Video-VoT-R1: An efficient video inference model integrating image packing and AoE architecture
作者: Cheng Li, Jiexiong Liu, Yixuan Chen, Yanqin Jia
分类: cs.AI
发布日期: 2025-03-20
备注: 18 pages
💡 一句话要点
提出Video-VoT-R1模型,结合图像打包和AoE架构,提升视频语言预训练的推理效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频语言预训练 图像打包 AoE架构 Video of Thought 视频推理 长序列视频 多模态学习
📋 核心要点
- 现有视频语言预训练模型在推理效率和多模态数据处理方面面临诸多挑战。
- 论文提出Video-VoT-R1模型,通过图像打包、AoE架构和VoT等技术,提升视频推理效率和准确性。
- 实验表明,该模型在多项测试中表现出色,为视频语言理解提供了一种新的解决方案。
📝 摘要(中文)
本文提出了一种基于长序列图像编码器的昆仑-Baize-VoT-R1视频推理模型,并阐述了其训练和应用方法。该模型集成了图像打包技术、Autonomy-of-Experts (AoE) 架构,并结合了Video of Thought (VoT),一个通过大规模强化学习训练的大语言模型 (LLM),以及多种训练技巧,从而有效提高了模型在视频推理任务中的效率和准确性。实验结果表明,该模型在多项测试中表现出色,为视频语言理解提供了一种新的解决方案。
🔬 方法详解
问题定义:现有视频语言预训练模型在推理效率和多模态数据处理方面存在瓶颈。具体来说,如何高效地处理长视频序列,并融合视觉信息和语言信息,是亟待解决的问题。现有方法通常计算复杂度高,难以满足实际应用的需求。
核心思路:论文的核心思路是利用图像打包技术减少计算量,并采用Autonomy-of-Experts (AoE) 架构提升模型处理复杂场景的能力。同时,结合Video of Thought (VoT) 大语言模型,增强模型对视频内容的理解和推理能力。
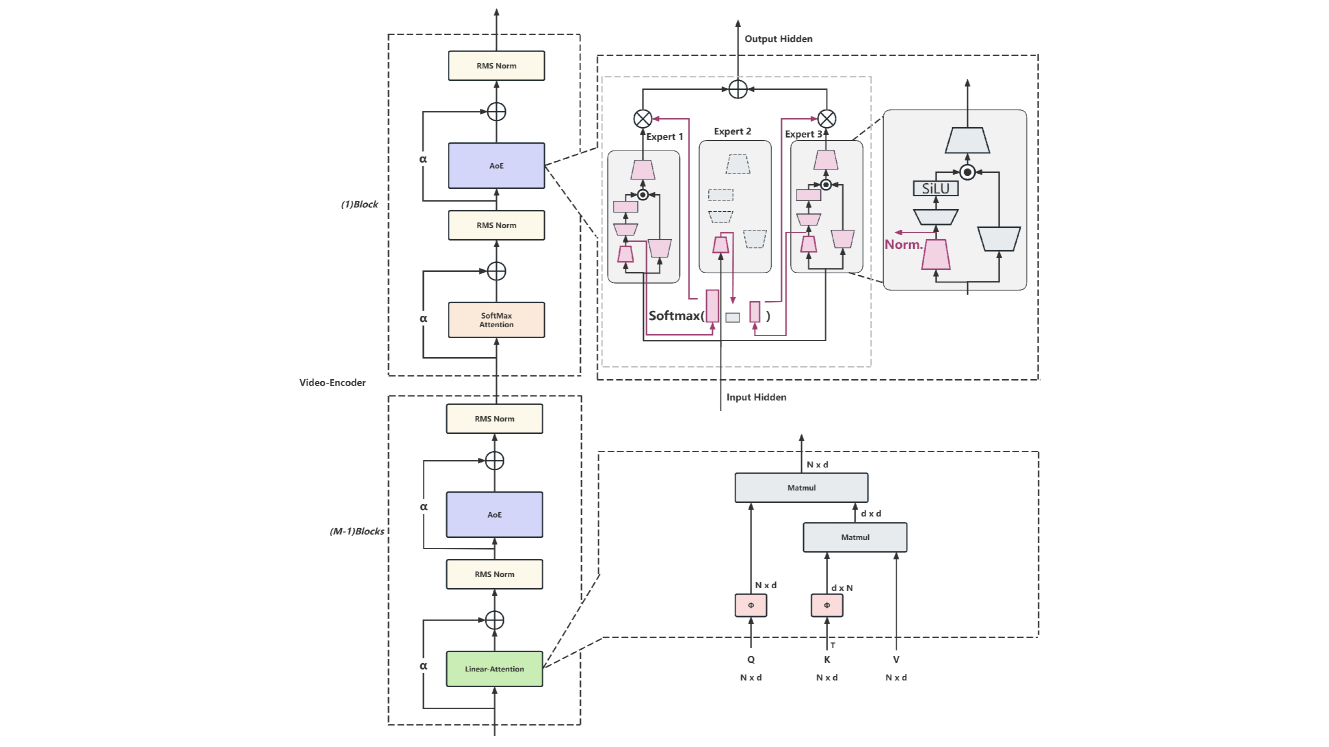
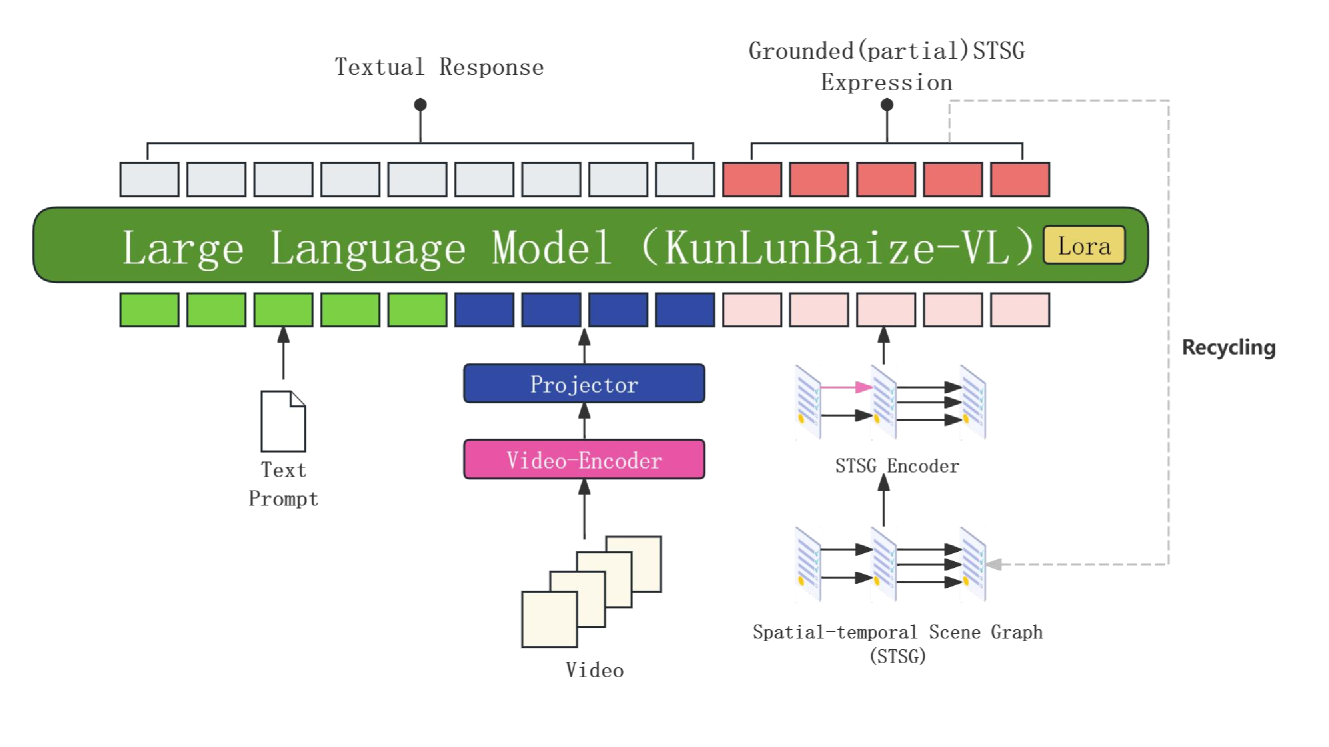
技术框架:Video-VoT-R1模型主要包含以下几个模块:1) 长序列图像编码器,用于提取视频帧的视觉特征;2) 图像打包模块,用于将多个图像打包成一个输入,减少计算量;3) AoE架构,由多个专家模型组成,每个专家负责处理特定类型的视频内容;4) VoT大语言模型,用于对视频内容进行推理和生成。整体流程是:输入视频序列,经过图像编码器和图像打包模块处理后,输入到AoE架构中,由相应的专家模型进行处理,最后由VoT大语言模型进行推理和生成。
关键创新:该模型的主要创新点在于:1) 图像打包技术,通过减少输入图像的数量,显著降低了计算复杂度;2) AoE架构,能够根据视频内容动态选择合适的专家模型,提高了模型的适应性和准确性;3) 结合VoT大语言模型,增强了模型对视频内容的理解和推理能力。
关键设计:图像打包的具体实现方式未知,但推测可能涉及图像resize、裁剪或拼接等操作。AoE架构中专家模型的数量和类型需要根据具体应用场景进行选择。VoT大语言模型的训练需要大规模的视频文本数据和强化学习技术。损失函数的设计可能包括视觉特征提取的损失、专家模型选择的损失以及语言模型生成的损失。
🖼️ 关键图片
📊 实验亮点
论文提出的Video-VoT-R1模型在视频推理任务中表现出色,但具体的性能数据、对比基线和提升幅度未知。摘要中提到“在多项测试中表现出色”,表明该模型具有一定的优越性,但需要进一步的实验数据来验证其有效性。
🎯 应用场景
该研究成果可应用于视频内容理解、智能监控、视频搜索、视频摘要生成等领域。通过提高视频推理的效率和准确性,可以更好地理解视频内容,从而为用户提供更智能、更便捷的服务。未来,该模型有望在自动驾驶、机器人等领域发挥重要作用。
📄 摘要(原文)
In the field of video-language pretraining, existing models face numerous challenges in terms of inference efficiency and multimodal data processing. This paper proposes a KunLunBaize-VoT-R1 video inference model based on a long-sequence image encoder, along with its training and application methods. By integrating image packing technology, the Autonomy-of-Experts (AoE) architecture, and combining the video of Thought (VoT), a large language model (LLM) trained with large-scale reinforcement learning, and multiple training techniques, the efficiency and accuracy of the model in video inference tasks are effectively improved. Experiments show that this model performs outstandingly in multiple tests, providing a new solution for video-language understanding.