LLM-Mediated Guidance of MARL Systems
作者: Philipp D. Siedler, Ian Gemp
分类: cs.MA, cs.AI, cs.CL
发布日期: 2025-03-16
备注: 31 pages, 50 figures
💡 一句话要点
提出LLM引导的多智能体强化学习系统,提升复杂环境下的学习效率和性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体强化学习 大型语言模型 智能体引导 自然语言干预 规则干预
📋 核心要点
- 多智能体强化学习在复杂环境中面临学习效率和行为控制的挑战。
- 利用大型语言模型进行干预,引导智能体学习轨迹,实现更优行为。
- 实验表明,早期干预能显著提升训练效率和最终性能,优于无干预基线。
📝 摘要(中文)
在复杂的多智能体环境中,实现高效学习和理想行为对于多智能体强化学习(MARL)系统来说是一个重大挑战。本文探讨了将MARL与大型语言模型(LLM)介导的干预相结合,以引导智能体朝着更理想的行为发展的潜力。具体而言,我们研究了如何使用LLM来解释和促进干预,从而塑造多个智能体的学习轨迹。我们实验了两种类型的干预,称为控制器:自然语言(NL)控制器和基于规则(RB)的控制器。使用LLM模拟类人干预的NL控制器显示出比RB控制器更强的影响。我们的研究结果表明,智能体尤其受益于早期干预,从而实现更有效的训练和更高的性能。两种干预类型均优于没有干预的基线,突出了LLM介导的指导在加速训练和增强具有挑战性环境中的MARL性能方面的潜力。
🔬 方法详解
问题定义:多智能体强化学习(MARL)在复杂环境中难以实现高效学习和期望的行为。现有方法通常依赖于复杂的奖励函数设计或精细的探索策略,但这些方法往往需要大量的 trial-and-error 调整,且泛化能力有限。如何有效地引导智能体学习,使其更快地收敛到期望的行为模式,是本文要解决的核心问题。
核心思路:本文的核心思路是利用大型语言模型(LLM)的强大理解和生成能力,模拟人类专家对智能体进行干预,从而引导智能体的学习过程。通过LLM对环境状态进行理解,并生成相应的干预指令,可以有效地塑造智能体的行为,加速学习过程。这种方法避免了手动设计复杂奖励函数的困难,并具有更好的泛化能力。
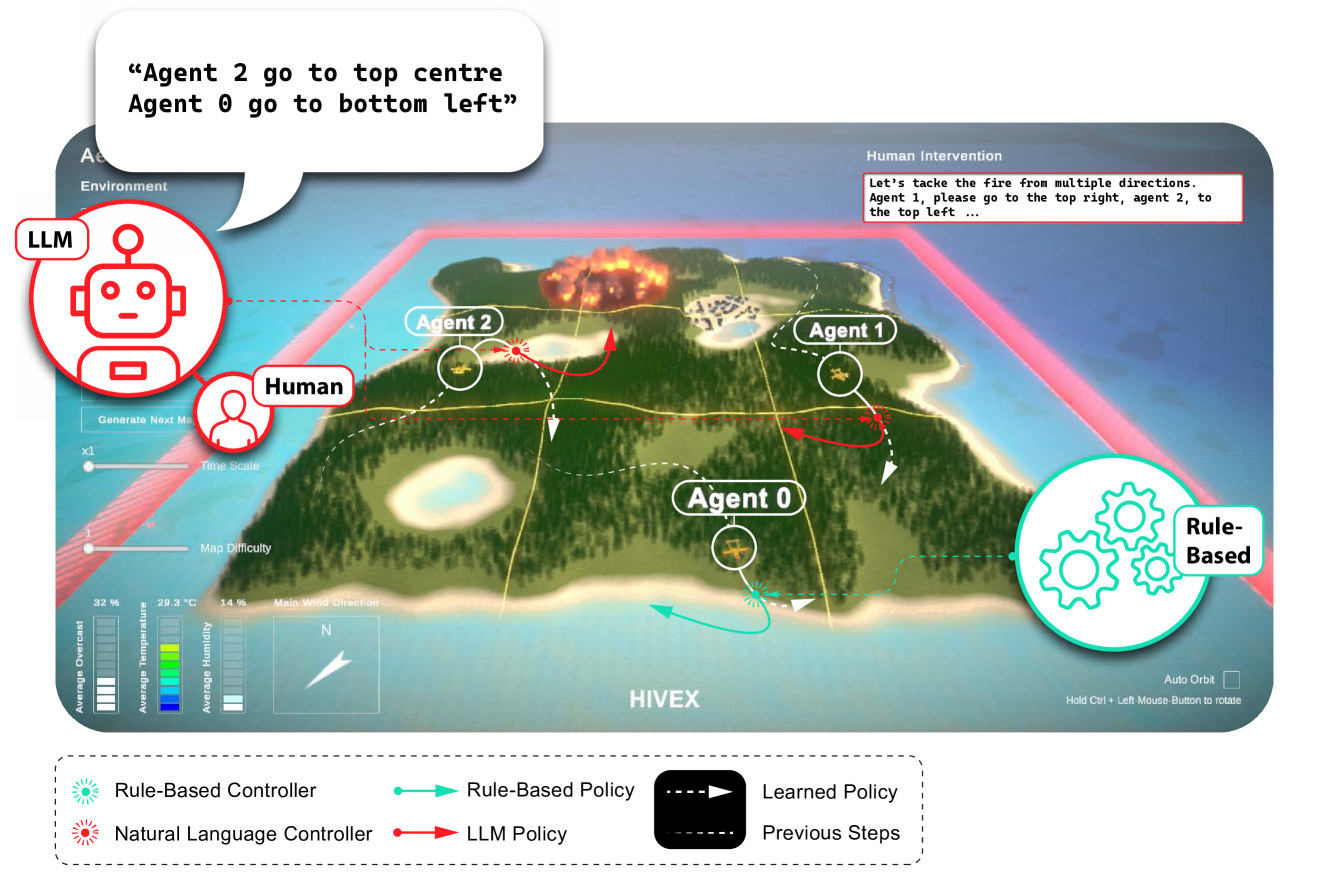
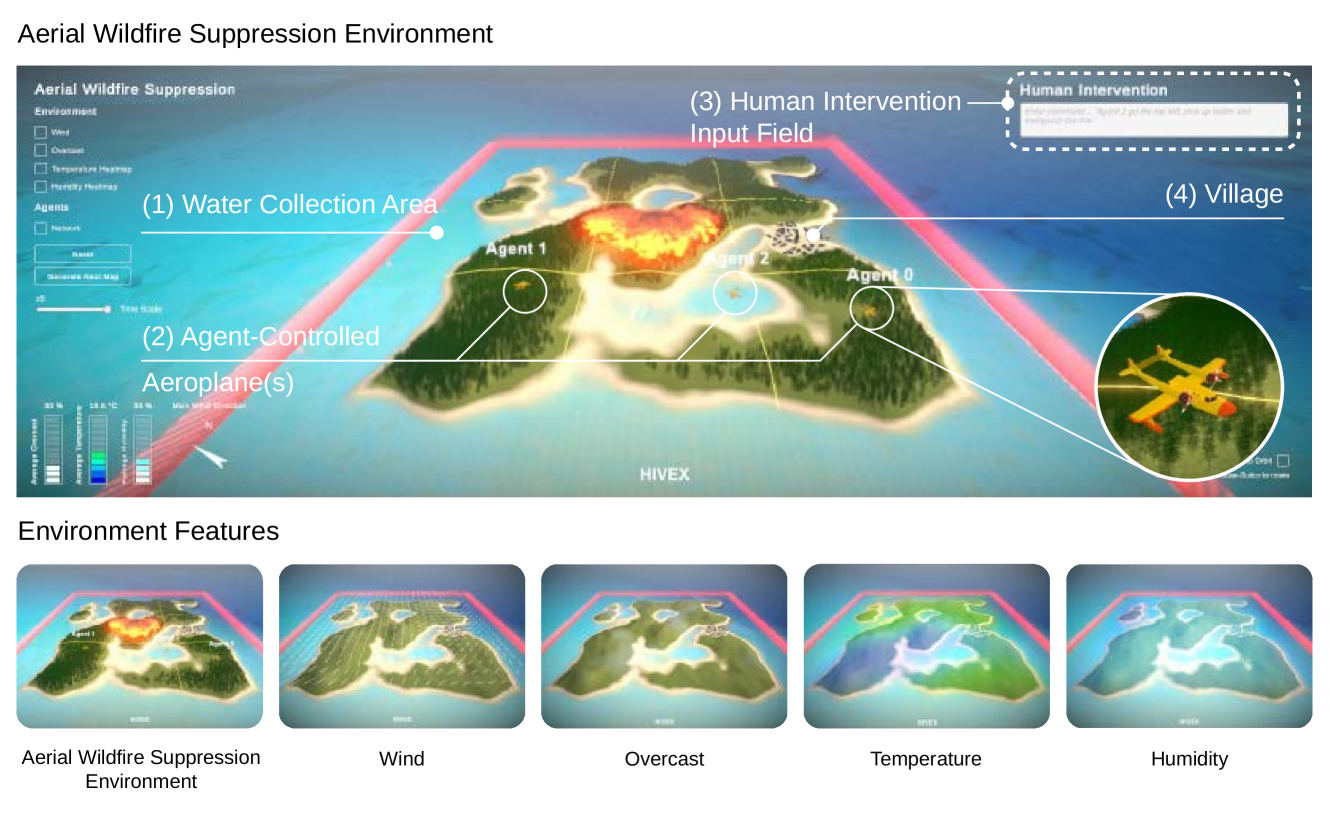
技术框架:整体框架包含MARL环境、LLM控制器和智能体三部分。MARL环境提供智能体交互的平台,智能体通过强化学习算法进行学习。LLM控制器负责观察环境状态,并根据状态生成干预指令。干预指令可以是自然语言形式(NL Controller)或规则形式(RB Controller)。智能体接收到干预指令后,将其融入到自身的决策过程中,从而调整行为。整个过程形成一个闭环反馈系统,LLM控制器根据智能体的行为反馈不断调整干预策略。
关键创新:本文的关键创新在于将大型语言模型引入到MARL系统中,作为智能体的指导者。与传统的基于规则或奖励函数的指导方法相比,LLM具有更强的理解和生成能力,可以根据环境状态生成更灵活和自然的干预指令。此外,本文还提出了两种不同类型的LLM控制器(NL Controller和RB Controller),并比较了它们在MARL系统中的性能。
关键设计:NL Controller使用预训练的LLM(具体模型未知)作为核心,输入是环境状态的描述,输出是自然语言形式的干预指令。RB Controller则基于预定义的规则,根据环境状态生成规则形式的干预指令。两种控制器都旨在引导智能体朝着期望的行为模式发展。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用LLM介导的干预可以显著提升MARL系统的性能。特别是,NL Controller表现出比RB Controller更强的引导能力。此外,早期干预对智能体的学习过程具有更大的影响,可以加速训练并提高最终性能。两种干预方法都优于没有干预的基线,验证了LLM介导的指导在MARL中的有效性。具体的性能提升幅度数据未知。
🎯 应用场景
该研究成果可应用于机器人协作、自动驾驶、智能交通等领域。通过LLM的引导,可以使多智能体系统在复杂环境中更快地学习到高效的协作策略,从而提高系统的整体性能和鲁棒性。未来,该方法有望应用于更广泛的领域,例如智能制造、资源分配和博弈对抗等。
📄 摘要(原文)
In complex multi-agent environments, achieving efficient learning and desirable behaviours is a significant challenge for Multi-Agent Reinforcement Learning (MARL) systems. This work explores the potential of combining MARL with Large Language Model (LLM)-mediated interventions to guide agents toward more desirable behaviours. Specifically, we investigate how LLMs can be used to interpret and facilitate interventions that shape the learning trajectories of multiple agents. We experimented with two types of interventions, referred to as controllers: a Natural Language (NL) Controller and a Rule-Based (RB) Controller. The NL Controller, which uses an LLM to simulate human-like interventions, showed a stronger impact than the RB Controller. Our findings indicate that agents particularly benefit from early interventions, leading to more efficient training and higher performance. Both intervention types outperform the baseline without interventions, highlighting the potential of LLM-mediated guidance to accelerate training and enhance MARL performance in challenging environments.