Capturing Individual Human Preferences with Reward Features
作者: André Barreto, Vincent Dumoulin, Yiran Mao, Nicolas Perez-Nieves, Bobak Shahriari, Yann Dauphin, Doina Precup, Hugo Larochelle
分类: cs.AI, cs.LG, stat.ML
发布日期: 2025-03-21
💡 一句话要点
提出基于奖励特征的个性化奖励模型,用于捕获个体人类偏好
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 人类反馈 奖励模型 个性化 语言模型 偏好学习 奖励特征
📋 核心要点
- 现有奖励模型在处理人类反馈强化学习时,未能区分个体偏好,导致在存在意见分歧的场景下表现不佳。
- 该论文提出一种基于奖励特征的个性化奖励模型,通过学习通用奖励特征的线性组合来捕获个体偏好。
- 实验结果表明,该模型在存在意见分歧的训练数据中显著优于基线模型,或在数据一致时匹配基线性能。
📝 摘要(中文)
从人类反馈中进行强化学习通常使用奖励模型来建模偏好,而没有区分个体。我们认为,在存在高度意见分歧的场景(如大型语言模型的训练)中,这不太可能是一个好的设计选择。我们提出了一种将奖励模型专门化到个人或人群的方法。我们的方法建立在以下观察之上:个体偏好可以被捕获为一组通用奖励特征的线性组合。我们展示了如何学习这些特征,并随后使用它们来快速地将奖励模型适应于特定的个体,即使他们的偏好没有反映在训练数据中。我们使用大型语言模型进行了实验,将所提出的架构与非自适应奖励模型以及自适应模型(包括上下文个性化模型)进行了比较。根据训练数据中存在多少分歧,我们的模型要么显著优于基线,要么以更简单的架构和更稳定的训练匹配它们的性能。
🔬 方法详解
问题定义:论文旨在解决现有奖励模型无法区分个体偏好,从而在人类反馈强化学习中表现不佳的问题。特别是在大型语言模型训练等存在高度意见分歧的场景下,使用统一的奖励模型无法有效捕捉不同个体的偏好差异,导致模型训练效果受限。现有方法要么忽略个体差异,要么采用复杂的上下文个性化方法,但这些方法可能不稳定或需要大量数据。
核心思路:论文的核心思路是将个体偏好表示为一组通用奖励特征的线性组合。这意味着,虽然每个人的偏好可能不同,但它们都可以通过对一组共同的、可学习的奖励特征进行加权求和来近似。通过学习这些通用特征,并为每个个体学习相应的权重,可以实现对个体偏好的快速适应。
技术框架:整体框架包含两个主要阶段:1) 奖励特征学习阶段:使用包含多个个体偏好的训练数据,学习一组通用的奖励特征。这可以通过训练一个神经网络来实现,该网络接收输入(例如,语言模型的输出)并输出一组奖励特征。2) 个性化适应阶段:对于新的个体,通过少量数据(例如,个体对几个样本的偏好排序)学习该个体对应的奖励特征权重。然后,将学习到的权重与通用奖励特征结合,得到该个体的个性化奖励模型。
关键创新:该论文的关键创新在于将个体偏好分解为通用奖励特征和个体权重两部分。这种分解使得模型能够从包含多个个体偏好的数据中学习通用的知识,并能够快速适应新的个体,即使该个体的偏好与训练数据中的偏好存在差异。与传统的非自适应奖励模型相比,该方法能够更好地捕捉个体偏好差异。与上下文个性化方法相比,该方法更加稳定且需要更少的数据。
关键设计:奖励特征学习阶段可以使用各种神经网络结构,例如Transformer或MLP。损失函数可以采用pairwise ranking loss,鼓励模型对个体偏好的样本进行正确排序。个性化适应阶段可以使用线性回归或其他简单的优化方法来学习个体权重。关键参数包括奖励特征的数量、神经网络的结构和学习率等。论文可能还采用了正则化技术来防止过拟合。
🖼️ 关键图片


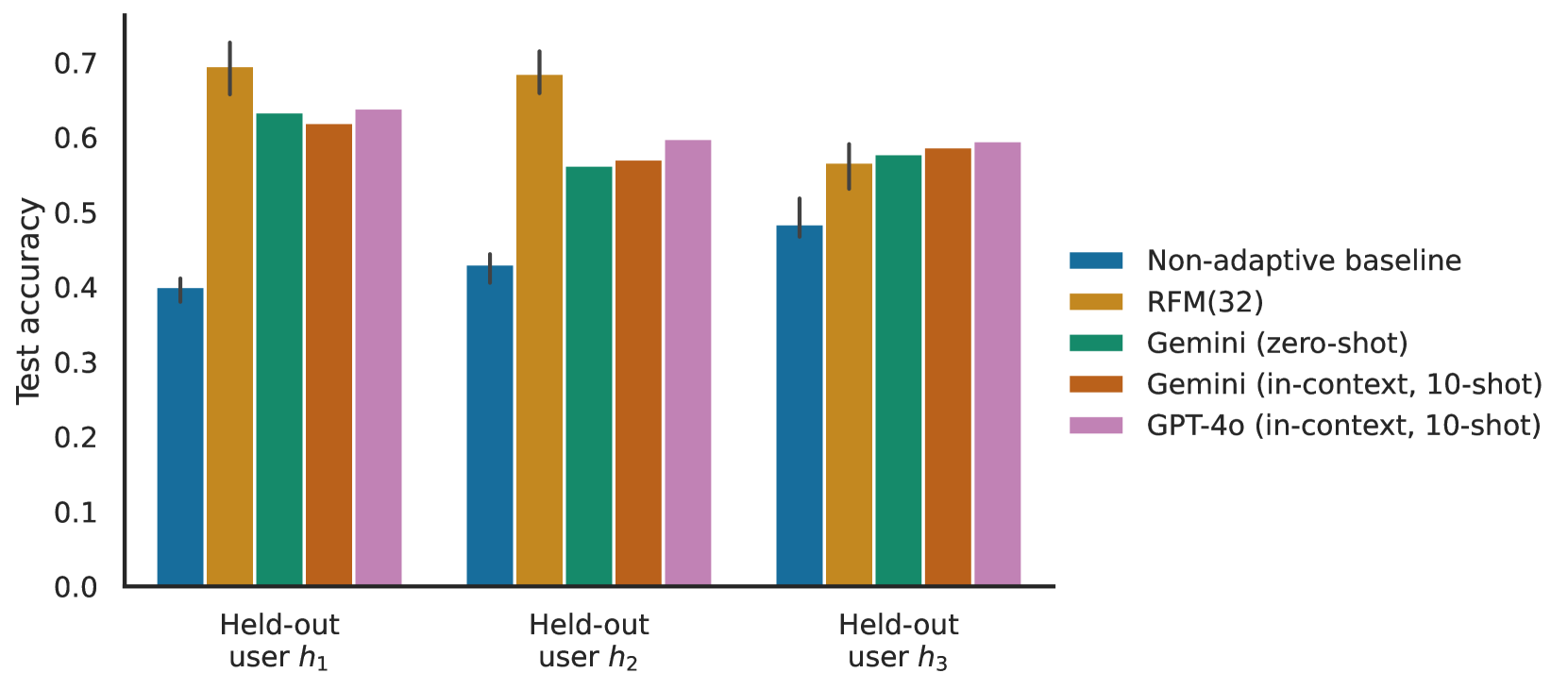
📊 实验亮点
实验结果表明,在训练数据存在较高分歧的情况下,该模型显著优于非自适应奖励模型和上下文个性化模型。在训练数据一致的情况下,该模型也能达到与基线模型相当的性能,同时具有更简单的架构和更稳定的训练过程。具体的性能提升幅度未知,需要在论文中查找。
🎯 应用场景
该研究成果可应用于各种需要个性化反馈的强化学习场景,例如个性化推荐系统、定制化教育平台和人机协作机器人。通过捕捉个体偏好,可以显著提升用户体验和系统性能,并促进更高效、更人性化的智能系统设计。尤其在大型语言模型对齐人类价值观方面,该方法具有重要意义。
📄 摘要(原文)
Reinforcement learning from human feedback usually models preferences using a reward model that does not distinguish between people. We argue that this is unlikely to be a good design choice in contexts with high potential for disagreement, like in the training of large language models. We propose a method to specialise a reward model to a person or group of people. Our approach builds on the observation that individual preferences can be captured as a linear combination of a set of general reward features. We show how to learn such features and subsequently use them to quickly adapt the reward model to a specific individual, even if their preferences are not reflected in the training data. We present experiments with large language models comparing the proposed architecture with a non-adaptive reward model and also adaptive counterparts, including models that do in-context personalisation. Depending on how much disagreement there is in the training data, our model either significantly outperforms the baselines or matches their performance with a simpler architecture and more stable training.