A Study of LLMs' Preferences for Libraries and Programming Languages
作者: Lukas Twist, Jie M. Zhang, Mark Harman, Don Syme, Joost Noppen, Helen Yannakoudakis, Detlef Nauck
分类: cs.SE, cs.AI
发布日期: 2025-03-21 (更新: 2025-07-21)
备注: 13 pages, 8 tables, 2 figures. Paper was previously titled "LLMs Love Python"
💡 一句话要点
研究揭示LLM在代码生成中对特定库和语言的偏好及潜在风险
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 代码生成 编程语言偏好 软件开发 实证研究
📋 核心要点
- 现有研究缺乏对LLM在代码生成中对库和编程语言偏好的系统性分析,可能导致软件开发中的偏差。
- 该研究通过实证分析多种LLM在代码生成任务中的行为,揭示其对特定库和语言的偏好。
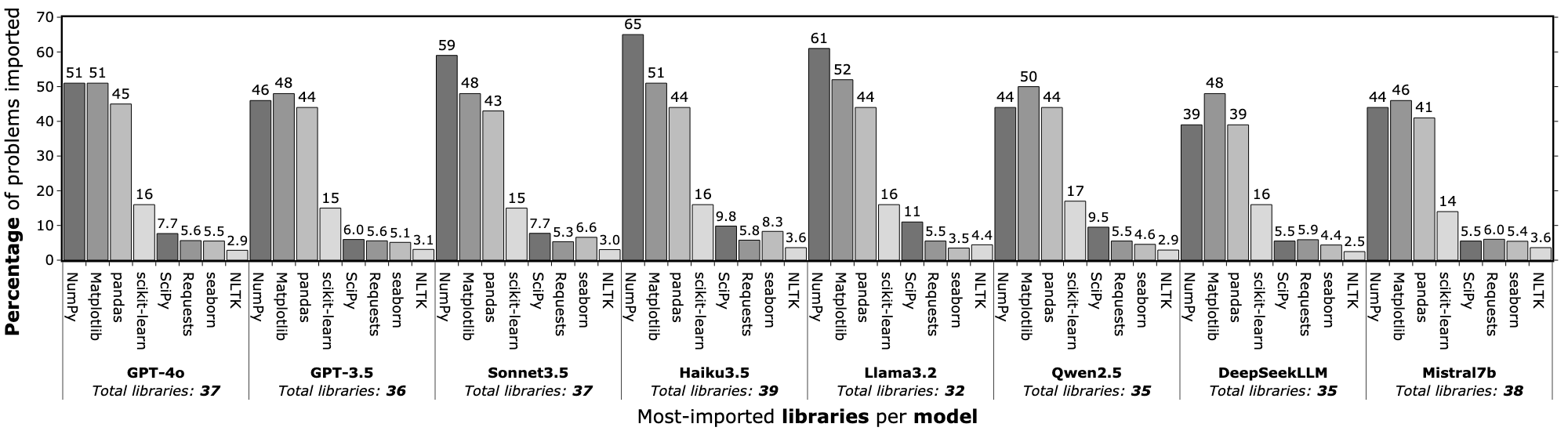
- 实验结果表明LLM倾向于过度使用流行库和偏好Python,即使在不适合的场景下,可能引入风险。
📝 摘要(中文)
大型语言模型(LLM)越来越多地被用于生成代码,这影响了用户在关键的实际项目中对库和编程语言的选择。然而,关于LLM对特定库和编程语言的系统性偏差或偏好知之甚少,而这可能会严重影响软件开发实践。为了填补这一空白,我们首次对LLM在生成代码时对库和编程语言的偏好进行了实证研究,涵盖了八种不同的LLM。结果表明,LLM表现出过度使用广泛采用的库(如NumPy)的强烈倾向;在高达48%的案例中,这种使用是不必要的,并且偏离了真实解决方案。LLM还表现出对Python作为默认语言的显著偏好。对于Python并非最佳语言的高性能项目初始化任务,Python仍然是58%案例中的主要选择,而Rust一次都没有被使用。这些结果表明,LLM可能优先考虑熟悉性和流行度,而不是适用性和任务特定的最优性。这将引入安全漏洞和技术债务,并限制对新开发的、更适合的工具和语言的接触。理解和解决这些偏差对于将LLM负责任地集成到软件开发工作流程中至关重要。
🔬 方法详解
问题定义:论文旨在解决LLM在代码生成过程中存在的对特定库和编程语言的偏好问题。现有方法缺乏对这些偏好的系统性研究,导致LLM生成的代码可能不是最优的,甚至引入安全漏洞和技术债务。
核心思路:核心思路是通过实证研究,分析多种LLM在不同代码生成任务中的行为,量化它们对不同库和编程语言的偏好程度。通过对比LLM生成的代码与ground-truth解决方案,识别过度使用或不当使用特定库和语言的情况。
技术框架:研究框架主要包括以下几个步骤:1) 选择多种具有代表性的LLM;2) 设计一系列代码生成任务,涵盖不同领域和编程语言;3) 使用LLM生成代码,并记录其使用的库和编程语言;4) 将LLM生成的代码与ground-truth解决方案进行对比,评估其准确性和效率;5) 分析LLM对不同库和编程语言的偏好程度,并识别过度使用或不当使用的情况。
关键创新:该研究的关键创新在于首次对LLM在代码生成中对库和编程语言的偏好进行了系统性的实证研究。与以往关注LLM代码生成能力的研究不同,该研究关注LLM的潜在偏差,并揭示了其可能对软件开发实践产生的负面影响。
关键设计:研究中关键的设计包括:1) 选择具有代表性的LLM,例如不同规模和架构的模型;2) 设计多样化的代码生成任务,涵盖不同领域和编程语言,以评估LLM在不同场景下的行为;3) 使用客观的指标来量化LLM对不同库和编程语言的偏好程度,例如使用频率和与ground-truth的偏差。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM倾向于过度使用NumPy等流行库,在高达48%的案例中,这种使用是不必要的。此外,LLM对Python有显著偏好,即使在Python并非最优语言的场景下,Python仍然是主要选择(58%),而Rust一次都没有被使用。这些结果突出了LLM在代码生成中存在的偏差。
🎯 应用场景
该研究成果可应用于指导LLM在软件开发中的负责任使用,例如开发工具来检测和纠正LLM的偏差,或设计新的训练方法来减少LLM的偏好。此外,该研究还可以帮助开发者更好地理解LLM的局限性,并避免过度依赖LLM生成的代码。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly used to generate code, influencing users' choices of libraries and programming languages in critical real-world projects. However, little is known about their systematic biases or preferences toward certain libraries and programming languages, which can significantly impact software development practices. To fill this gap, we perform the first empirical study of LLMs' preferences for libraries and programming languages when generating code, covering eight diverse LLMs. Our results reveal that LLMs exhibit a strong tendency to overuse widely adopted libraries such as NumPy; in up to 48% of cases, this usage is unnecessary and deviates from the ground-truth solutions. LLMs also exhibit a significant preference toward Python as their default language. For high-performance project initialisation tasks where Python is not the optimal language, it remains the dominant choice in 58% of cases, and Rust is not used a single time. These results indicate that LLMs may prioritise familiarity and popularity over suitability and task-specific optimality. This will introduce security vulnerabilities and technical debt, and limit exposure to newly developed, better-suited tools and languages. Understanding and addressing these biases is essential for the responsible integration of LLMs into software development workflows.