Can LLMs Enable Verification in Mainstream Programming?
作者: Aleksandr Shefer, Igor Engel, Stanislav Alekseev, Daniil Berezun, Ekaterina Verbitskaia, Anton Podkopaev
分类: cs.SE, cs.AI, cs.PL
发布日期: 2025-03-18
💡 一句话要点
探索LLM在主流编程中实现代码验证的能力,提升软件可靠性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 形式化验证 代码生成 软件可靠性 Dafny Nagini Verus
📋 核心要点
- 形式化验证方法在软件开发中应用有限,难以保证代码的可靠性。
- 利用LLM自动生成代码,并探索其在Dafny、Nagini和Verus等验证语言中生成可验证代码的能力。
- 通过在HumanEval数据集上进行实验,评估不同信息输入对LLM生成高质量验证代码的影响。
📝 摘要(中文)
尽管形式化方法能够生成可靠的软件,但它们在日常编程中的应用却很少。利用大型语言模型进行自动代码生成正变得越来越普遍,但很少考虑产生强大的正确性保证。本研究探讨了LLM在三种验证语言(Dafny、Nagini和Verus)中生成经过验证的代码的能力。为此,我们使用了从最先进的Python基准HumanEval中手动整理的数据集。我们还评估了哪些类型的信息足以获得高质量的结果。
🔬 方法详解
问题定义:论文旨在解决主流编程中形式化验证方法应用不足,以及LLM自动代码生成缺乏可靠性保证的问题。现有方法难以在日常编程中普及形式化验证,并且LLM生成的代码通常缺乏严格的正确性证明。
核心思路:论文的核心思路是利用LLM的强大代码生成能力,结合形式化验证语言,自动生成带有正确性证明的代码。通过精心设计的提示工程和数据集,引导LLM生成满足验证器要求的代码。
技术框架:该研究的技术框架主要包括以下几个部分:1) 选择Dafny、Nagini和Verus三种验证语言作为目标;2) 基于HumanEval数据集,人工构建包含验证信息的代码数据集;3) 使用LLM(具体模型未知)进行代码生成,并评估生成代码的可验证性;4) 分析不同类型的输入信息对生成结果的影响。
关键创新:该研究的关键创新在于探索了LLM在形式化验证领域的应用潜力,并尝试将LLM的代码生成能力与形式化验证工具相结合,以期实现自动生成可靠代码的目标。与传统方法相比,该方法无需人工编写大量的形式化规约,降低了形式化验证的门槛。
关键设计:论文的关键设计包括:1) 数据集的构建,需要人工添加验证信息,例如前置条件、后置条件和循环不变式等;2) 提示工程的设计,需要考虑如何引导LLM生成满足验证器要求的代码;3) 评估指标的选择,需要能够准确衡量生成代码的可验证性和正确性。具体的参数设置、损失函数、网络结构等技术细节在论文中未提及,属于未知信息。
🖼️ 关键图片

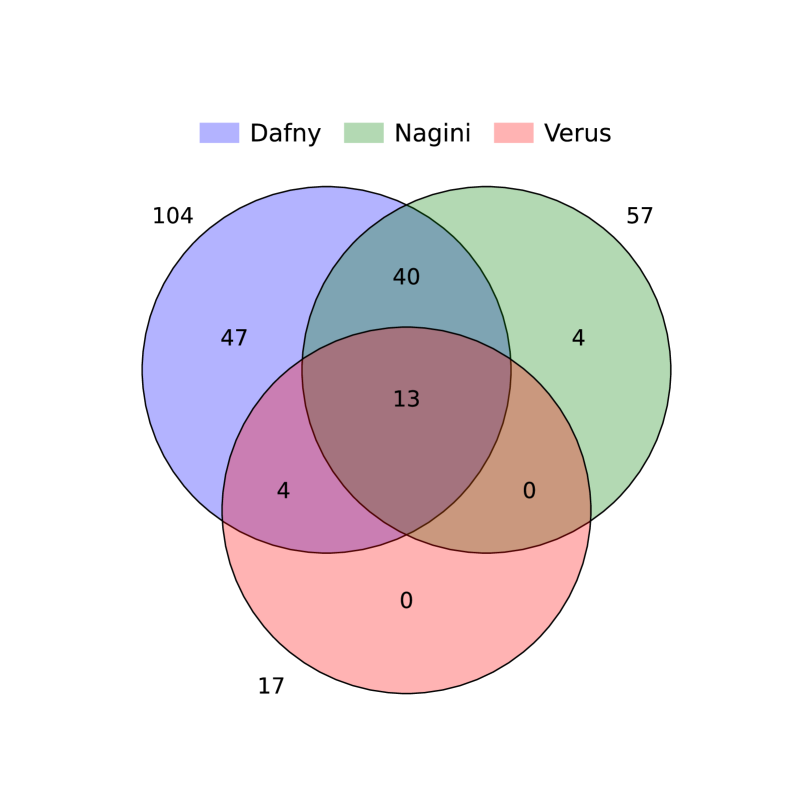
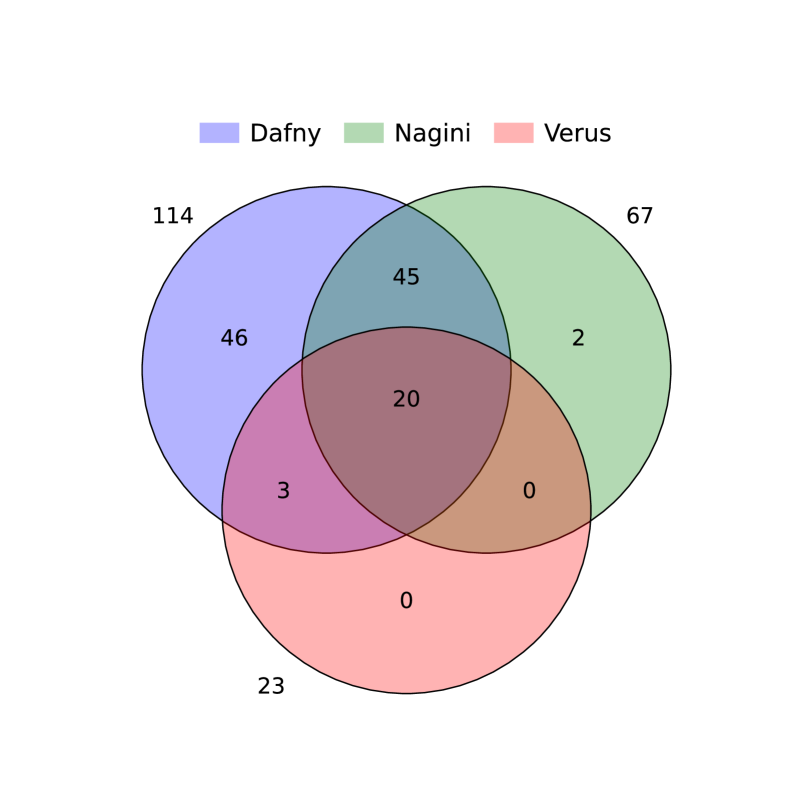
📊 实验亮点
论文通过实验验证了LLM在生成可验证代码方面的潜力。虽然具体的性能数据和提升幅度未知,但该研究表明,通过合适的提示工程和数据集,LLM可以生成满足Dafny、Nagini和Verus等验证器要求的代码。这项工作为利用LLM进行形式化验证开辟了新的方向。
🎯 应用场景
该研究的潜在应用领域包括软件安全、嵌入式系统、金融系统等对可靠性要求极高的领域。通过自动生成经过验证的代码,可以显著降低软件开发成本,提高软件质量,并减少潜在的安全漏洞。未来,该技术有望应用于更广泛的编程领域,推动形式化验证的普及。
📄 摘要(原文)
Although formal methods are capable of producing reliable software, they have seen minimal adoption in everyday programming. Automatic code generation using large language models is becoming increasingly widespread, but it rarely considers producing strong correctness guarantees. In this study, we explore the ability of LLMs to produce verified code in three verification languages (Dafny, Nagini, and Verus). To do so, we use manually curated datasets derived from the state-ofthe-art Python benchmark, HumanEval. We also assess what types of information are sufficient to achieve good-quality results.