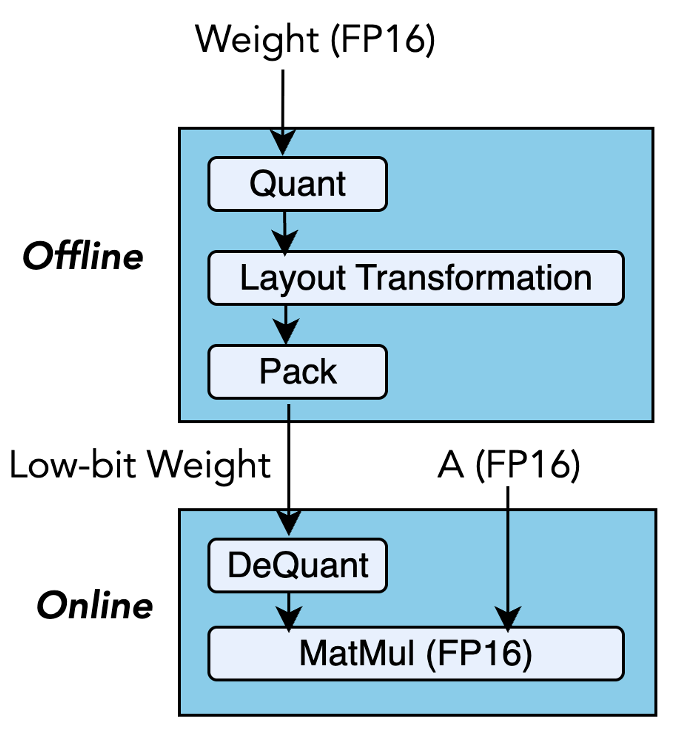
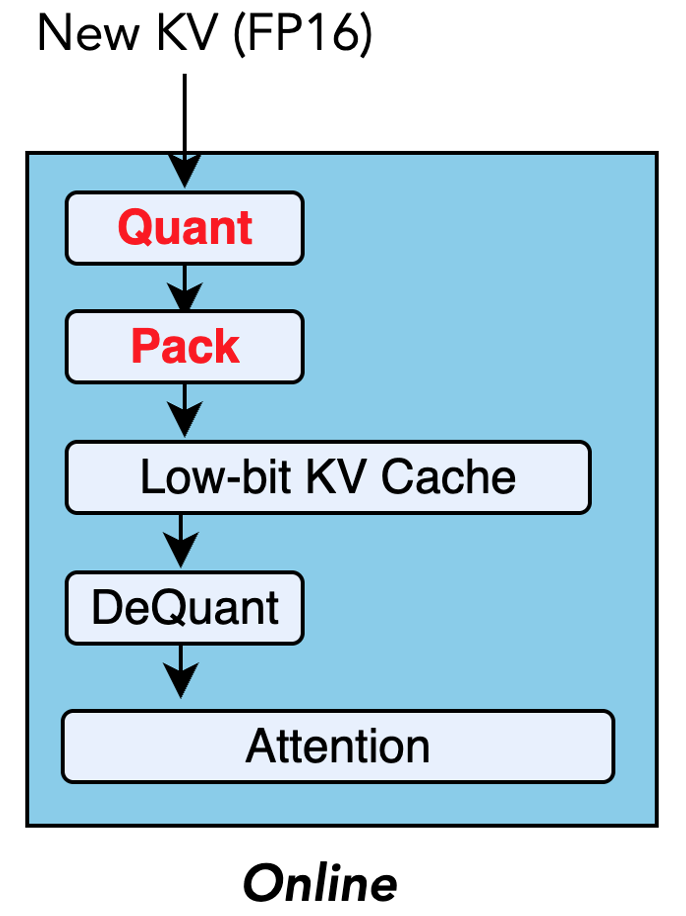
问题定义:长文本LLM推理过程中,KV缓存的内存占用和带宽需求随上下文长度线性增长,成为性能瓶颈。现有的低比特量化方法虽然能降低内存占用,但主要依赖CUDA核心进行解码,无法充分利用GPU上强大的Tensor Core计算能力,导致效率低下。
核心思路:BitDecoding的核心思路是充分利用GPU上的Tensor Core加速低比特KV缓存的解码过程。通过精心设计的数据布局和反量化策略,使低比特数据能够高效地在Tensor Core上进行计算,从而提高整体推理性能。
技术框架:BitDecoding的整体框架包括以下几个主要模块:1) 查询转换模块,用于将查询向量转换为适合Tensor Core计算的格式;2) 高性能张量和通道级量化模块,用于将KV缓存量化为低比特表示;3) 软件流水线反量化内核,用于在CUDA核心和Tensor Core之间高效地进行数据反量化和计算;4) 架构感知优化模块,针对不同的GPU架构进行优化,例如利用Hopper的warpgroup张量指令和Blackwell的NVFP4格式。
关键创新:BitDecoding的关键创新在于:1) 提出了Tensor Core友好的数据布局,使得低比特数据能够高效地在Tensor Core上进行矩阵乘法等计算;2) 引入了warp级反量化并行性,充分利用CUDA核心的并行计算能力,加速反量化过程;3) 设计了软件流水线反量化内核,实现了CUDA核心和Tensor Core之间的协同计算,提高了整体推理效率。
关键设计:BitDecoding的关键设计包括:1) 针对不同GPU架构选择合适的量化方案,例如在Blackwell GPU上使用NVFP4格式;2) 优化数据在CUDA核心和Tensor Core之间的传输,减少数据拷贝开销;3) 精心调整warp级反量化并行度,以充分利用CUDA核心的计算资源。
🖼️ 关键图片
📊 实验亮点
BitDecoding在Blackwell、Hopper和Ampere GPU上进行了评估,相比于FP16 FlashDecoding-v2,平均解码速度提升了7.5倍,在Blackwell GPU上使用NVFP4格式时,提升高达8.6倍。与现有最佳方法相比,BitDecoding也实现了高达4.3倍的加速。在使用128K上下文的LLaMA-3.1-8B模型上,BitDecoding将单批解码延迟降低了3倍。
🎯 应用场景
BitDecoding可广泛应用于需要处理长文本的LLM推理场景,例如长篇文档摘要、对话系统、代码生成等。通过降低内存占用和提高推理速度,BitDecoding能够支持更大规模的模型和更长的上下文长度,从而提升LLM在各种应用中的性能和用户体验。该技术还有助于在资源受限的设备上部署大型语言模型。
📄 摘要(原文)
The growth of long-context Large Language Models (LLMs) significantly increases memory and bandwidth pressure during autoregressive decoding due to the expanding Key-Value (KV) cache. While accuracy-preserving KV-cache quantization (e.g., 4-bit or 2-bit) reduces memory footprint, existing systems decode inefficiently by relying solely on CUDA cores, underutilizing Tensor Cores-the dominant compute resource on GPUs. We present BitDecoding, the first inference system to efficiently decode low-bit KV caches by cooperatively leveraging CUDA cores and Tensor Cores. BitDecoding smartly induces Tensor-Core-friendly layouts, introduces warp-level dequantization parallelism, and provides unified system support through query transformation, high-performance tensor- and channel-wise quantization, and a software-pipelined dequantization kernel enabling mixed-precision execution. Architecture-aware optimizations further leverage Hopper's warpgroup tensor instructions and Blackwell's NVFP4 (MXFP4) tensor formats. Evaluated on Blackwell, Hopper, and Ampere GPUs, BitDecoding achieves an average 7.5x decoding speedup over FP16 FlashDecoding-v2, up to 8.6x on Blackwell with NVFP4, and up to 4.3x over state-of-the-art approaches. On LLaMA-3.1-8B with a 128K context, BitDecoding reduces single-batch decoding latency by 3x. BitDecoding is open-sourced at https://github.com/OpenBitSys/BitDecoding.