Reasoning Effort and Problem Complexity: A Scaling Analysis in LLMs
作者: Benjamin Estermann, Roger Wattenhofer
分类: cs.AI
发布日期: 2025-03-19
备注: Published at ICLR 2025 Workshop on Reasoning and Planning for LLMs
💡 一句话要点
利用Tents puzzle分析LLM推理能力随问题复杂度变化的趋势
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理能力 问题复杂度 Tents puzzle 缩放分析
📋 核心要点
- 现有LLM在复杂推理问题上存在逻辑连贯性不足的挑战,限制了其应用。
- 论文利用无限可扩展的Tents puzzle,分析LLM推理工作量随问题复杂度的变化。
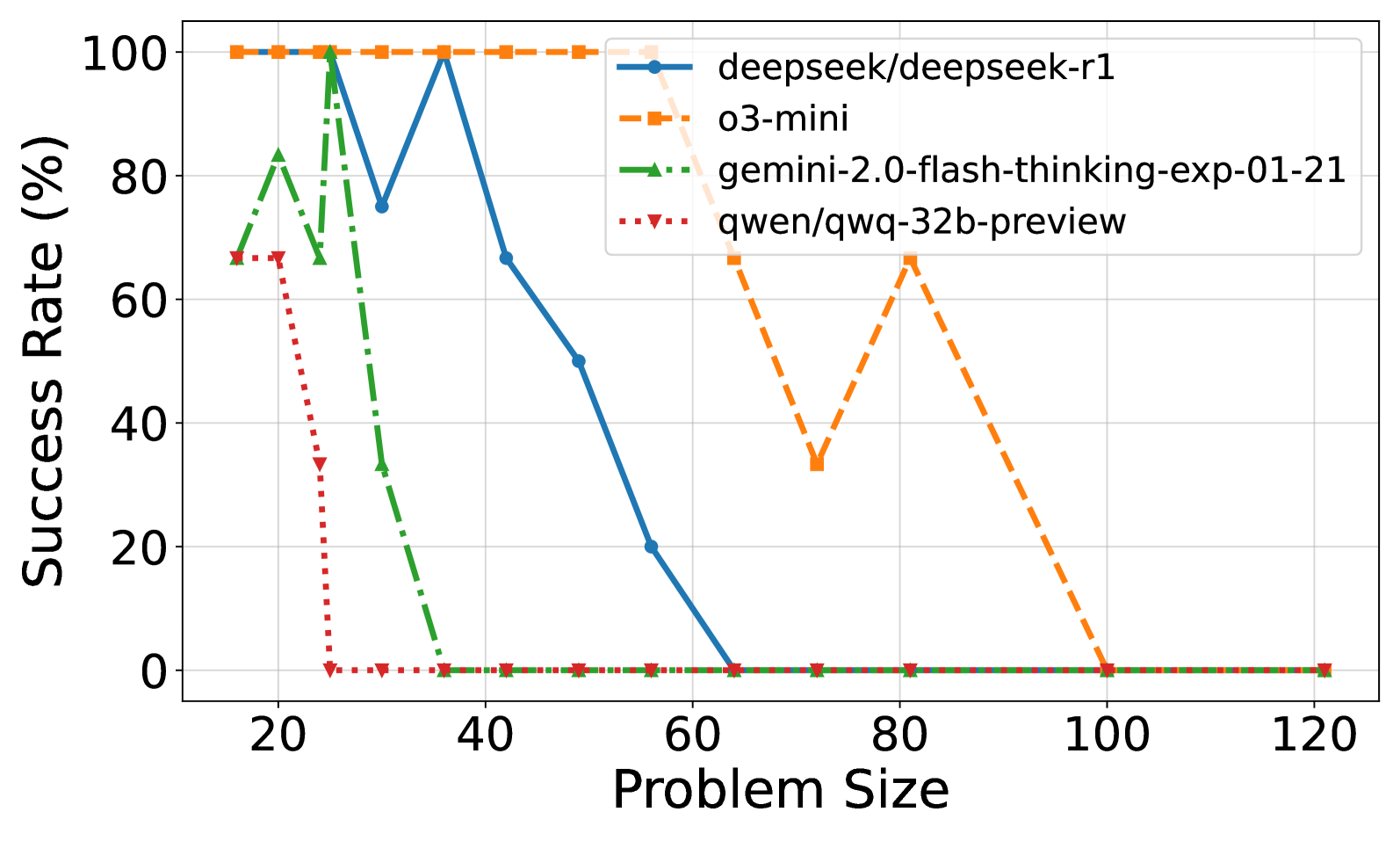
- 实验发现推理工作量随问题复杂度增加,但存在阈值,超过阈值后推理能力反而下降。
📝 摘要(中文)
大型语言模型(LLM)在文本生成方面表现出卓越的能力,并且训练范式的最新进展已经导致其推理性能的突破。在这项工作中,我们研究了此类模型的推理工作量如何随问题复杂度而变化。我们使用无限可扩展的Tents puzzle,它具有已知的线性时间解,来分析这种缩放行为。我们的结果表明,推理工作量随问题大小而增加,但仅达到临界问题复杂度。超过此阈值,推理工作量不会继续增加,甚至可能减少。这一观察结果突出了当前LLM在问题复杂度增加时逻辑连贯性的一个关键限制,并强调了改进推理可扩展性的策略的需求。此外,我们的结果揭示了当前最先进的推理模型在面对日益复杂的逻辑难题时,存在显着的性能差异。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)的推理能力如何随着问题复杂度的增加而变化。现有方法在评估LLM的推理能力时,往往缺乏对问题复杂度与推理工作量之间关系的深入分析,难以揭示LLM在处理复杂问题时的局限性。
核心思路:论文的核心思路是使用一个无限可扩展的逻辑谜题——Tents puzzle,作为评估LLM推理能力的基准。Tents puzzle具有已知的线性时间解,可以精确控制问题的复杂度,从而分析LLM在不同复杂度下的推理表现。通过观察推理工作量与问题复杂度之间的关系,可以揭示LLM在处理复杂问题时的瓶颈。
技术框架:该研究的技术框架主要包括以下几个步骤: 1. 问题生成:生成不同复杂度的Tents puzzle实例。 2. 模型推理:使用不同的LLM对生成的puzzle进行求解。 3. 性能评估:评估LLM在不同复杂度puzzle上的求解准确率和推理时间。 4. 缩放分析:分析推理工作量(例如推理时间)与问题复杂度之间的关系,揭示LLM的推理能力缩放规律。
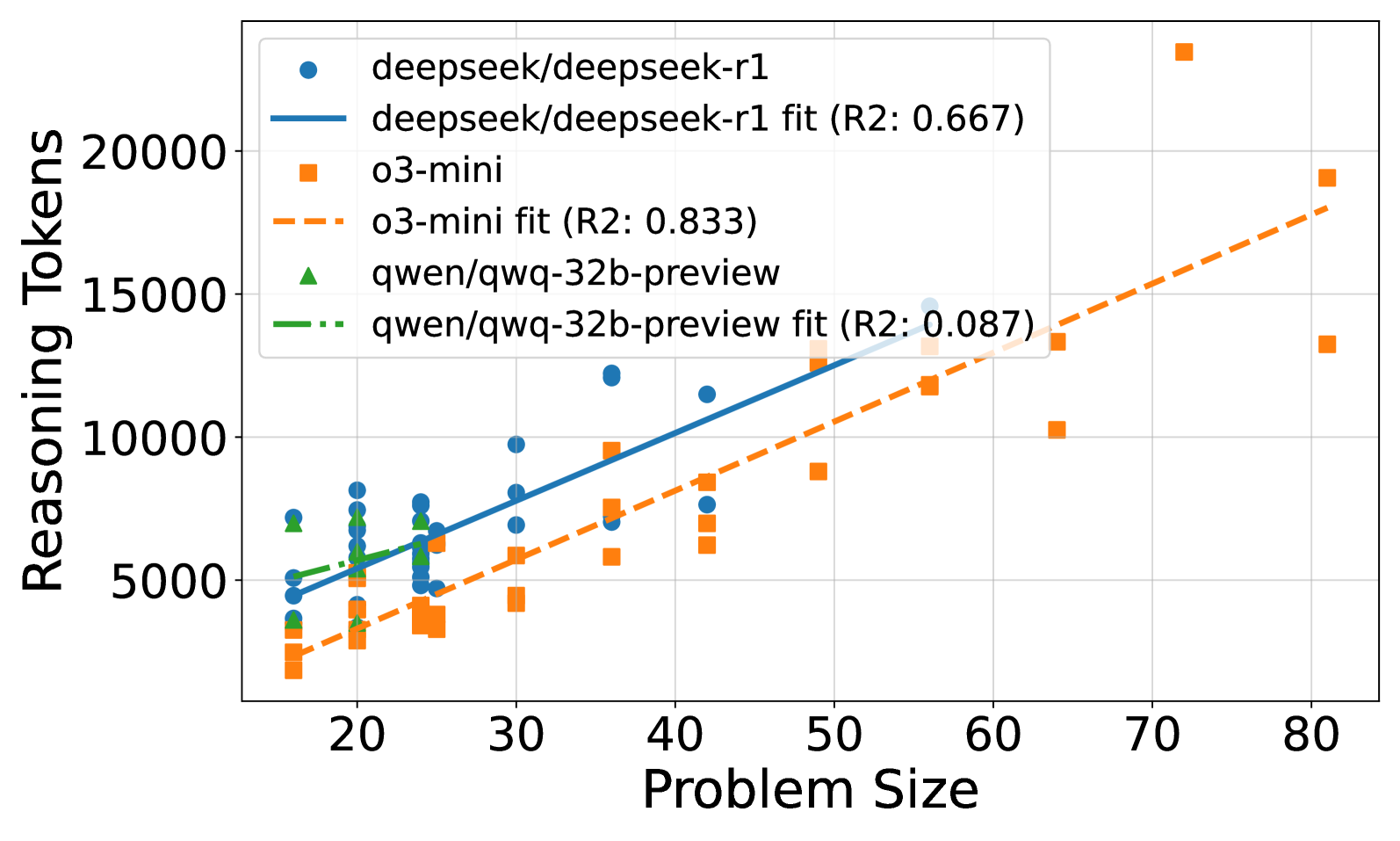
关键创新:该论文的关键创新在于: 1. 使用Tents puzzle作为评估LLM推理能力的基准:Tents puzzle具有无限可扩展性和已知的线性时间解,可以精确控制问题复杂度,为评估LLM的推理能力提供了一个理想的平台。 2. 揭示了LLM推理能力随问题复杂度变化的非线性关系:实验结果表明,LLM的推理工作量随问题复杂度增加,但存在一个阈值,超过该阈值后,推理能力反而下降。
关键设计:论文的关键设计包括: 1. Tents puzzle的生成算法:设计了能够生成不同复杂度Tents puzzle实例的算法,确保puzzle的难度可控。 2. 推理工作量的度量:使用推理时间作为推理工作量的度量指标,更直接地反映了LLM在解决问题时所消耗的计算资源。 3. 实验模型的选择:选择了当前最先进的推理模型进行实验,以评估不同模型在面对复杂逻辑难题时的性能差异。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LLM的推理工作量随Tents puzzle的复杂度增加而增加,但存在一个临界值。超过该临界值后,推理工作量不再增加,甚至可能减少,表明LLM的推理能力受到限制。此外,不同LLM在面对日益复杂的逻辑难题时,表现出显著的性能差异,突出了模型架构和训练方法对推理能力的影响。
🎯 应用场景
该研究成果可应用于评估和改进大型语言模型的推理能力,尤其是在需要复杂逻辑推理的领域,如智能问答、自动编程、科学发现等。通过了解LLM推理能力的局限性,可以指导模型设计者开发更有效的推理算法和训练策略,提升LLM在实际应用中的性能。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable text generation capabilities, and recent advances in training paradigms have led to breakthroughs in their reasoning performance. In this work, we investigate how the reasoning effort of such models scales with problem complexity. We use the infinitely scalable Tents puzzle, which has a known linear-time solution, to analyze this scaling behavior. Our results show that reasoning effort scales with problem size, but only up to a critical problem complexity. Beyond this threshold, the reasoning effort does not continue to increase, and may even decrease. This observation highlights a critical limitation in the logical coherence of current LLMs as problem complexity increases, and underscores the need for strategies to improve reasoning scalability. Furthermore, our results reveal significant performance differences between current state-of-the-art reasoning models when faced with increasingly complex logical puzzles.