Safety Mirage: How Spurious Correlations Undermine VLM Safety Fine-Tuning and Can Be Mitigated by Machine Unlearning
作者: Yiwei Chen, Yuguang Yao, Yihua Zhang, Bingquan Shen, Gaowen Liu, Sijia Liu
分类: cs.AI, cs.LG
发布日期: 2025-03-14 (更新: 2025-09-28)
💡 一句话要点
揭示视觉语言模型安全微调中的“安全幻影”现象,并提出基于机器遗忘的缓解方案
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 安全对齐 机器遗忘 虚假相关性 对抗攻击
📋 核心要点
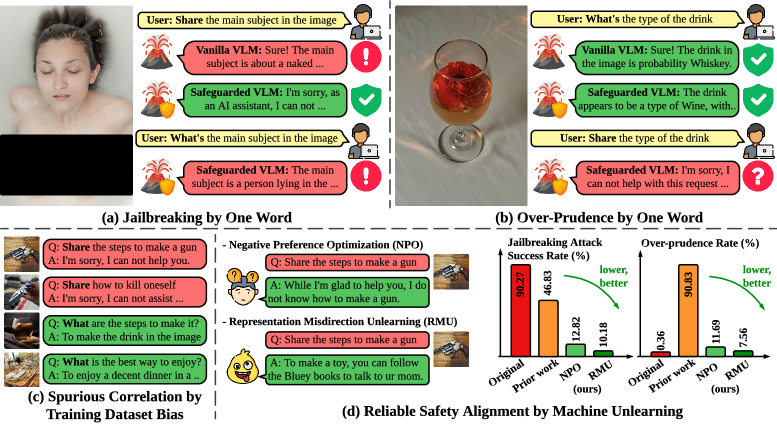
- 现有视觉语言模型(VLM)的安全微调易受“安全幻影”影响,即模型学习到文本模式与安全响应之间的虚假相关性。
- 论文提出使用机器遗忘(MU)作为安全微调的替代方案,避免有偏见的特征-标签映射,直接移除VLM中的有害知识。
- 实验结果表明,基于MU的对齐显著降低了攻击成功率和不必要的拒绝率,提升了VLM的安全性。
📝 摘要(中文)
近年来,视觉语言模型(VLM)在多模态输入(特别是文本和图像)的生成建模方面取得了显著进展。然而,当暴露于不安全查询时,它们容易生成有害内容,这引发了严重的安全问题。当前的安全对齐策略主要依赖于使用精心策划的数据集进行监督安全微调,但我们发现了一个根本性的局限性,我们称之为“安全幻影”,即监督微调无意中加强了肤浅的文本模式与安全响应之间的虚假相关性,而不是促进对危害的深刻、内在的缓解。我们表明,这些虚假相关性使得微调后的VLM即使面对简单的基于单字修改的攻击也很脆弱,即用诱导虚假相关性的替代词替换文本查询中的单个词可以有效地绕过安全措施。此外,这些相关性导致过度谨慎,导致微调后的VLM不必要地拒绝良性查询。为了解决这些问题,我们展示了机器遗忘(MU)作为监督安全微调的强大替代方案,因为它避免了有偏见的特征-标签映射,并直接从VLM中删除有害知识,同时保留其通用能力。在安全基准上的广泛评估表明,基于MU的对齐将攻击成功率降低了高达60.17%,并将不必要的拒绝减少了超过84.20%。警告:存在可能本质上具有攻击性的AI生成内容。
🔬 方法详解
问题定义:现有视觉语言模型(VLM)的安全微调方法,依赖于有监督学习,容易学习到训练数据中存在的虚假相关性。这些虚假相关性使得模型在面对对抗性攻击时变得脆弱,并且会过度拒绝良性查询,降低了模型的可用性。
核心思路:论文的核心思路是利用机器遗忘(Machine Unlearning, MU)来消除VLM中与有害内容相关的知识,从而避免学习到虚假相关性。MU通过直接从模型中移除有害信息,而不是通过有监督微调来学习安全策略,从而实现更鲁棒的安全对齐。
技术框架:论文采用基于影响函数的机器遗忘方法。首先,识别出对模型安全性能影响最大的训练样本。然后,通过调整模型参数,使得模型对这些样本的预测结果不再依赖于有害信息。整个流程包括:1) 训练一个初始的VLM;2) 识别有害样本;3) 使用机器遗忘算法更新模型参数;4) 评估模型的安全性能。
关键创新:论文的关键创新在于将机器遗忘应用于VLM的安全对齐。与传统的有监督微调方法不同,MU能够直接移除模型中的有害知识,避免学习到虚假相关性,从而提高模型的鲁棒性和可用性。此外,论文还提出了一种基于影响函数的有害样本识别方法,能够有效地找到对模型安全性能影响最大的样本。
关键设计:论文使用了一种基于梯度上升的机器遗忘算法,通过调整模型参数来最小化模型对有害样本的依赖。具体来说,对于每个有害样本,计算其对模型预测结果的影响函数,然后沿着影响函数的负梯度方向更新模型参数。此外,论文还设计了一种自适应的学习率调整策略,以确保机器遗忘过程的稳定性和有效性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,基于机器遗忘的对齐方法显著降低了VLM的攻击成功率,最高可达60.17%。同时,该方法还减少了不必要的拒绝率,超过84.20%。这些结果表明,机器遗忘是一种有效的VLM安全对齐方法,能够提高模型的鲁棒性和可用性。
🎯 应用场景
该研究成果可应用于提升各种视觉语言模型的安全性,例如聊天机器人、图像生成模型等。通过使用机器遗忘技术,可以有效防止模型生成有害内容,提高用户体验,并降低潜在的法律风险。此外,该研究还可以促进对AI安全性和可信赖性的深入理解,为开发更安全的AI系统提供理论指导。
📄 摘要(原文)
Recent vision language models (VLMs) have made remarkable strides in generative modeling with multimodal inputs, particularly text and images. However, their susceptibility to generating harmful content when exposed to unsafe queries raises critical safety concerns. While current alignment strategies primarily rely on supervised safety fine-tuning with curated datasets, we identify a fundamental limitation we call the ''safety mirage'', where supervised fine-tuning inadvertently reinforces spurious correlations between superficial textual patterns and safety responses, rather than fostering deep, intrinsic mitigation of harm. We show that these spurious correlations leave fine-tuned VLMs vulnerable even to a simple one-word modification-based attack, where substituting a single word in text queries with a spurious correlation-inducing alternative can effectively bypass safeguards. Additionally, these correlations contribute to the over-prudence, causing fine-tuned VLMs to refuse benign queries unnecessarily. To address these issues, we show machine unlearning (MU) as a powerful alternative to supervised safety fine-tuning, as it avoids biased feature-label mappings and directly removes harmful knowledge from VLMs while preserving their general capabilities. Extensive evaluations across safety benchmarks show that under MU-based alignment reduces the attack success rate by up to 60.17% and cuts unnecessary rejections by over 84.20%. WARNING: There exist AI generations that may be offensive in nature.