Pauli Network Circuit Synthesis with Reinforcement Learning
作者: Ayushi Dubal, David Kremer, Simon Martiel, Victor Villar, Derek Wang, Juan Cruz-Benito
分类: quant-ph, cs.AI
发布日期: 2025-03-18
💡 一句话要点
提出基于强化学习的Pauli网络电路重构方法,显著降低量子门数量。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 量子电路优化 强化学习 量子编译 Pauli网络 量子门合成
📋 核心要点
- 现有量子电路合成方法在处理包含Pauli旋转的网络时,难以兼顾电路深度和硬件连接性约束。
- 该论文提出一种基于强化学习的电路重构方法,通过学习启发式策略逐步优化Pauli网络电路。
- 实验表明,该方法在减少双量子比特门数量和电路深度方面优于现有方法,并在实际量子计算任务中展现潜力。
📝 摘要(中文)
本文提出了一种基于强化学习(RL)的量子电路重构方法,用于优化包含任意Pauli旋转和Clifford操作的量子电路。该方法将每个子块压缩成紧凑的表示形式,然后通过学习到的启发式算法逐步合成。实验结果表明,该方法速度快、效果好,可作为一种优化程序。在6量子比特随机Pauli网络上的直接比较中,与最先进的启发式方法相比,我们的RL方法在双量子比特门数量上减少了2倍以上,且每个电路的执行时间不到10毫秒。此外,我们将该方法集成到收集和重构的流程中,作为Qiskit转译器pass应用,在Benchpress基准测试中,双量子比特门数量和深度平均提高了20%,许多实例甚至高达60%。这些结果突显了RL驱动的合成在实际大规模量子转译工作负载中显著提高电路质量的潜力。
🔬 方法详解
问题定义:论文旨在解决量子电路合成中,特别是包含任意Pauli旋转和Clifford操作的Pauli网络电路的优化问题。现有启发式方法在处理此类电路时,往往难以在电路深度、量子门数量和硬件连接性约束之间取得良好的平衡,导致电路质量不高,影响量子算法的实际性能。
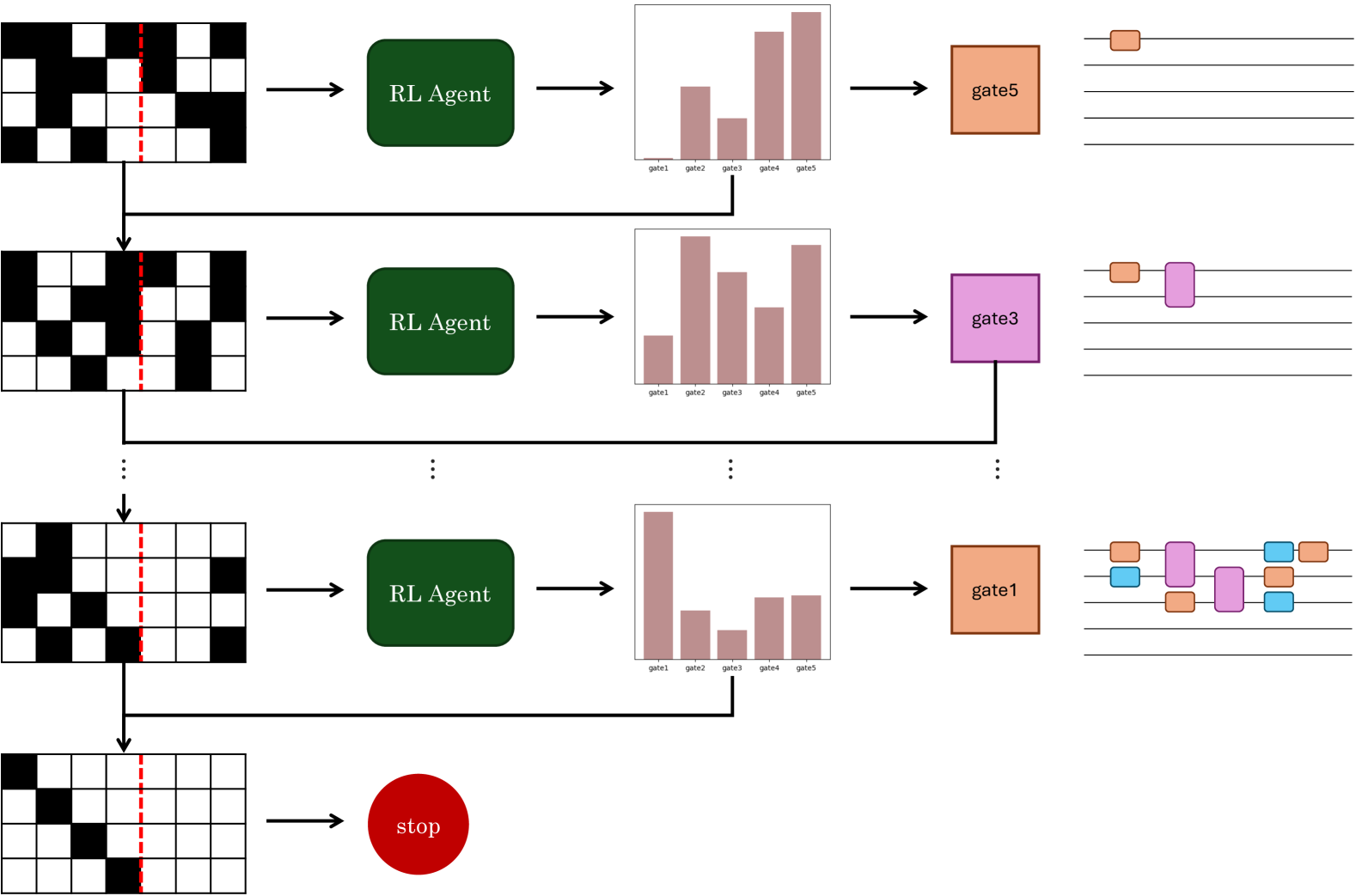
核心思路:论文的核心思路是利用强化学习(RL)来学习一种启发式策略,该策略能够逐步地将Pauli网络电路分解为更紧凑的形式,并根据硬件约束进行优化合成。通过与环境的交互学习,RL智能体能够找到更有效的电路重构方案,从而降低量子门数量和电路深度。
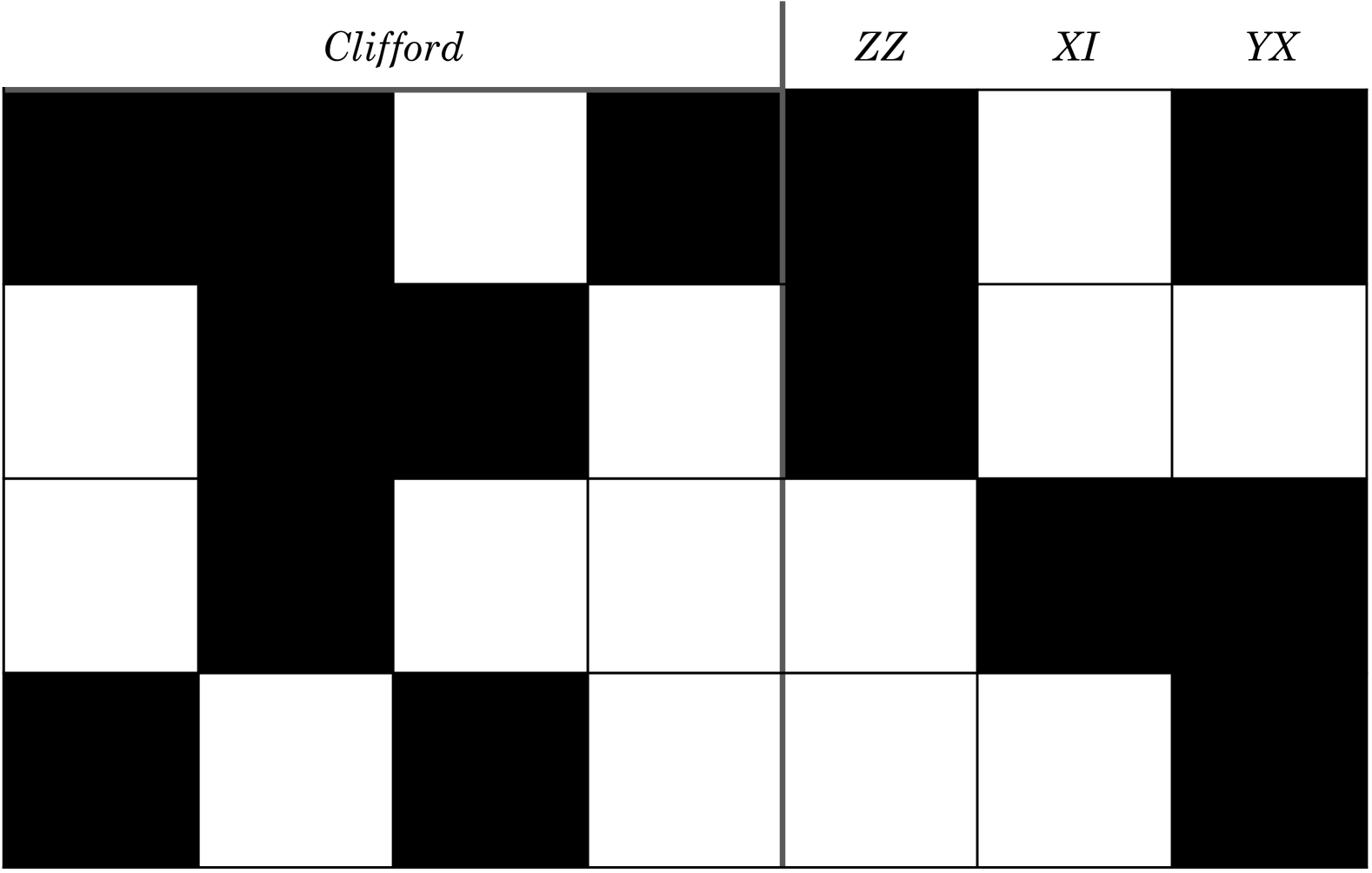
技术框架:整体流程包括以下几个阶段:1) 将原始量子电路分解为包含Pauli旋转和Clifford操作的子块;2) 将每个子块压缩成紧凑的表示形式,作为RL智能体的输入状态;3) RL智能体根据当前状态选择一个动作(例如,应用一个特定的量子门);4) 环境执行该动作,并返回新的状态和奖励;5) RL智能体根据奖励更新其策略,重复步骤3和4,直到电路被完全合成。最终,将优化后的子块重新组合成完整的量子电路。该方法被集成到Qiskit转译器中,作为一个优化pass。
关键创新:该方法最重要的创新在于利用强化学习来指导量子电路的合成过程。与传统的启发式方法相比,RL方法能够通过学习自动地发现更优的电路重构策略,而无需人工设计复杂的规则。此外,该方法能够根据特定的硬件约束进行优化,从而提高电路在实际量子计算机上的执行效率。
关键设计:论文中使用了深度Q网络(DQN)作为RL智能体的核心。状态表示包括子块的紧凑表示,动作空间对应于可应用的量子门集合。奖励函数的设计至关重要,它需要能够引导智能体朝着减少量子门数量和满足硬件约束的方向进行优化。具体的奖励函数设计细节未知,但推测可能包括对减少量子门数量的负奖励,以及对违反硬件约束的惩罚。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在6量子比特随机Pauli网络上,与最先进的启发式方法相比,双量子比特门数量减少了2倍以上,且每个电路的执行时间不到10毫秒。在Benchpress基准测试中,该方法作为Qiskit转译器pass应用,双量子比特门数量和深度平均提高了20%,许多实例甚至高达60%。
🎯 应用场景
该研究成果可应用于量子算法的优化和量子编译器的改进,尤其是在需要处理大量Pauli旋转的量子算法中,例如量子化学模拟、量子机器学习等。通过降低量子门数量和电路深度,可以提高量子算法在实际量子计算机上的运行效率和精度,加速量子计算的发展。
📄 摘要(原文)
We introduce a Reinforcement Learning (RL)-based method for re-synthesis of quantum circuits containing arbitrary Pauli rotations alongside Clifford operations. By collapsing each sub-block to a compact representation and then synthesizing it step-by-step through a learned heuristic, we obtain circuits that are both shorter and compliant with hardware connectivity constraints. We find that the method is fast enough and good enough to work as an optimization procedure: in direct comparisons on 6-qubit random Pauli Networks against state-of-the-art heuristic methods, our RL approach yields over 2x reduction in two-qubit gate count, while executing in under 10 milliseconds per circuit. We further integrate the method into a collect-and-re-synthesize pipeline, applied as a Qiskit transpiler pass, where we observe average improvements of 20% in two-qubit gate count and depth, reaching up to 60% for many instances, across the Benchpress benchmark. These results highlight the potential of RL-driven synthesis to significantly improve circuit quality in realistic, large-scale quantum transpilation workloads.