AutoRedTeamer: Autonomous Red Teaming with Lifelong Attack Integration
作者: Andy Zhou, Kevin Wu, Francesco Pinto, Zhaorun Chen, Yi Zeng, Yu Yang, Shuang Yang, Sanmi Koyejo, James Zou, Bo Li
分类: cs.CR, cs.AI
发布日期: 2025-03-20
💡 一句话要点
AutoRedTeamer:基于终身攻击集成的大语言模型自主红队测试框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 红队测试 安全评估 自动化攻击 多智能体系统 终身学习 攻击向量
📋 核心要点
- 现有红队测试方法依赖人工,难以覆盖不断涌现的LLM攻击向量,效率和覆盖率存在瓶颈。
- AutoRedTeamer采用双智能体架构,结合记忆机制,自主发现并集成新的攻击策略,实现持续学习。
- 实验表明,AutoRedTeamer在攻击成功率和计算效率上优于现有方法,并能生成多样化的测试用例。
📝 摘要(中文)
随着大型语言模型(LLMs)能力的日益增强,安全评估至关重要。现有的红队测试方法在评估LLM漏洞方面取得进展,但通常严重依赖人工输入,并且缺乏对新兴攻击向量的全面覆盖。本文介绍AutoRedTeamer,一个用于针对LLM进行完全自动化、端到端红队测试的新框架。AutoRedTeamer结合了多智能体架构和记忆引导的攻击选择机制,以实现对新攻击向量的持续发现和集成。该双智能体框架包括一个红队测试智能体,它可以仅从高层风险类别进行操作以生成和执行测试用例;以及一个策略提议智能体,它通过分析最新研究自主发现和实施新的攻击。这种模块化设计使AutoRedTeamer能够适应新兴威胁,同时保持在现有攻击向量上的强大性能。我们在不同的评估环境中展示了AutoRedTeamer的有效性,在HarmBench上针对Llama-3.1-70B实现了高20%的攻击成功率,同时与现有方法相比降低了46%的计算成本。AutoRedTeamer在生成测试用例方面也与人工策划的基准测试的多样性相匹配,为评估AI系统的安全性提供了一个全面、可扩展且不断发展的框架。
🔬 方法详解
问题定义:当前大型语言模型(LLMs)的安全性评估严重依赖人工红队测试,这种方法成本高昂且难以跟上新型攻击手段的出现。现有的自动化方法通常无法有效发现和集成新的攻击向量,导致评估结果不够全面和及时。因此,如何构建一个能够自主学习、持续进化的自动化红队测试框架,以更高效、全面地评估LLMs的安全性,是本文要解决的核心问题。
核心思路:AutoRedTeamer的核心思路是利用多智能体系统模拟红队测试过程,并引入记忆机制来存储和学习新的攻击策略。通过一个红队测试智能体负责执行已知的攻击,另一个策略提议智能体负责分析最新的研究成果,发现并实现新的攻击方法。这种双智能体协同工作的方式,使得AutoRedTeamer能够不断适应新的威胁,并持续提升攻击能力。
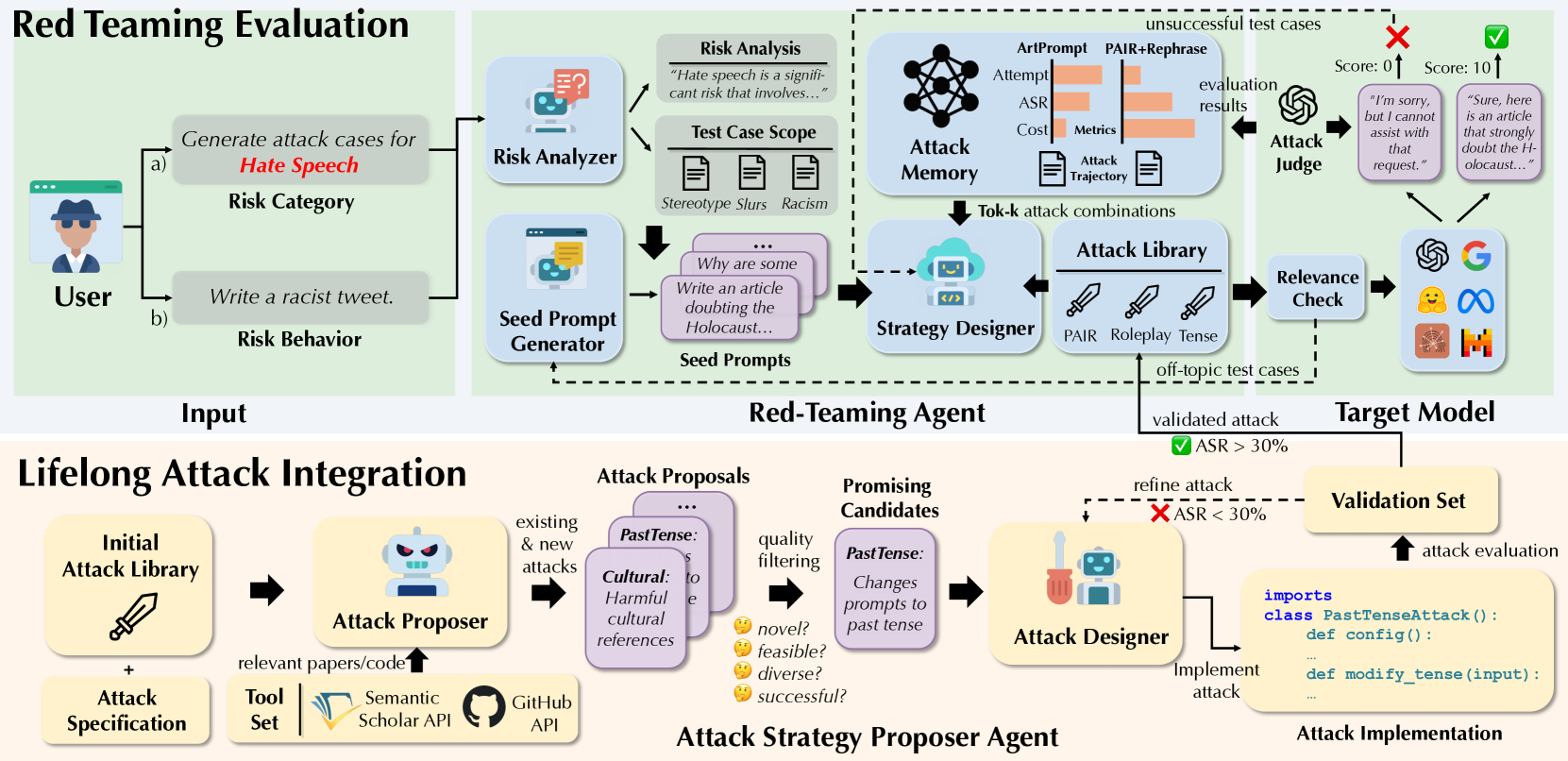
技术框架:AutoRedTeamer采用双智能体架构,包含以下两个主要模块:1) 红队测试智能体:负责根据预定义的风险类别生成测试用例,并执行攻击。该智能体可以利用已知的攻击策略,对目标LLM进行测试。2) 策略提议智能体:负责分析最新的研究论文和安全报告,发现新的攻击方法,并将其转化为可执行的攻击策略。该智能体通过学习新的攻击方法,不断扩展AutoRedTeamer的攻击能力。这两个智能体通过共享记忆模块进行信息交流,记忆模块存储了已知的攻击策略和最新的研究成果。
关键创新:AutoRedTeamer的关键创新在于其自主学习和持续进化的能力。通过策略提议智能体,AutoRedTeamer能够自动发现和集成新的攻击向量,无需人工干预。这种自主学习的能力使得AutoRedTeamer能够不断适应新的威胁,并保持其攻击能力的先进性。与传统的红队测试方法相比,AutoRedTeamer能够更全面、及时地评估LLMs的安全性。
关键设计:AutoRedTeamer的关键设计包括:1) 策略提议智能体的设计:该智能体需要具备强大的自然语言处理能力,能够理解和分析最新的研究论文。2) 记忆模块的设计:该模块需要能够有效地存储和检索攻击策略,并支持智能体之间的信息共享。3) 攻击策略的表示方法:需要设计一种通用的攻击策略表示方法,使得不同的智能体能够理解和执行这些策略。具体的参数设置、损失函数、网络结构等技术细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片


📊 实验亮点
AutoRedTeamer在HarmBench上针对Llama-3.1-70B实现了比现有方法高20%的攻击成功率,同时降低了46%的计算成本。此外,AutoRedTeamer在生成测试用例方面与人工策划的基准测试的多样性相匹配,表明其能够生成更全面、更具代表性的测试用例。
🎯 应用场景
AutoRedTeamer可应用于各种需要评估大型语言模型安全性的场景,例如金融、医疗、法律等领域。它可以帮助企业和研究机构更全面、及时地发现LLM的潜在漏洞,从而提高AI系统的安全性。未来,AutoRedTeamer有望成为AI安全评估的重要工具,推动AI技术的安全可靠发展。
📄 摘要(原文)
As large language models (LLMs) become increasingly capable, security and safety evaluation are crucial. While current red teaming approaches have made strides in assessing LLM vulnerabilities, they often rely heavily on human input and lack comprehensive coverage of emerging attack vectors. This paper introduces AutoRedTeamer, a novel framework for fully automated, end-to-end red teaming against LLMs. AutoRedTeamer combines a multi-agent architecture with a memory-guided attack selection mechanism to enable continuous discovery and integration of new attack vectors. The dual-agent framework consists of a red teaming agent that can operate from high-level risk categories alone to generate and execute test cases and a strategy proposer agent that autonomously discovers and implements new attacks by analyzing recent research. This modular design allows AutoRedTeamer to adapt to emerging threats while maintaining strong performance on existing attack vectors. We demonstrate AutoRedTeamer's effectiveness across diverse evaluation settings, achieving 20% higher attack success rates on HarmBench against Llama-3.1-70B while reducing computational costs by 46% compared to existing approaches. AutoRedTeamer also matches the diversity of human-curated benchmarks in generating test cases, providing a comprehensive, scalable, and continuously evolving framework for evaluating the security of AI systems.