RAGO: Systematic Performance Optimization for Retrieval-Augmented Generation Serving
作者: Wenqi Jiang, Suvinay Subramanian, Cat Graves, Gustavo Alonso, Amir Yazdanbakhsh, Vidushi Dadu
分类: cs.IR, cs.AI, cs.CL, cs.DC
发布日期: 2025-03-18 (更新: 2025-03-21)
备注: 16 pages, 19 figures, 4 tables
💡 一句话要点
RAGO:面向检索增强生成服务的系统性性能优化框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 RAG 性能优化 LLM服务 系统优化
📋 核心要点
- 现有RAG系统面临性能挑战,原因是RAG算法多样且工作负载特征差异大,缺乏统一的优化方法。
- RAGO通过引入RAGSchema抽象不同RAG算法,并针对不同工作负载进行系统优化,提升RAG服务效率。
- 实验结果表明,RAGO相比现有RAG系统,在QPS和首个token延迟方面均有显著提升。
📝 摘要(中文)
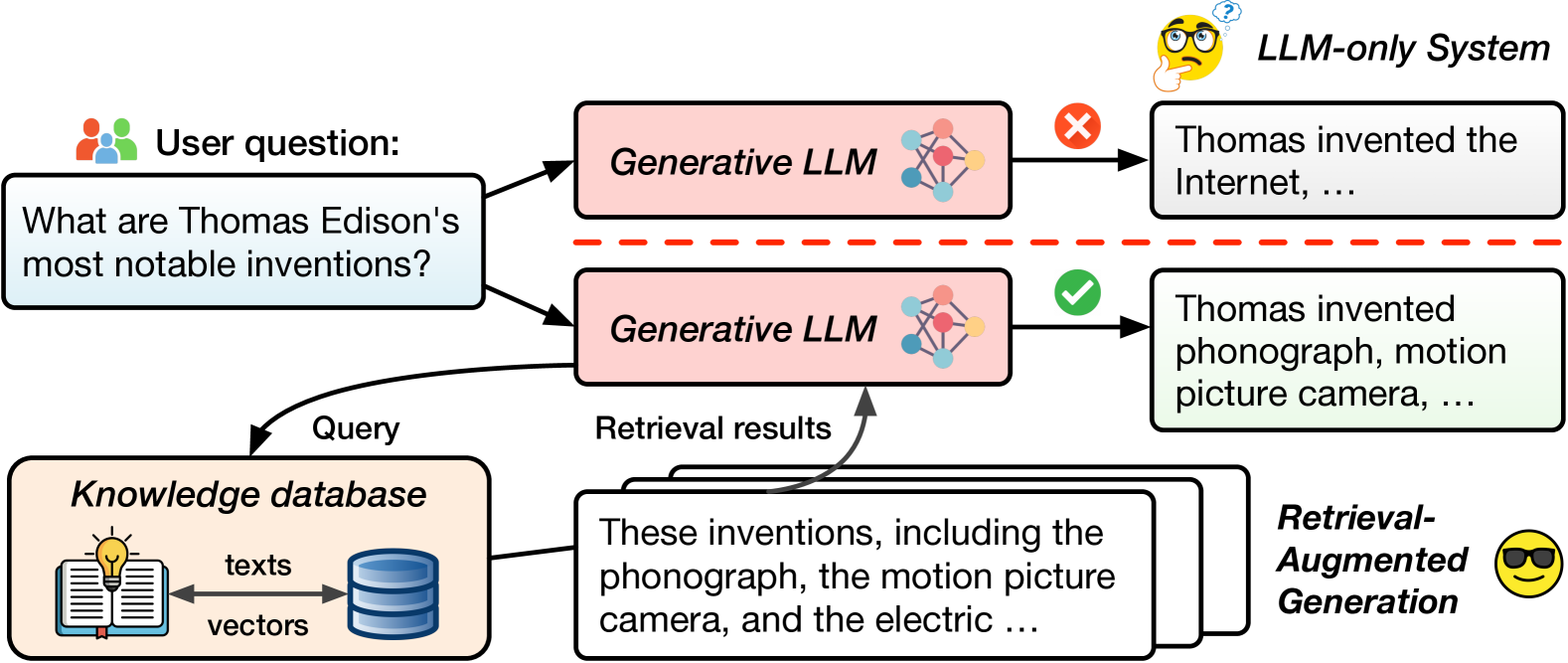
检索增强生成(RAG)结合了大型语言模型(LLM)和外部知识库的检索,正成为一种可靠的LLM服务方法。然而,由于RAG变体的快速涌现以及它们之间工作负载特征的显著差异,高效的RAG服务仍然是一个开放的挑战。本文为推进RAG服务做出了三个根本性贡献。首先,我们引入了RAGSchema,一种结构化的抽象,它捕获了广泛的RAG算法,作为性能优化的基础。其次,我们分析了几个具有不同RAGSchema的代表性RAG工作负载,揭示了这些工作负载之间显著的性能差异。第三,为了解决这种可变性并满足不同的性能需求,我们提出了RAGO(检索增强生成优化器),一个用于高效RAG服务的系统优化框架。我们的评估表明,与基于LLM系统扩展构建的RAG系统相比,RAGO实现了高达2倍的每芯片QPS提升和55%的time-to-first-token延迟降低。
🔬 方法详解
问题定义:现有RAG系统在服务时面临性能瓶颈,主要原因是RAG算法种类繁多,不同算法的工作负载特性差异巨大,缺乏一个通用的性能优化框架。现有的LLM系统扩展难以有效应对这种多样性,导致资源利用率低,延迟高。
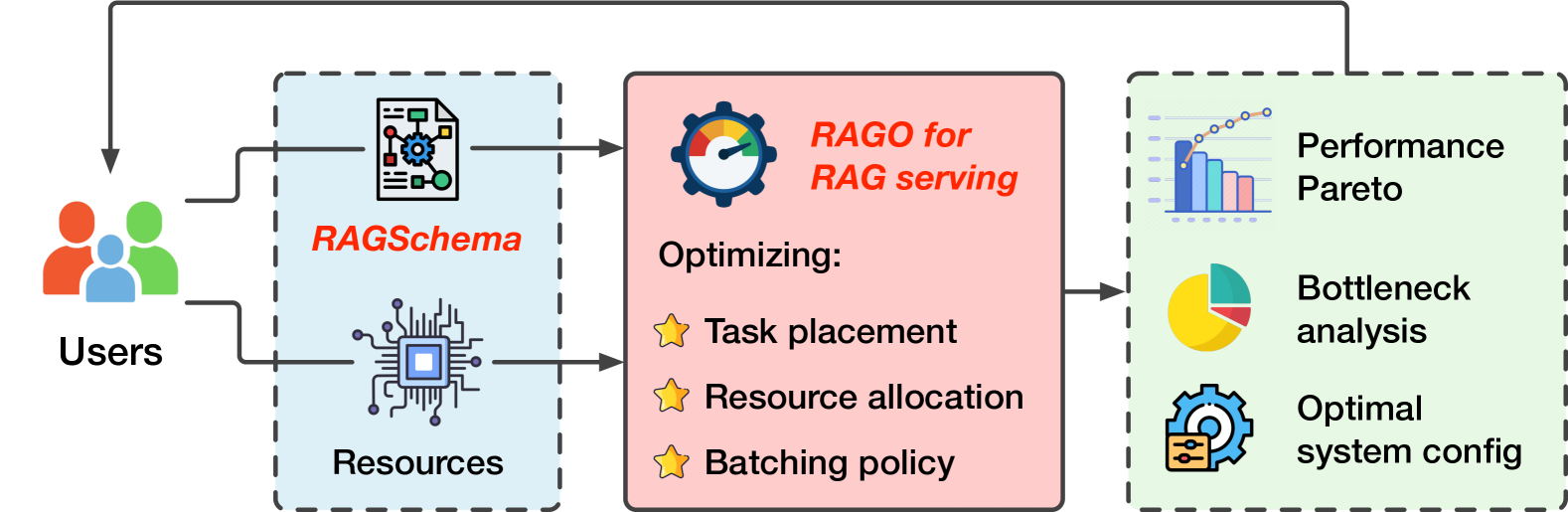
核心思路:RAGO的核心思路是首先对RAG算法进行抽象,提出RAGSchema,从而能够统一描述各种RAG流程。然后,通过分析不同RAGSchema的工作负载特性,针对性地进行系统优化,包括资源调度、任务划分、缓存策略等,以提高整体服务效率。
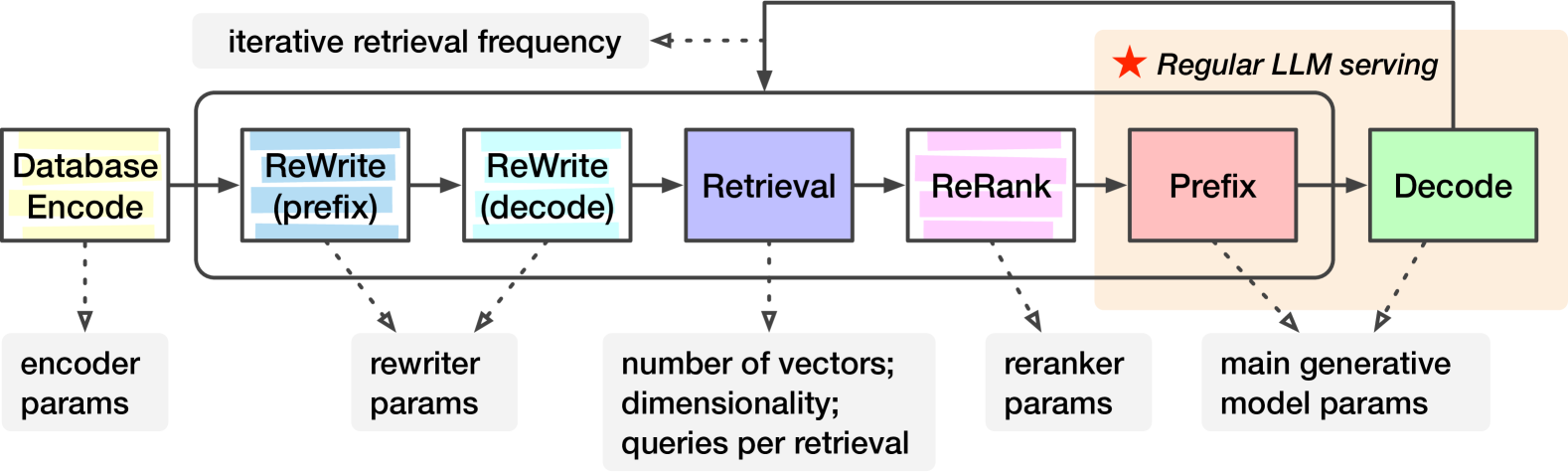
技术框架:RAGO框架主要包含以下几个模块:1) RAGSchema定义模块,用于描述不同RAG算法的流程;2) 工作负载分析模块,用于分析不同RAGSchema的性能瓶颈;3) 优化策略生成模块,基于分析结果生成优化策略;4) 运行时执行引擎,根据优化策略执行RAG流程。整体流程是从RAGSchema定义开始,经过工作负载分析和优化策略生成,最终在运行时执行引擎中实现高效的RAG服务。
关键创新:RAGO的关键创新在于RAGSchema的引入,它提供了一种结构化的方式来描述各种RAG算法,使得针对不同RAG流程的性能优化成为可能。与现有方法相比,RAGO不再将RAG视为一个黑盒,而是深入理解其内部流程,从而能够更有效地进行优化。
关键设计:RAGO的关键设计包括:1) RAGSchema的定义,需要覆盖各种RAG算法的关键步骤,例如检索、重排序、生成等;2) 工作负载分析模块,需要能够准确识别性能瓶颈,例如检索延迟、生成计算量等;3) 优化策略生成模块,需要能够根据分析结果生成有效的优化策略,例如缓存检索结果、并行执行生成任务等;4) 运行时执行引擎,需要能够高效地执行优化策略,例如动态调整资源分配、智能调度任务等。
🖼️ 关键图片
📊 实验亮点
RAGO的实验结果表明,与基于LLM系统扩展构建的RAG系统相比,RAGO实现了高达2倍的每芯片QPS提升和55%的time-to-first-token延迟降低。这些结果表明RAGO在提升RAG服务效率方面具有显著优势,能够有效应对不同RAG算法和工作负载带来的挑战。
🎯 应用场景
RAGO可应用于各种需要检索增强生成技术的场景,例如智能问答系统、知识库检索、文档摘要生成等。通过提升RAG服务的效率,RAGO可以降低服务成本,提高用户体验,并促进RAG技术在更多领域的应用。未来,RAGO可以进一步扩展到支持更多类型的RAG算法和工作负载,并与其他LLM系统集成,形成更强大的AI服务平台。
📄 摘要(原文)
Retrieval-augmented generation (RAG), which combines large language models (LLMs) with retrievals from external knowledge databases, is emerging as a popular approach for reliable LLM serving. However, efficient RAG serving remains an open challenge due to the rapid emergence of many RAG variants and the substantial differences in workload characteristics across them. In this paper, we make three fundamental contributions to advancing RAG serving. First, we introduce RAGSchema, a structured abstraction that captures the wide range of RAG algorithms, serving as a foundation for performance optimization. Second, we analyze several representative RAG workloads with distinct RAGSchema, revealing significant performance variability across these workloads. Third, to address this variability and meet diverse performance requirements, we propose RAGO (Retrieval-Augmented Generation Optimizer), a system optimization framework for efficient RAG serving. Our evaluation shows that RAGO achieves up to a 2x increase in QPS per chip and a 55% reduction in time-to-first-token latency compared to RAG systems built on LLM-system extensions.