Deconstructing Long Chain-of-Thought: A Structured Reasoning Optimization Framework for Long CoT Distillation
作者: Yijia Luo, Yulin Song, Xingyao Zhang, Jiaheng Liu, Weixun Wang, GengRu Chen, Wenbo Su, Bo Zheng
分类: cs.AI
发布日期: 2025-03-20
💡 一句话要点
提出DLCoT框架,优化长链思维蒸馏,提升非同源模型性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长链思维 知识蒸馏 数据增强 语言模型 推理能力
📋 核心要点
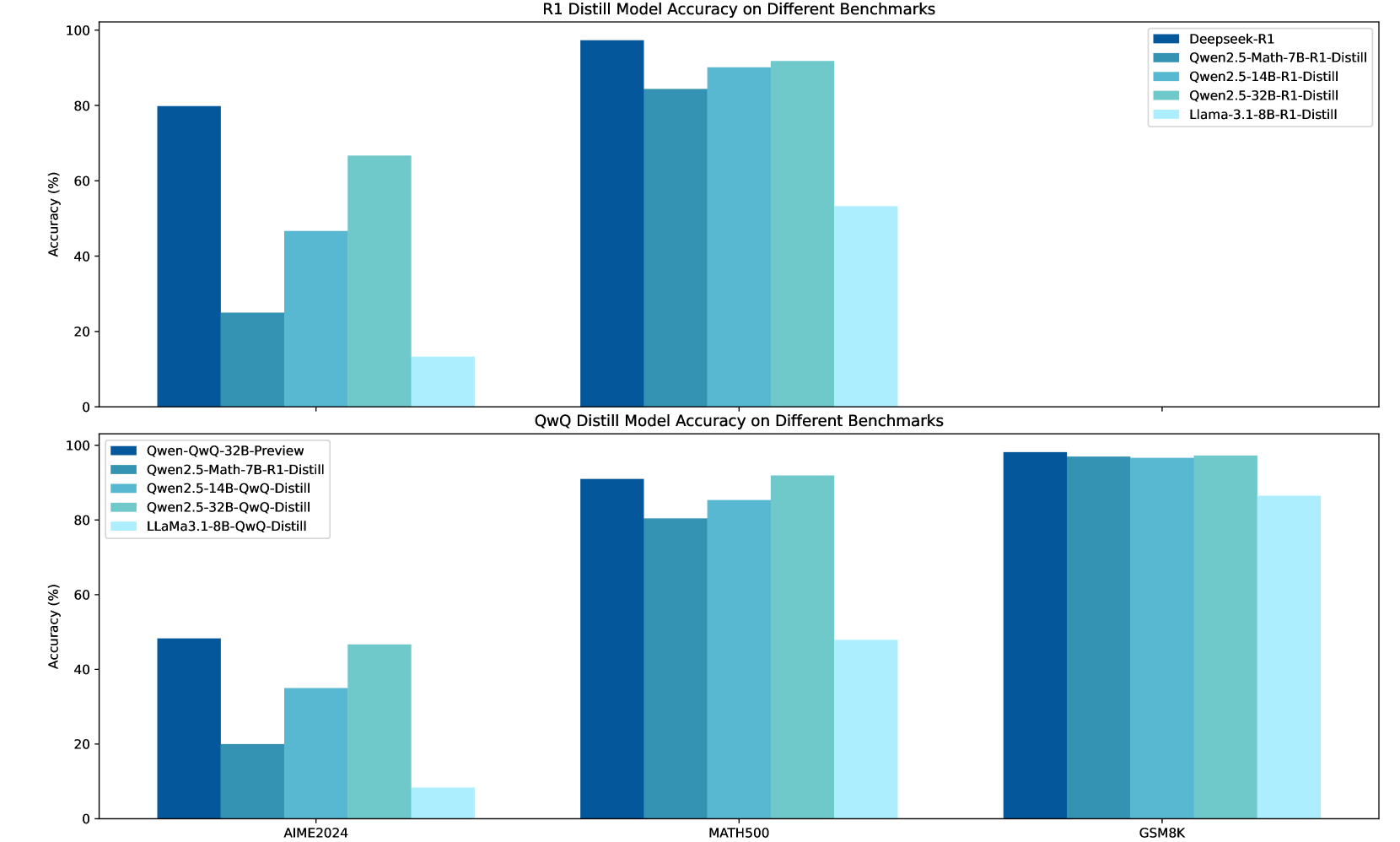
- 现有长链思维蒸馏方法在非同源模型上的泛化能力不足,限制了其应用范围。
- DLCoT框架通过解构、简化和优化长链思维过程,增强蒸馏数据的质量和有效性。
- 实验表明,DLCoT显著提升了模型性能和token效率,尤其是在非同源模型上。
📝 摘要(中文)
大型语言模型(LLMs)通过长链思维(CoT)推理展现了卓越的推理能力。R1蒸馏方案已成为一种有前景的方法,用于训练具有增强推理能力的低成本模型。然而,其有效性的潜在机制仍不清楚。本研究检验了蒸馏数据的通用性,并确定了在LLM蒸馏中有效转移长链推理能力的关键组成部分。研究结果表明,来自Qwen-QwQ等教师模型的长CoT推理蒸馏在非同源模型上的有效性显著降低,这挑战了当前蒸馏方法所假设的通用性。为了更深入地了解长CoT推理的结构和模式,我们提出了DLCoT(解构长链思维),一个蒸馏数据增强框架。DLCoT包含三个关键步骤:(1)数据分割以分解复杂的长CoT结构,(2)通过消除无法解决的和冗余的解决方案进行简化,以及(3)优化中间错误状态。我们的方法显著提高了模型性能和token效率,促进了高性能LLM的开发。
🔬 方法详解
问题定义:论文旨在解决长链思维(Long Chain-of-Thought, CoT)蒸馏在非同源模型上效果不佳的问题。现有方法假设蒸馏数据具有通用性,但实验表明,从特定教师模型(如Qwen-QwQ)蒸馏出的长CoT知识在结构差异较大的学生模型上性能显著下降。这表明长CoT推理的有效传递依赖于更细粒度的结构化信息,而现有方法未能充分利用这些信息。
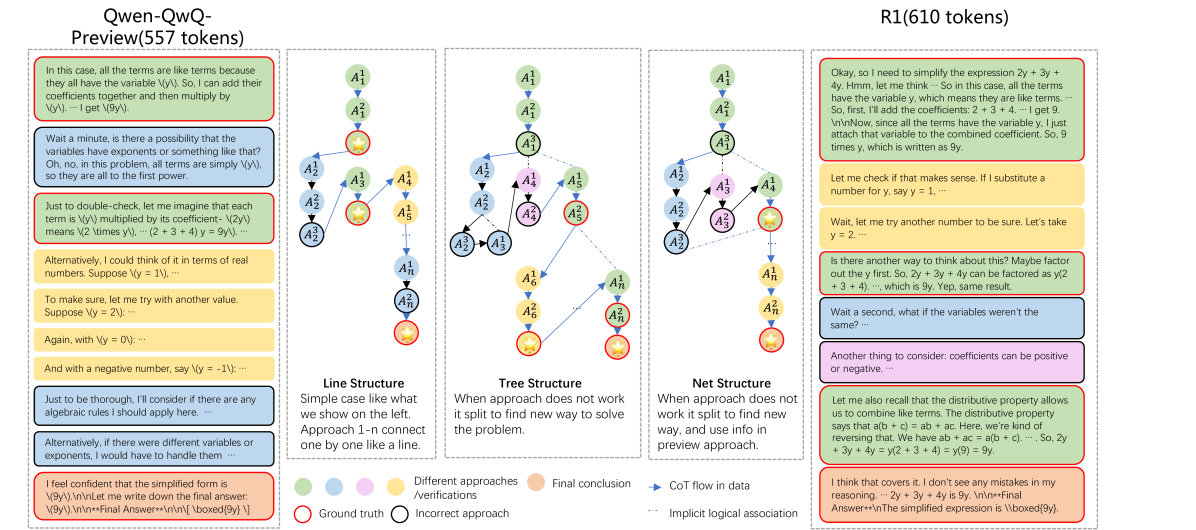
核心思路:论文的核心思路是将长CoT推理过程解构为更小的、更易于理解和学习的片段,并通过简化和优化这些片段来提高蒸馏数据的质量。通过数据分割,将复杂的长CoT结构分解为更小的单元;通过消除不可解和冗余的解决方案,减少噪声;通过优化中间错误状态,引导模型学习正确的推理路径。这种结构化的方法旨在提高学生模型学习长CoT推理能力时的效率和泛化能力。
技术框架:DLCoT框架包含三个主要阶段:数据分割、简化和优化。首先,数据分割阶段将长CoT推理过程分解为更小的、独立的步骤。然后,简化阶段消除不可解或冗余的步骤,减少噪声并提高数据质量。最后,优化阶段通过识别和纠正中间错误状态,引导模型学习正确的推理路径。这三个阶段共同作用,生成高质量的蒸馏数据,从而提高学生模型的性能。
关键创新:DLCoT的关键创新在于其结构化的蒸馏数据增强方法。与传统的直接蒸馏方法不同,DLCoT不是简单地将教师模型的输出复制到学生模型,而是通过解构、简化和优化长CoT推理过程,提取更本质的推理知识。这种方法能够更好地适应不同结构的模型的学习需求,从而提高蒸馏的有效性和泛化能力。
关键设计:数据分割的具体方法未知,论文中可能使用了启发式规则或基于模型的分割算法。简化阶段可能使用了基于逻辑推理或知识图谱的方法来识别和消除不可解或冗余的步骤。优化阶段可能使用了强化学习或对抗训练等技术来引导模型学习正确的推理路径。具体的参数设置、损失函数和网络结构等技术细节在论文中可能有所描述,但此处无法得知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,DLCoT框架能够显著提高非同源模型的性能和token效率。具体提升幅度未知,但摘要中提到“显著提高了模型性能和token效率”,表明DLCoT在长链思维蒸馏方面取得了重要进展。与直接蒸馏方法相比,DLCoT能够更好地传递教师模型的推理能力,尤其是在模型结构差异较大的情况下。
🎯 应用场景
该研究成果可应用于各种需要复杂推理能力的自然语言处理任务,例如问答系统、文本摘要、机器翻译等。通过DLCoT框架,可以训练出更高效、更强大的语言模型,从而提升这些应用在实际场景中的性能和用户体验。此外,该方法还有助于降低模型训练的成本,促进大型语言模型在资源有限环境下的部署。
📄 摘要(原文)
Recent advancements in large language models (LLMs) have demonstrated remarkable reasoning capabilities through long chain-of-thought (CoT) reasoning. The R1 distillation scheme has emerged as a promising approach for training cost-effective models with enhanced reasoning abilities. However, the underlying mechanisms driving its effectiveness remain unclear. This study examines the universality of distillation data and identifies key components that enable the efficient transfer of long-chain reasoning capabilities in LLM distillation. Our findings reveal that the effectiveness of long CoT reasoning distillation from teacher models like Qwen-QwQ degrades significantly on nonhomologous models, challenging the assumed universality of current distillation methods. To gain deeper insights into the structure and patterns of long CoT reasoning, we propose DLCoT (Deconstructing Long Chain-of-Thought), a distillation data enhancement framework. DLCoT consists of three key steps: (1) data segmentation to decompose complex long CoT structures, (2) simplification by eliminating unsolvable and redundant solutions, and (3) optimization of intermediate error states. Our approach significantly improves model performance and token efficiency, facilitating the development of high-performance LLMs.