Aligning Crowd-sourced Human Feedback for Reinforcement Learning on Code Generation by Large Language Models
作者: Man Fai Wong, Chee Wei Tan
分类: cs.AI
发布日期: 2025-03-19
DOI: 10.1109/TBDATA.2024.3524104
💡 一句话要点
提出基于众包人类反馈的强化学习框架,提升LLM代码生成能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大型语言模型 强化学习 人类反馈 贝叶斯优化 众包 AI辅助编程
📋 核心要点
- 现有文本到代码生成方法难以有效整合高质量的人类反馈,限制了LLM在代码生成任务中的性能。
- 提出一种基于贝叶斯优化的强化学习框架,利用众包人类反馈来对齐LLM的代码生成能力。
- 实验结果表明,该方法能够有效训练LLM代理,显著提升文本到代码生成的质量和准确性。
📝 摘要(中文)
本文研究了人工智能辅助编程和大型语言模型(LLM)如何通过AI工具(如Github Copilot和Amazon CodeWhisperer)提升软件开发者的能力,同时整合人类反馈,利用众包计算增强强化学习(RLHF),以改进文本到代码的生成。此外,我们展示了我们的贝叶斯优化框架支持代码生成中的AI对齐,通过分散反馈收集负担,突出了收集高质量人类反馈的价值。我们的实证评估证明了这种方法的有效性,展示了如何有效地训练LLM代理以改进文本到代码的生成。我们的贝叶斯优化框架可以设计用于通用的领域特定语言,从而促进大型语言模型能力与AI辅助编程中代码生成的人类反馈的对齐。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在文本到代码生成任务中,如何有效利用人类反馈进行强化学习,从而提升代码生成质量的问题。现有方法通常难以获取和整合高质量的人类反馈,导致模型训练效率低下,生成的代码与人类意图存在偏差。
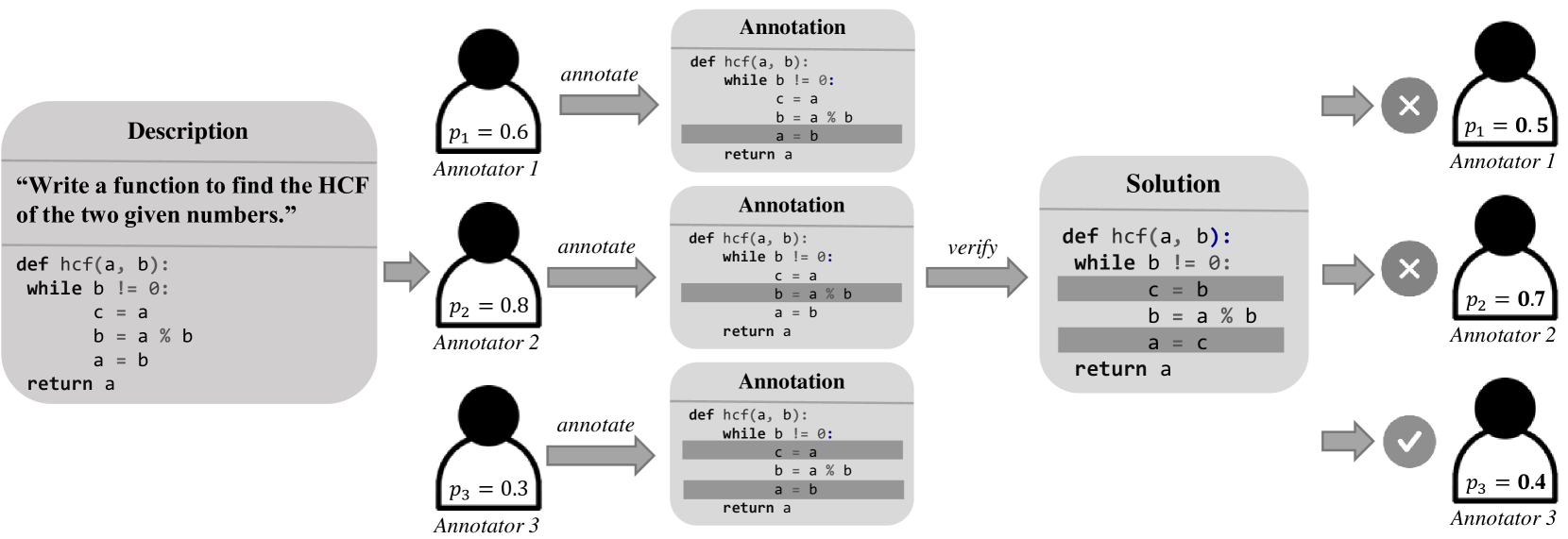
核心思路:论文的核心思路是利用贝叶斯优化框架,通过众包的方式收集人类反馈,并将其融入到强化学习过程中,从而实现LLM代码生成能力与人类意图的对齐。通过分散反馈收集的负担,可以更容易地获得高质量的反馈数据。
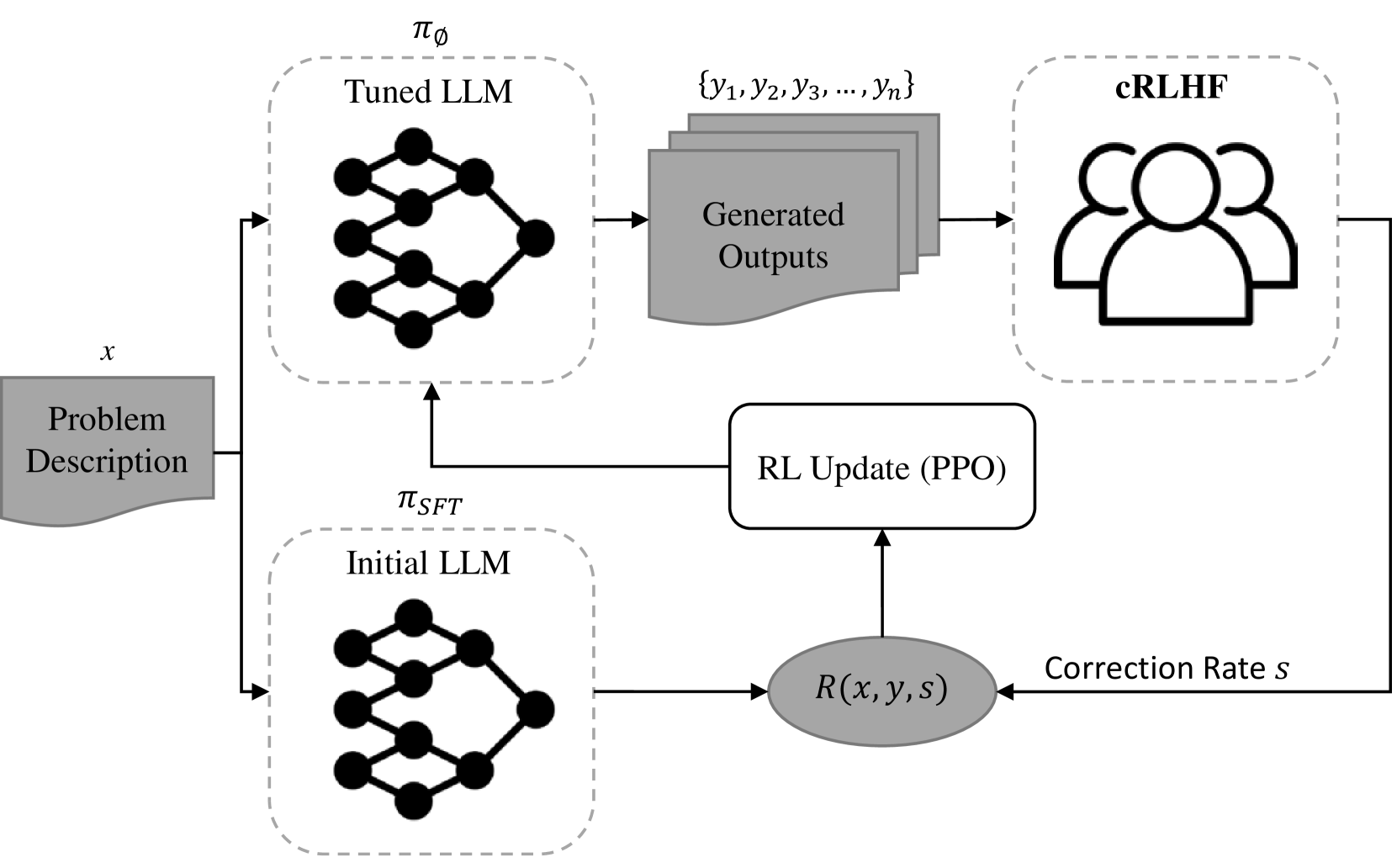
技术框架:整体框架包含以下几个主要阶段:1) LLM生成代码;2) 通过众包平台收集人类对生成代码的反馈(例如,代码质量、可读性、是否符合需求等);3) 利用贝叶斯优化算法选择下一批需要收集反馈的代码;4) 使用收集到的反馈数据训练强化学习模型,优化LLM的代码生成策略。该框架可以迭代进行,不断提升LLM的代码生成能力。
关键创新:论文的关键创新在于将贝叶斯优化与众包人类反馈相结合,用于指导LLM的代码生成强化学习过程。贝叶斯优化能够有效地探索反馈空间,选择信息量最大的样本进行标注,从而提高反馈数据的利用率和模型训练效率。
关键设计:论文中可能涉及的关键设计包括:1) 如何设计众包任务,以获取高质量的人类反馈;2) 如何选择合适的贝叶斯优化算法,以平衡探索和利用;3) 如何设计强化学习的奖励函数,将人类反馈转化为可优化的目标;4) 如何处理不同来源的反馈数据,例如,对不同标注者的反馈进行加权或过滤。
🖼️ 关键图片

📊 实验亮点
论文通过实验验证了所提出方法的有效性,展示了利用众包人类反馈和贝叶斯优化能够显著提升LLM在文本到代码生成任务中的性能。具体的性能数据和对比基线(如传统强化学习方法)的提升幅度需要在论文中查找。
🎯 应用场景
该研究成果可应用于各种AI辅助编程工具,如Github Copilot和Amazon CodeWhisperer,提升代码生成的准确性和效率,降低开发者的工作负担。此外,该方法还可推广到其他领域特定语言的代码生成任务中,具有广泛的应用前景和实际价值,有望加速软件开发进程。
📄 摘要(原文)
This paper studies how AI-assisted programming and large language models (LLM) improve software developers' ability via AI tools (LLM agents) like Github Copilot and Amazon CodeWhisperer, while integrating human feedback to enhance reinforcement learning (RLHF) with crowd-sourced computation to enhance text-to-code generation. Additionally, we demonstrate that our Bayesian optimization framework supports AI alignment in code generation by distributing the feedback collection burden, highlighting the value of collecting human feedback of good quality. Our empirical evaluations demonstrate the efficacy of this approach, showcasing how LLM agents can be effectively trained for improved text-to-code generation. Our Bayesian optimization framework can be designed for general domain-specific languages, promoting the alignment of large language model capabilities with human feedback in AI-assisted programming for code generation.