IPCGRL: Language-Instructed Reinforcement Learning for Procedural Level Generation
作者: In-Chang Baek, Sung-Hyun Kim, Seo-Young Lee, Dong-Hyeon Kim, Kyung-Joong Kim
分类: cs.AI, cs.CL, cs.LG
发布日期: 2025-03-16 (更新: 2025-07-24)
备注: 9 pages, 9 figures, 3 tables, accepted to Conference on Games 2025
💡 一句话要点
IPCGRL:提出一种基于语言指令的强化学习方法,用于程序化关卡生成。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 程序化内容生成 强化学习 自然语言指令 句子嵌入 游戏关卡生成
📋 核心要点
- 现有生成模型的可控性增强研究中,自然语言的重要性日益凸显,但利用文本指令的深度强化学习在程序化内容生成方面的研究仍然有限。
- IPCGRL的核心思想是利用强化学习,并结合微调后的句子嵌入模型,将文本指令有效地融入到程序化关卡生成过程中。
- 实验结果表明,IPCGRL在关卡生成的可控性和泛化性方面均优于通用嵌入方法,分别提升了21.4%和17.2%。
📝 摘要(中文)
本文提出了一种基于指令的程序化内容生成方法IPCGRL,该方法通过强化学习并结合句子嵌入模型实现。IPCGRL微调特定任务的嵌入表示,以有效压缩游戏关卡条件。我们在二维关卡生成任务中评估了IPCGRL,并将其性能与通用嵌入方法进行了比较。结果表明,IPCGRL在可控性方面提高了高达21.4%,在未见指令的泛化性方面提高了17.2%。此外,该方法扩展了条件输入的模态,为程序化内容生成提供了一个更加灵活和富有表现力的交互框架。
🔬 方法详解
问题定义:论文旨在解决程序化内容生成(PCG)中,如何有效利用自然语言指令来控制生成内容的问题。现有方法要么难以将文本指令融入强化学习框架,要么在处理未见过的指令时泛化能力较差。
核心思路:论文的核心思路是利用强化学习训练一个智能体,使其能够根据给定的文本指令生成游戏关卡。为了更好地理解和利用文本指令,论文引入了一个句子嵌入模型,并针对特定任务进行微调,从而获得更有效的指令表示。
技术框架:IPCGRL的整体框架包含以下几个主要模块:1) 指令编码器:使用句子嵌入模型(如BERT)将文本指令编码成向量表示。2) 强化学习智能体:使用深度神经网络作为策略网络,根据当前关卡状态和指令向量,选择下一步的生成动作。3) 环境:模拟游戏关卡生成过程,并根据智能体的动作更新关卡状态。4) 奖励函数:根据生成的关卡是否符合指令要求,给予智能体奖励或惩罚。
关键创新:IPCGRL的关键创新在于针对特定任务微调句子嵌入模型,从而获得更有效的指令表示。这种微调使得模型能够更好地理解游戏关卡相关的指令,并生成更符合要求的关卡。此外,IPCGRL还扩展了条件输入的模态,使得用户可以使用自然语言指令来控制关卡的生成,从而提供了一个更加灵活和富有表现力的交互框架。
关键设计:论文中,句子嵌入模型使用预训练的BERT模型,并在特定任务上进行微调。强化学习智能体使用Actor-Critic算法进行训练,其中Actor网络负责选择动作,Critic网络负责评估当前状态的价值。奖励函数的设计至关重要,需要根据具体的游戏关卡生成任务进行调整,以鼓励智能体生成符合指令要求的关卡。具体的参数设置(如学习率、折扣因子等)需要通过实验进行调整。
🖼️ 关键图片

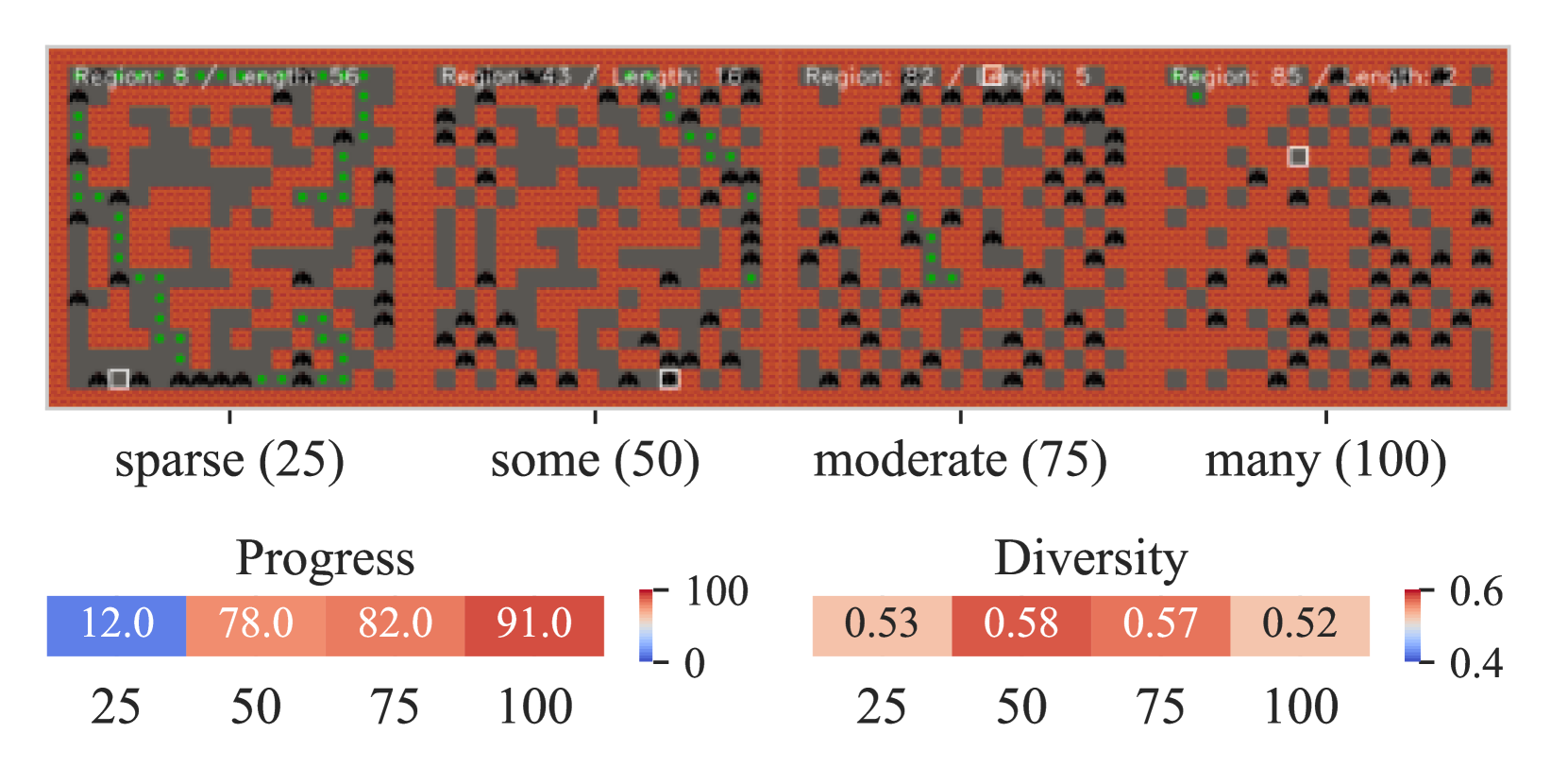
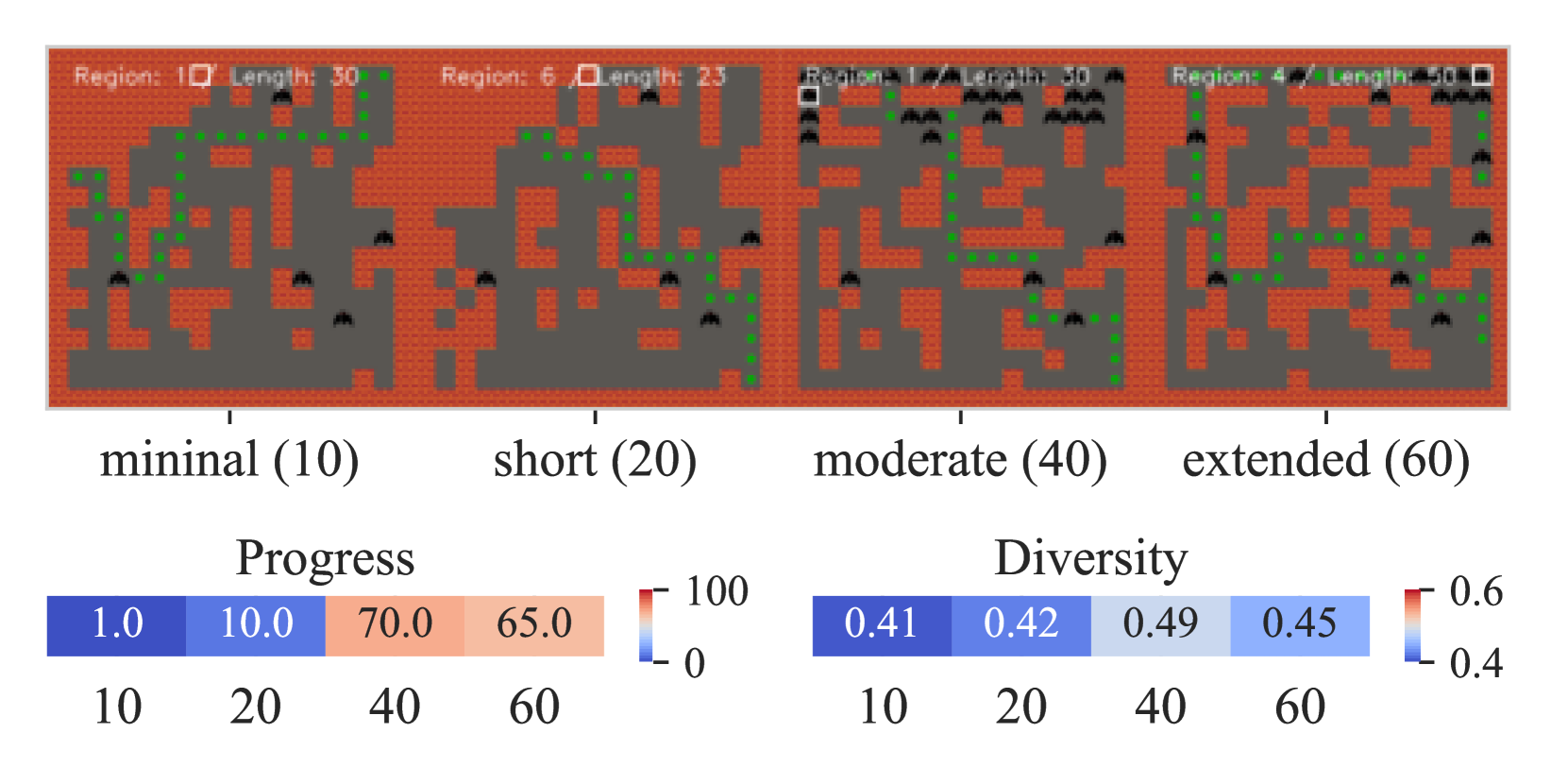
📊 实验亮点
实验结果表明,IPCGRL在二维关卡生成任务中,相较于使用通用嵌入方法的基线模型,在可控性方面提升了21.4%,在未见指令的泛化性方面提升了17.2%。这些结果验证了IPCGRL在利用自然语言指令进行程序化内容生成方面的有效性。
🎯 应用场景
IPCGRL可应用于游戏开发、教育、以及内容创作等领域。在游戏开发中,它可以帮助开发者快速生成各种类型的游戏关卡,提高开发效率。在教育领域,它可以用于生成定制化的学习内容,满足不同学生的学习需求。在内容创作领域,它可以用于生成各种类型的艺术作品,如音乐、绘画等。
📄 摘要(原文)
Recent research has highlighted the significance of natural language in enhancing the controllability of generative models. While various efforts have been made to leverage natural language for content generation, research on deep reinforcement learning (DRL) agents utilizing text-based instructions for procedural content generation remains limited. In this paper, we propose IPCGRL, an instruction-based procedural content generation method via reinforcement learning, which incorporates a sentence embedding model. IPCGRL fine-tunes task-specific embedding representations to effectively compress game-level conditions. We evaluate IPCGRL in a two-dimensional level generation task and compare its performance with a general-purpose embedding method. The results indicate that IPCGRL achieves up to a 21.4% improvement in controllability and a 17.2% improvement in generalizability for unseen instructions. Furthermore, the proposed method extends the modality of conditional input, enabling a more flexible and expressive interaction framework for procedural content generation.