VARP: Reinforcement Learning from Vision-Language Model Feedback with Agent Regularized Preferences
作者: Anukriti Singh, Amisha Bhaskar, Peihong Yu, Souradip Chakraborty, Ruthwik Dasyam, Amrit Bedi, Pratap Tokekar
分类: cs.AI, cs.HC, cs.LG, cs.RO
发布日期: 2025-03-18
备注: 8 pages
💡 一句话要点
VARP:利用视觉-语言模型反馈和智能体正则化偏好进行强化学习,提升机器人控制性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 偏好学习 视觉-语言模型 机器人控制 奖励函数设计
📋 核心要点
- 连续控制机器人任务中,人工设计的奖励函数容易出现偏差或被智能体利用,难以适应复杂任务。
- VARP方法通过叠加轨迹草图增强视觉信息,并利用智能体性能正则化奖励学习,提升反馈准确性和策略对齐。
- 实验表明,VARP在Metaworld任务中显著提升了成功率和episode回报,验证了其有效性。
📝 摘要(中文)
在连续控制机器人任务中,设计奖励函数容易出现偏差或奖励利用问题,尤其是在复杂任务中。基于偏好的强化学习通过从比较反馈中学习奖励来缓解这些问题,但扩展人工标注仍然具有挑战性。本文提出了一种两部分解决方案,旨在提高反馈准确性并使奖励学习与智能体的策略更好地对齐。首先,通过在最终观察结果上叠加轨迹草图来揭示智能体的运动路径,使视觉-语言模型能够提供更可靠的偏好,在Metaworld任务中将偏好准确率提高了约15-20%。其次,通过结合智能体的性能来正则化奖励学习,确保奖励模型基于当前策略生成的数据进行优化,在运动任务中将episode回报提高了20-30%。在Metaworld上的实验表明,该方法在所有任务中实现了约70-80%的成功率,而标准方法的成功率低于50%。这些结果表明,将更丰富的视觉表示与智能体感知的奖励正则化相结合是有效的。
🔬 方法详解
问题定义:现有强化学习方法在机器人控制任务中,依赖人工设计的奖励函数,这往往导致奖励函数与任务目标不完全一致,或者被智能体以非预期的方式利用(reward hacking)。基于偏好的强化学习试图通过人类反馈来学习奖励函数,但获取足够的人工标注成本高昂。利用视觉-语言模型(VLM)自动生成偏好标签是一种有潜力的替代方案,但仅依赖最终状态图像难以准确评估整个轨迹的优劣。
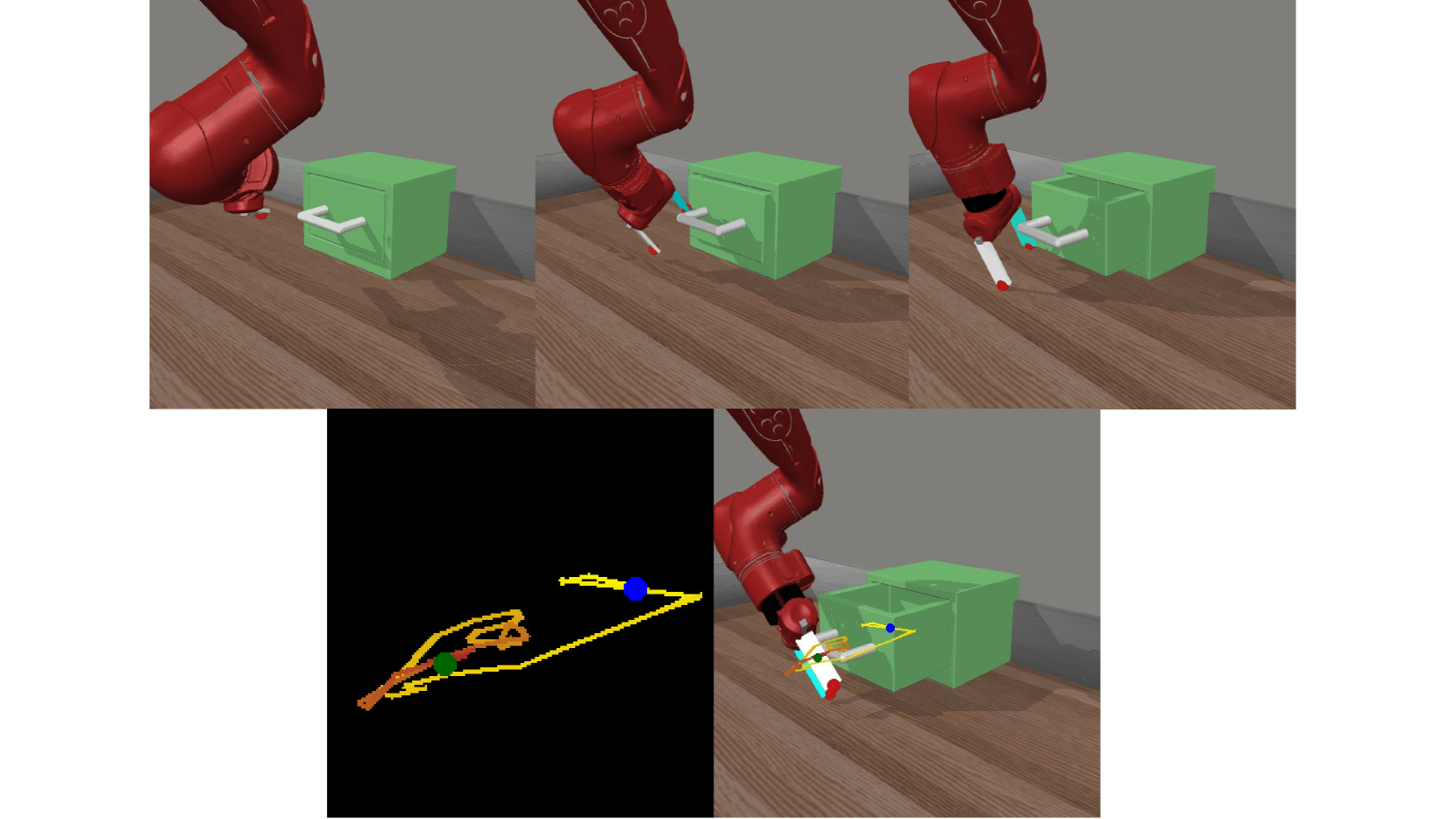
核心思路:本文的核心思路是改进VLM生成偏好标签的准确性,并使奖励学习过程更好地与智能体的策略对齐。具体来说,通过在最终状态图像上叠加轨迹草图,为VLM提供更丰富的运动信息,从而提高偏好判断的准确性。同时,引入智能体性能的正则化项,确保奖励模型能够基于智能体当前策略产生的数据进行优化,避免奖励模型偏离智能体的实际能力。
技术框架:VARP方法包含两个主要组成部分:1) 轨迹草图增强的偏好标签生成:在最终状态图像上叠加智能体的运动轨迹草图,形成增强的视觉输入,输入到VLM中,由VLM生成偏好标签。2) 智能体正则化的奖励学习:在奖励学习过程中,引入一个正则化项,该正则化项基于智能体的性能(例如,episode回报)来约束奖励模型的学习,确保奖励模型能够更好地反映智能体的实际能力。整体流程是,智能体与环境交互产生轨迹数据,轨迹数据经过轨迹草图增强后,由VLM生成偏好标签,然后利用偏好标签和智能体性能正则化项来训练奖励模型,最后使用学习到的奖励模型来训练智能体的策略。
关键创新:本文的关键创新在于:1) 提出了一种轨迹草图增强的偏好标签生成方法,通过为VLM提供更丰富的运动信息,显著提高了偏好标签的准确性。2) 提出了一种智能体正则化的奖励学习方法,通过将智能体的性能纳入奖励学习过程中,使奖励模型能够更好地与智能体的策略对齐。
关键设计:轨迹草图的生成方式是将智能体在episode中的运动轨迹投影到最终状态图像上,形成一条或多条线段。VLM可以使用预训练的视觉-语言模型,例如CLIP。智能体性能正则化项可以使用episode回报的指数移动平均值。奖励模型的损失函数可以包括偏好损失(例如,Bradley-Terry损失)和智能体性能正则化项。智能体的策略可以使用任何标准的强化学习算法,例如PPO或SAC。
🖼️ 关键图片

📊 实验亮点
实验结果表明,VARP方法在Metaworld任务中显著提升了性能。例如,在所有任务中,VARP的成功率达到了70-80%,而标准方法的成功率低于50%。在运动任务中,VARP将episode回报提高了20-30%。这些结果表明,VARP方法能够有效地提高机器人控制任务的性能。
🎯 应用场景
该研究成果可应用于各种需要复杂奖励函数设计的机器人控制任务,例如家庭服务机器人、工业自动化机器人、自动驾驶等。通过利用视觉-语言模型和智能体正则化,可以降低人工设计奖励函数的难度,提高机器人的学习效率和性能,从而加速机器人在实际场景中的应用。
📄 摘要(原文)
Designing reward functions for continuous-control robotics often leads to subtle misalignments or reward hacking, especially in complex tasks. Preference-based RL mitigates some of these pitfalls by learning rewards from comparative feedback rather than hand-crafted signals, yet scaling human annotations remains challenging. Recent work uses Vision-Language Models (VLMs) to automate preference labeling, but a single final-state image generally fails to capture the agent's full motion. In this paper, we present a two-part solution that both improves feedback accuracy and better aligns reward learning with the agent's policy. First, we overlay trajectory sketches on final observations to reveal the path taken, allowing VLMs to provide more reliable preferences-improving preference accuracy by approximately 15-20% in metaworld tasks. Second, we regularize reward learning by incorporating the agent's performance, ensuring that the reward model is optimized based on data generated by the current policy; this addition boosts episode returns by 20-30% in locomotion tasks. Empirical studies on metaworld demonstrate that our method achieves, for instance, around 70-80% success rate in all tasks, compared to below 50% for standard approaches. These results underscore the efficacy of combining richer visual representations with agent-aware reward regularization.