Towards Automated Semantic Interpretability in Reinforcement Learning via Vision-Language Models
作者: Zhaoxin Li, Zhang Xi-Jia, Batuhan Altundas, Letian Chen, Rohan Paleja, Matthew Gombolay
分类: cs.AI, cs.LG
发布日期: 2025-03-20 (更新: 2025-10-31)
💡 一句话要点
提出iTRACE,利用视觉-语言模型自动构建可解释强化学习策略。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 可解释强化学习 视觉-语言模型 知识蒸馏 自动化特征提取 树状模型
📋 核心要点
- 传统可解释强化学习依赖人工标注特征,泛化性差,且常用黑盒策略,缺乏透明性。
- iTRACE利用预训练视觉-语言模型自动提取语义特征,并训练可解释的树状策略。
- 实验表明,iTRACE在Atari、导航和驾驶任务中优于可解释基线,并匹配黑盒策略性能。
📝 摘要(中文)
强化学习中的语义可解释性能够提升决策的透明性和可验证性。实现语义可解释性需要(1)一个由人类可理解的概念构成的特征空间,以及(2)一个可解释且可验证的策略。然而,构建这样的特征空间通常依赖于人工标注,这难以泛化到未见环境。此外,即使存在可解释的特征,大多数强化学习算法也采用黑盒模型作为策略,从而阻碍了透明性。我们提出了通过自动概念提取的可解释树状强化学习(iTRACE),这是一个自动化框架,利用预训练的视觉-语言模型(VLM)进行语义特征提取,并通过强化学习训练可解释的树状模型。为了解决在强化学习循环中运行VLM的不切实际性,我们将它们的输出提炼成一个轻量级模型。通过利用视觉-语言模型来自动化基于树的强化学习,iTRACE降低了对传统可解释模型所需的人工标注的依赖。此外,它还解决了VLM的关键局限性,例如缺乏在动作空间中的基础以及无法直接优化策略。我们在三个领域评估了iTRACE:Atari游戏、网格世界导航和驾驶。结果表明,iTRACE优于其他可解释的策略基线,并且在相同的可解释特征空间上匹配了黑盒策略的性能。
🔬 方法详解
问题定义:现有可解释强化学习方法主要依赖人工定义的特征空间,这不仅耗时耗力,而且难以泛化到新的、未知的环境中。此外,即使有了可解释的特征,许多强化学习算法仍然使用黑盒模型作为策略,这使得决策过程难以理解和验证。因此,如何自动构建可解释的特征空间,并学习可解释的策略,是当前可解释强化学习面临的关键挑战。
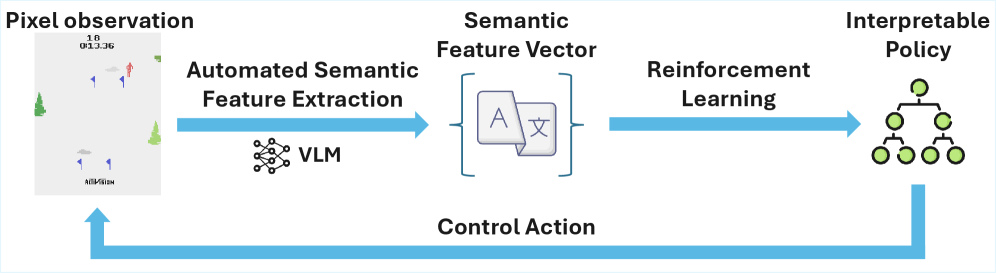
核心思路:iTRACE的核心思路是利用预训练的视觉-语言模型(VLM)来自动提取环境中的语义特征,从而避免人工标注的需要。同时,采用树状模型作为强化学习策略,因为树状模型本身具有良好的可解释性。为了解决VLM计算量大的问题,采用知识蒸馏技术,将VLM的输出提炼到一个轻量级的模型中,使其能够在强化学习循环中高效运行。
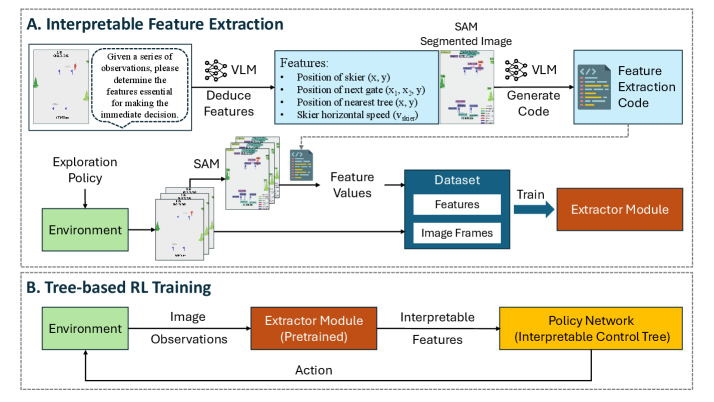
技术框架:iTRACE的整体框架包括以下几个主要模块:1) 视觉-语言模型(VLM):用于从环境图像中提取语义特征。2) 知识蒸馏:将VLM的输出提炼成一个轻量级模型,加速推理。3) 树状强化学习:使用提取的语义特征训练一个可解释的树状策略。具体流程是:首先,VLM处理环境图像,提取语义特征;然后,轻量级模型对VLM的输出进行近似;最后,使用强化学习算法(如Q-learning)训练树状策略,该策略以轻量级模型的输出作为输入。
关键创新:iTRACE最重要的创新点在于将预训练的视觉-语言模型引入到可解释强化学习中,实现了特征提取的自动化。与传统方法相比,iTRACE无需人工标注特征,能够更好地泛化到新的环境中。此外,通过知识蒸馏,解决了VLM计算量大的问题,使其能够在强化学习循环中高效运行。
关键设计:在VLM的选择上,论文使用了预训练的CLIP模型。知识蒸馏采用最小化KL散度损失函数,使得轻量级模型的输出尽可能接近VLM的输出。树状强化学习采用Q-learning算法,并对树的结构进行约束,以保证其可解释性。具体的树结构参数(如树的深度、分支数)需要根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
iTRACE在Atari游戏、网格世界导航和驾驶等多个领域进行了评估。实验结果表明,iTRACE在可解释性方面优于其他可解释的策略基线,并且在性能上能够匹配甚至超过黑盒策略。例如,在Atari游戏中,iTRACE的性能接近DQN,同时具有更好的可解释性。
🎯 应用场景
iTRACE具有广泛的应用前景,例如在自动驾驶领域,可以帮助理解车辆的决策过程,提高安全性;在游戏AI领域,可以生成更具可解释性的游戏策略,方便玩家学习和理解;在机器人控制领域,可以实现对机器人行为的透明化控制,方便用户进行调试和优化。
📄 摘要(原文)
Semantic interpretability in Reinforcement Learning (RL) enables transparency and verifiability of decision-making. Achieving semantic interpretability in reinforcement learning requires (1) a feature space composed of human-understandable concepts and (2) a policy that is interpretable and verifiable. However, constructing such a feature space has traditionally relied on manual human specification, which often fails to generalize to unseen environments. Moreover, even when interpretable features are available, most reinforcement learning algorithms employ black-box models as policies, thereby hindering transparency. We introduce interpretable Tree-based Reinforcement learning via Automated Concept Extraction (iTRACE), an automated framework that leverages pre-trained vision-language models (VLM) for semantic feature extraction and train a interpretable tree-based model via RL. To address the impracticality of running VLMs in RL loops, we distill their outputs into a lightweight model. By leveraging Vision-Language Models (VLMs) to automate tree-based reinforcement learning, iTRACE loosens the reliance the need for human annotation that is traditionally required by interpretable models. In addition, it addresses key limitations of VLMs alone, such as their lack of grounding in action spaces and their inability to directly optimize policies. We evaluate iTRACE across three domains: Atari games, grid-world navigation, and driving. The results show that iTRACE outperforms other interpretable policy baselines and matches the performance of black-box policies on the same interpretable feature space.