Does Chain-of-Thought Reasoning Help Mobile GUI Agent? An Empirical Study
作者: Li Zhang, Longxi Gao, Mengwei Xu
分类: cs.AI
发布日期: 2025-03-21
🔗 代码/项目: GITHUB
💡 一句话要点
研究链式思考推理对移动GUI智能体的性能影响,发现其收益与代价并存
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 链式思考 移动GUI智能体 实证研究 基准测试
📋 核心要点
- 现有方法难以让视觉语言模型有效应用于移动GUI智能体,尤其是在理解复杂布局和多轮交互上。
- 通过对比分析商业VLMs的推理增强版本与基础版本,评估链式思考推理在移动GUI智能体中的作用。
- 实验表明,推理模型在交互式环境中表现出色,但在静态基准测试中提升有限,甚至可能降低性能。
📝 摘要(中文)
本文首次实证研究了具备推理能力的视觉语言模型(VLMs)在移动GUI智能体中的有效性。移动GUI智能体需要理解复杂的屏幕布局、用户指令以及执行多轮交互。研究评估了两对商业模型——Gemini 2.0 Flash和Claude 3.7 Sonnet,比较了它们的基础版本和推理增强版本在两个静态基准测试(ScreenSpot和AndroidControl)和一个交互式环境(AndroidWorld)上的表现。令人惊讶的是,Claude 3.7 Sonnet推理模型在AndroidWorld上取得了最先进的性能。然而,推理VLMs在静态基准测试上的改进通常很小,甚至在某些智能体设置中会降低性能。值得注意的是,推理和非推理VLMs在不同的任务集上失败,表明推理确实有影响,但其优点和缺点相互抵消。这些不一致性归因于基准测试和VLMs的局限性。基于这些发现,为进一步增强移动GUI智能体,在基准测试、VLMs以及动态调用推理VLMs的适应性方面提供了见解。实验数据已公开。
🔬 方法详解
问题定义:论文旨在研究链式思考(Chain-of-Thought, CoT)推理能力对移动GUI智能体性能的影响。现有方法虽然在数学、编码等领域取得了显著进展,但在实际应用,特别是移动GUI智能体领域,其有效性尚不明确。移动GUI智能体需要理解复杂的屏幕布局、用户指令,并进行多轮交互,这对模型的推理能力提出了更高的要求。现有研究缺乏对CoT推理在移动GUI智能体中作用的系统性评估。
核心思路:论文的核心思路是通过对比实验,评估具备CoT推理能力的VLMs与不具备CoT推理能力的VLMs在移动GUI智能体任务中的性能差异。通过在静态基准测试和交互式环境中进行评估,分析CoT推理的优势和局限性,从而为进一步提升移动GUI智能体的性能提供指导。
技术框架:论文采用对比实验的方法,评估了两对商业模型(Gemini 2.0 Flash和Claude 3.7 Sonnet)的基础版本和推理增强版本。评估在三个基准测试上进行:两个静态基准测试(ScreenSpot和AndroidControl)和一个交互式环境(AndroidWorld)。通过比较不同模型在这些基准测试上的性能,分析CoT推理的影响。
关键创新:论文的主要创新在于首次对CoT推理在移动GUI智能体中的有效性进行了实证研究。研究发现,CoT推理并非总是能够提升性能,其收益与代价并存。这一发现挑战了以往对CoT推理的普遍认知,并为未来的研究提供了新的方向。
关键设计:论文的关键设计包括:1) 选择具有代表性的商业VLMs进行评估;2) 采用静态基准测试和交互式环境相结合的评估方法;3) 对比分析推理增强版本和基础版本的性能差异;4) 分析CoT推理失败的原因,并提出改进建议。具体的参数设置和损失函数等技术细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片

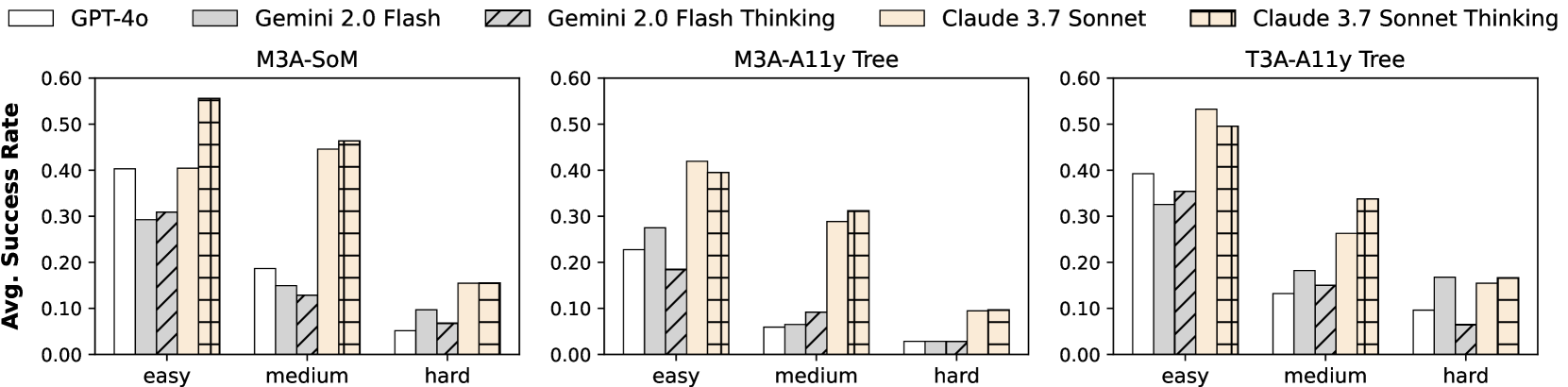

📊 实验亮点
实验结果显示,Claude 3.7 Sonnet推理模型在AndroidWorld交互式环境中取得了最先进的性能。然而,在静态基准测试中,推理模型的提升并不明显,甚至在某些情况下会降低性能。这表明CoT推理的有效性受到任务类型和模型能力的限制。
🎯 应用场景
该研究成果可应用于开发更智能、更易用的移动应用助手,例如自动化测试工具、无障碍辅助工具等。通过深入理解CoT推理在移动GUI智能体中的作用,可以设计出更有效的模型和算法,提升用户体验,并推动移动应用智能化发展。
📄 摘要(原文)
Reasoning capabilities have significantly improved the performance of vision-language models (VLMs) in domains such as mathematical problem-solving, coding, and visual question-answering. However, their impact on real-world applications remains unclear. This paper presents the first empirical study on the effectiveness of reasoning-enabled VLMs in mobile GUI agents, a domain that requires interpreting complex screen layouts, understanding user instructions, and executing multi-turn interactions. We evaluate two pairs of commercial models--Gemini 2.0 Flash and Claude 3.7 Sonnet--comparing their base and reasoning-enhanced versions across two static benchmarks (ScreenSpot and AndroidControl) and one interactive environment (AndroidWorld). We surprisingly find the Claude 3.7 Sonnet reasoning model achieves state-of-the-art performance on AndroidWorld. However, reasoning VLMs generally offer marginal improvements over non-reasoning models on static benchmarks and even degrade performance in some agent setups. Notably, reasoning and non-reasoning VLMs fail on different sets of tasks, suggesting that reasoning does have an impact, but its benefits and drawbacks counterbalance each other. We attribute these inconsistencies to the limitations of benchmarks and VLMs. Based on the findings, we provide insights for further enhancing mobile GUI agents in terms of benchmarks, VLMs, and their adaptability in dynamically invoking reasoning VLMs. The experimental data are publicly available at https://github.com/LlamaTouch/VLM-Reasoning-Traces.