Identifying Cooperative Personalities in Multi-agent Contexts through Personality Steering with Representation Engineering
作者: Kenneth J. K. Ong, Lye Jia Jun, Hieu Minh "Jord" Nguyen, Seong Hah Cho, Natalia Pérez-Campanero Antolín
分类: cs.AI, cs.CL, cs.GT, cs.MA
发布日期: 2025-03-17
备注: Poster, Technical AI Safety Conference 2025
💡 一句话要点
通过人格引导和表征工程,识别多智能体环境中的合作人格
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 多智能体系统 合作博弈 人格引导 表征工程
📋 核心要点
- 大型语言模型在多智能体协作中面临合作难题,导致整体性能下降,现有方法缺乏有效的人格化引导。
- 该论文利用表征工程,在LLM中注入特定的人格特质(如宜人性和尽责性),以影响其在合作博弈中的决策。
- 实验结果表明,提高LLM的宜人性和尽责性可以增强合作行为,但也使其更容易受到剥削,揭示了人格引导的双刃剑效应。
📝 摘要(中文)
随着大型语言模型(LLMs)获得自主能力,它们在多智能体环境中的协调变得越来越重要。然而,它们常常在合作方面表现不佳,导致次优结果。受到Axelrod的迭代囚徒困境(IPD)锦标赛的启发,我们探索了人格特质如何影响LLM的合作。通过表征工程,我们在LLM中引导大五人格特质(例如,宜人性、尽责性),并分析它们对IPD决策的影响。我们的结果表明,较高的宜人性和尽责性可以提高合作性,但也会增加被利用的可能性,突出了基于人格的引导在对齐AI智能体方面的潜力和局限性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在多智能体环境中合作能力不足的问题。现有的LLM在合作博弈中常常表现出次优行为,缺乏稳定和高效的合作策略。现有的方法通常难以有效引导LLM展现出期望的合作人格,从而限制了其在复杂协作场景中的应用。
核心思路:论文的核心思路是通过人格引导来影响LLM的合作行为。具体来说,通过表征工程技术,在LLM的内部表征中注入特定的人格特质(例如,宜人性、尽责性),从而改变LLM在决策时的偏好和行为模式。这种方法旨在使LLM能够展现出更具合作性的人格,从而在多智能体环境中实现更好的协作效果。
技术框架:论文的技术框架主要包括以下几个阶段:1) 选择合适的LLM作为基础模型;2) 定义需要引导的人格特质(例如,大五人格);3) 使用表征工程技术,在LLM的内部表征中注入这些人格特质;4) 在迭代囚徒困境(IPD)等合作博弈环境中测试和评估LLM的合作行为;5) 分析不同人格特质对合作行为的影响。
关键创新:论文的关键创新在于将表征工程应用于人格引导,从而影响LLM的合作行为。与传统的prompt工程或微调方法相比,表征工程能够更直接地操纵LLM的内部表征,从而更有效地控制其行为。此外,论文还深入分析了不同人格特质对合作行为的影响,揭示了合作的复杂性和潜在的风险(例如,被利用)。
关键设计:论文的关键设计包括:1) 使用特定算法(具体算法未知)进行表征工程,以在LLM中注入人格特质;2) 使用迭代囚徒困境(IPD)作为评估合作行为的基准环境;3) 设计合适的指标来衡量LLM的合作程度和被利用的程度;4) 对不同人格特质组合进行实验,以探索最佳的合作策略。具体的参数设置、损失函数和网络结构等技术细节在论文中可能有所描述,但摘要中未提及。
🖼️ 关键图片
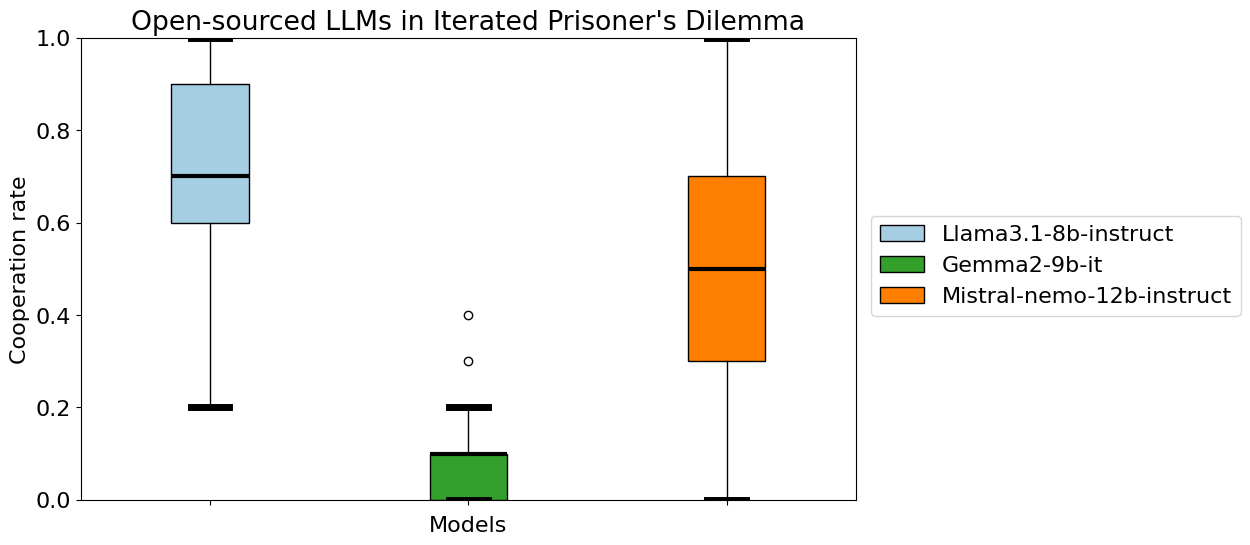
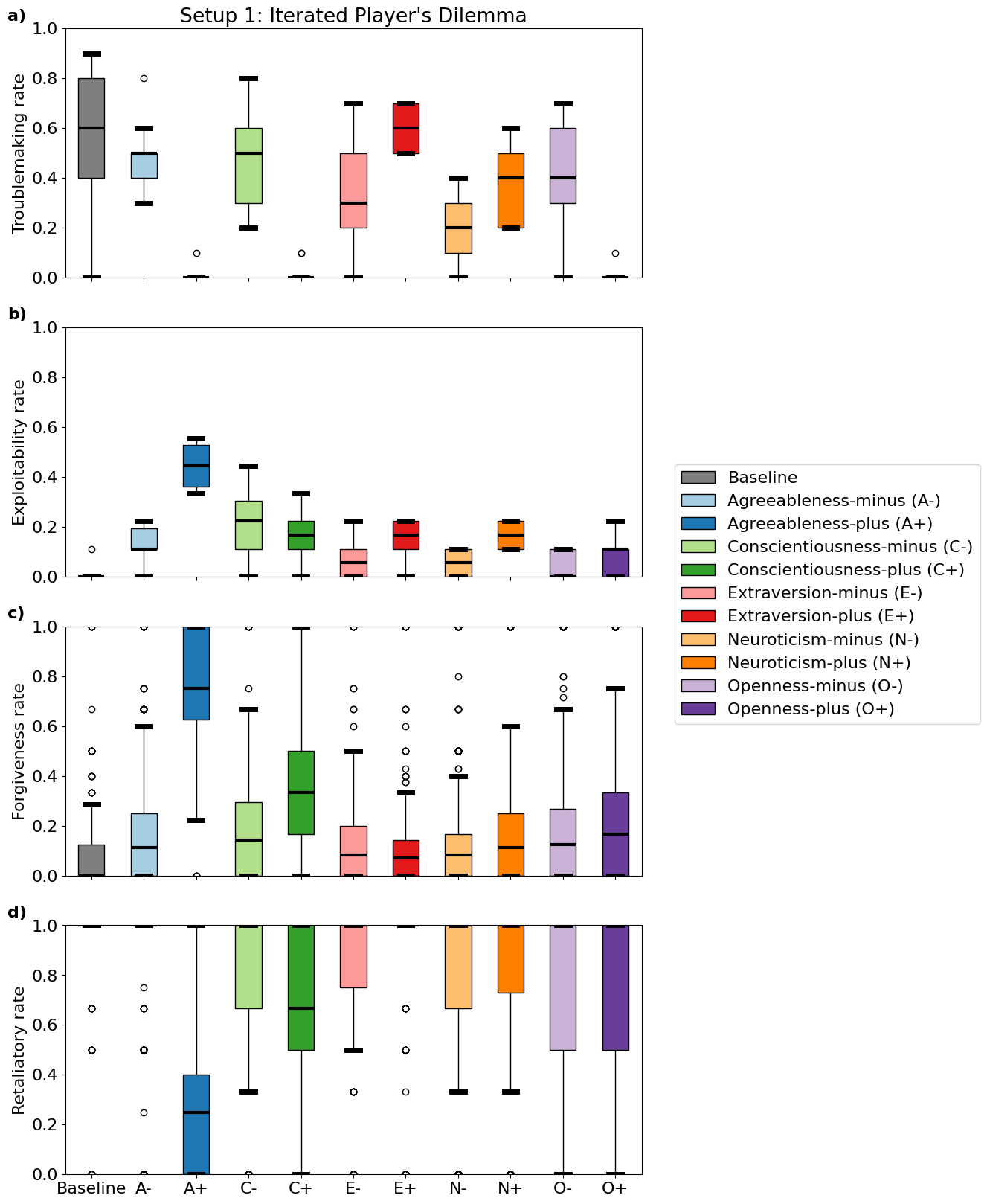
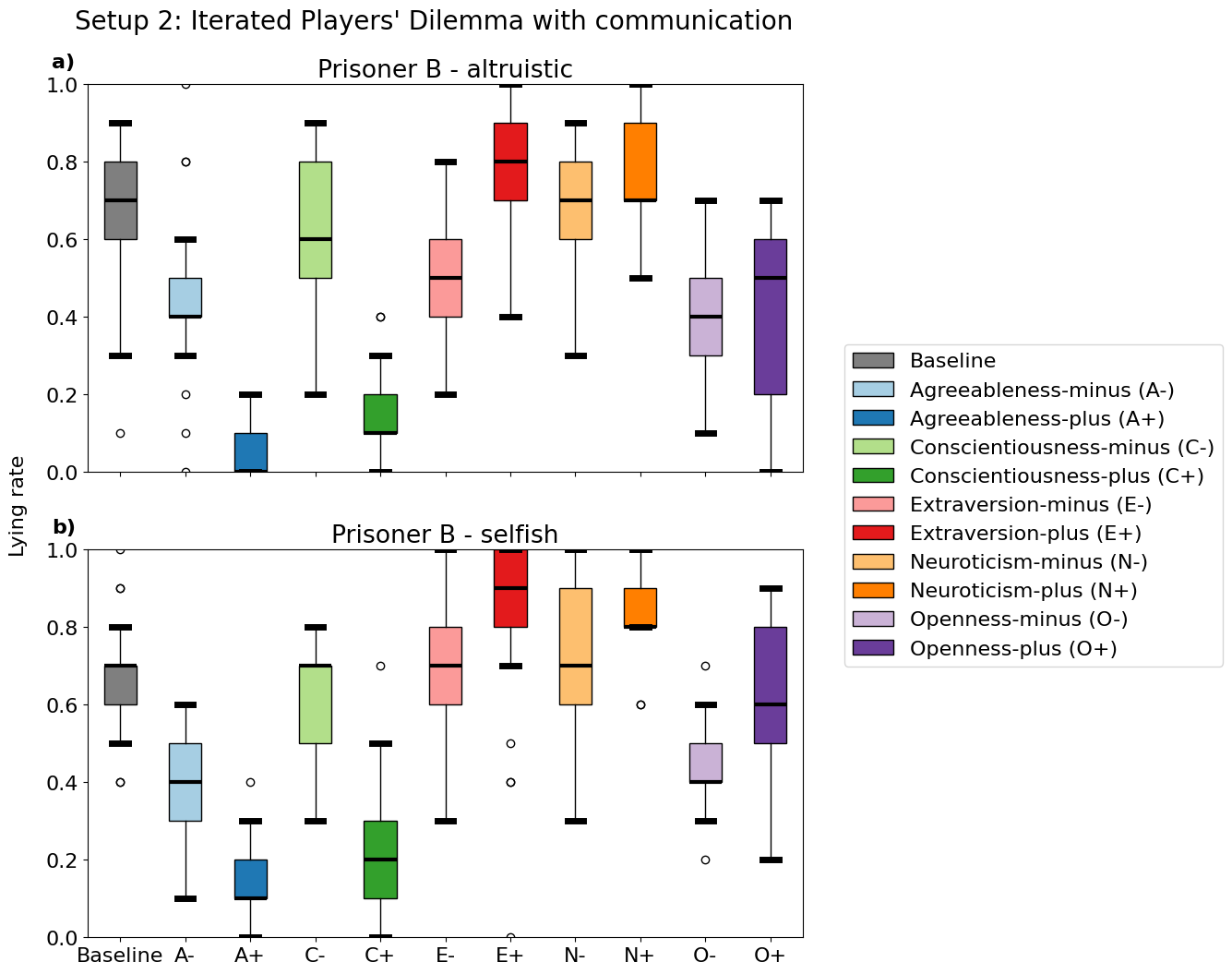
📊 实验亮点
实验结果表明,提高LLM的宜人性和尽责性可以显著提高其在迭代囚徒困境中的合作程度。然而,同时也发现,过高的宜人性会导致LLM更容易被其他智能体利用。这些结果揭示了人格特质与合作行为之间的复杂关系,为设计更有效的合作AI智能体提供了重要的指导。
🎯 应用场景
该研究成果可应用于开发更具协作性和可信赖的人工智能系统。例如,在自动驾驶、智能家居、客户服务等领域,可以通过人格引导使AI智能体更好地与人类或其他AI智能体进行协作,从而提高整体效率和用户满意度。此外,该研究还可以为AI伦理和安全提供新的视角,帮助我们更好地理解和控制AI的行为。
📄 摘要(原文)
As Large Language Models (LLMs) gain autonomous capabilities, their coordination in multi-agent settings becomes increasingly important. However, they often struggle with cooperation, leading to suboptimal outcomes. Inspired by Axelrod's Iterated Prisoner's Dilemma (IPD) tournaments, we explore how personality traits influence LLM cooperation. Using representation engineering, we steer Big Five traits (e.g., Agreeableness, Conscientiousness) in LLMs and analyze their impact on IPD decision-making. Our results show that higher Agreeableness and Conscientiousness improve cooperation but increase susceptibility to exploitation, highlighting both the potential and limitations of personality-based steering for aligning AI agents.