Chat-TS: Enhancing Multi-Modal Reasoning Over Time-Series and Natural Language Data
作者: Paul Quinlan, Qingguo Li, Xiaodan Zhu
分类: cs.AI, cs.CL
发布日期: 2025-03-13
💡 一句话要点
Chat-TS:增强LLM在时序数据和自然语言上的多模态推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态推理 时间序列分析 大型语言模型 指令调优 自然语言处理
📋 核心要点
- 现有时序模型在结合时序数据和文本内容进行推理方面存在局限性,无法支持基于上下文信息的决策。
- Chat-TS将时序数据token集成到LLM词汇表中,提升模型在时序数据和文本上的多模态推理能力,同时保持自然语言处理能力。
- 论文构建了多个数据集用于训练和评估,实验结果表明Chat-TS在多模态推理任务上达到了state-of-the-art的性能。
📝 摘要(中文)
本文提出了一种基于大型语言模型(LLM)的框架Chat-TS,旨在支持时序数据和文本数据的推理。与传统模型不同,Chat-TS将时序数据token集成到LLM的词汇表中,增强了其在两种模态上的推理能力,同时不影响其核心自然语言能力,从而实现跨模态的实际分析和推理。为了支持学习和评估,本文贡献了新的数据集:TS Instruct Training Dataset,它将不同的时序数据与相关的文本指令和响应配对,用于指令调优;TS Instruct Question and Answer (QA) Gold Dataset,它提供了多项选择题,旨在评估多模态推理;以及TS Instruct Quantitative Probing Set,它包含TS Instruct QA任务的一个小子集,以及用于LLM评估的数学和决策问题。设计了一种训练策略,以保持LLM固有的推理能力,同时增强其时序推理能力。实验表明,Chat-TS通过保持强大的自然语言能力并提高时序推理能力,在多模态推理任务中实现了最先进的性能。
🔬 方法详解
问题定义:现有时间序列模型难以有效融合时间序列数据和自然语言文本进行联合推理。实际应用中,决策往往依赖于对时间序列数据及其相关文本描述的综合分析,而现有模型无法充分利用文本信息增强时间序列分析,或利用时间序列数据辅助文本理解。因此,如何提升模型在时间序列和文本数据上的多模态推理能力是一个关键问题。
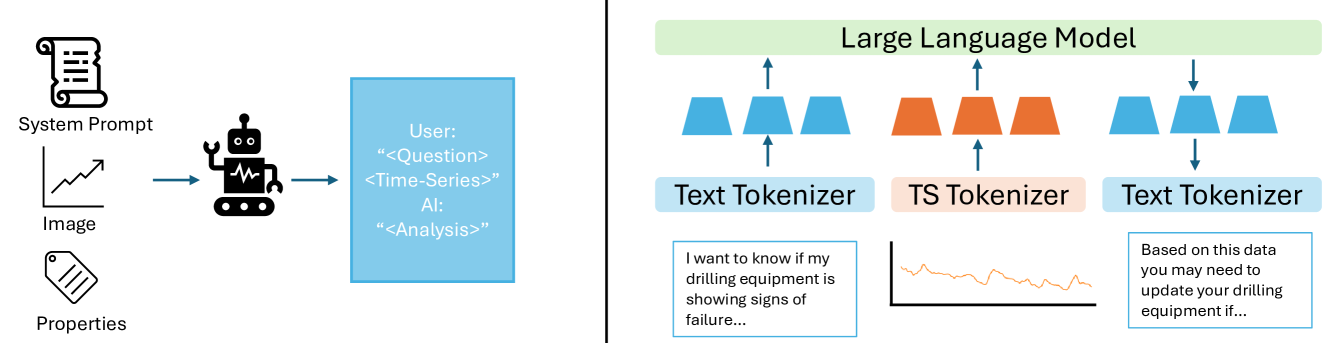
核心思路:Chat-TS的核心思路是将时间序列数据视为一种新的token类型,并将其融入到大型语言模型(LLM)的词汇表中。通过这种方式,LLM可以直接处理和理解时间序列数据,并将其与文本信息进行融合,从而实现更强大的多模态推理能力。这种方法避免了对LLM结构进行大幅修改,保留了其原有的自然语言处理能力。
技术框架:Chat-TS框架主要包含以下几个阶段:1) 数据预处理:对时间序列数据进行token化处理,将其转换为LLM可以理解的格式。2) 词汇表扩展:将时间序列token添加到LLM的词汇表中。3) 模型训练:使用包含时间序列数据和文本信息的混合数据集对LLM进行训练,使其学习如何进行多模态推理。4) 模型评估:使用专门设计的评估数据集对模型的性能进行评估。
关键创新:Chat-TS的关键创新在于将时间序列数据token直接集成到LLM的词汇表中。与以往将时间序列数据作为外部输入或特征进行处理的方法不同,Chat-TS允许LLM直接对时间序列数据进行建模和推理,从而更有效地利用时间序列信息。这种方法的本质区别在于,它将时间序列数据视为LLM的固有组成部分,而不是外部附加信息。
关键设计:在模型训练方面,论文设计了一种特殊的训练策略,旨在保持LLM原有的自然语言处理能力,同时增强其时间序列推理能力。具体来说,论文采用了指令调优(Instruction Tuning)的方法,使用包含时间序列数据和文本指令的混合数据集对LLM进行微调。此外,论文还设计了多个损失函数,用于平衡模型在自然语言处理和时间序列推理方面的性能。
🖼️ 关键图片
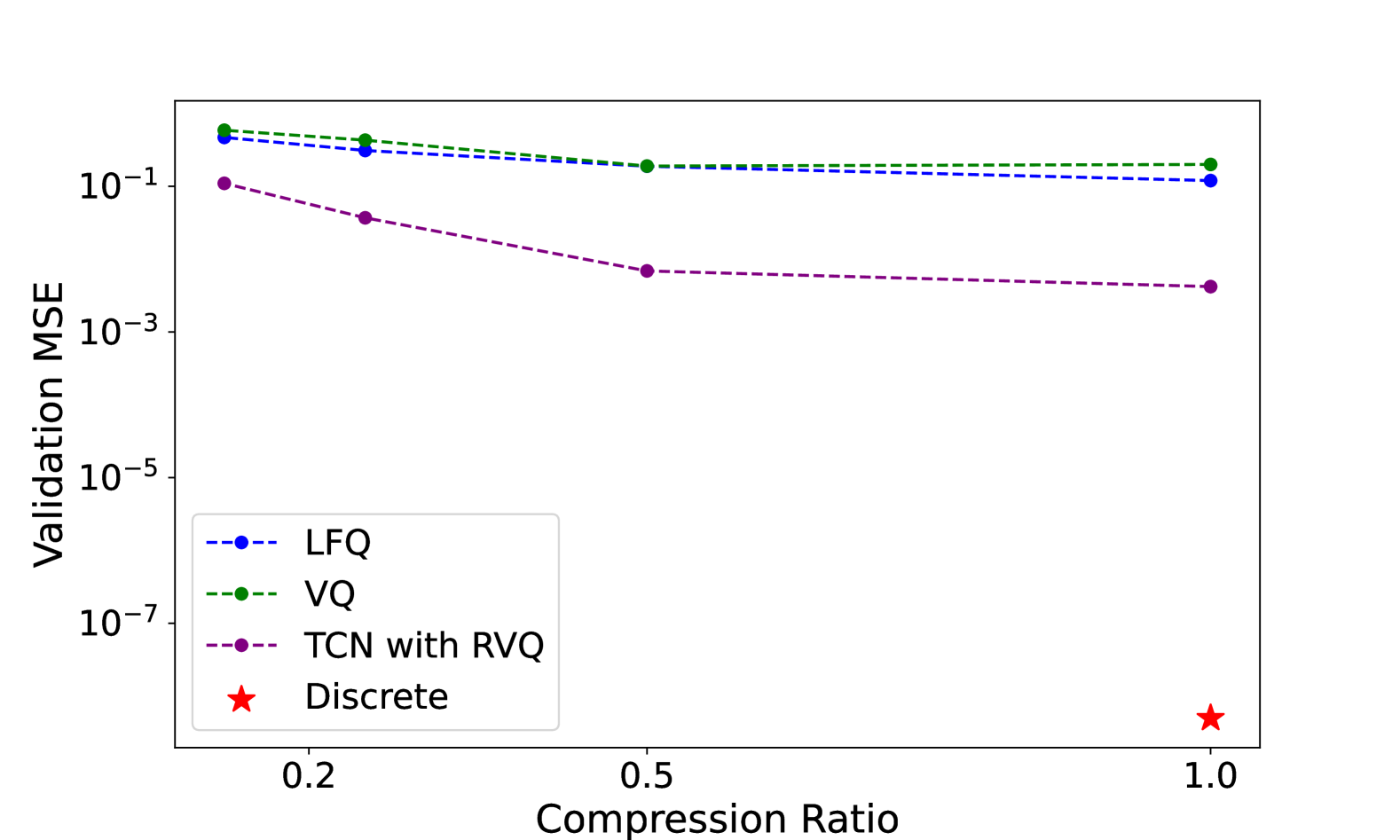
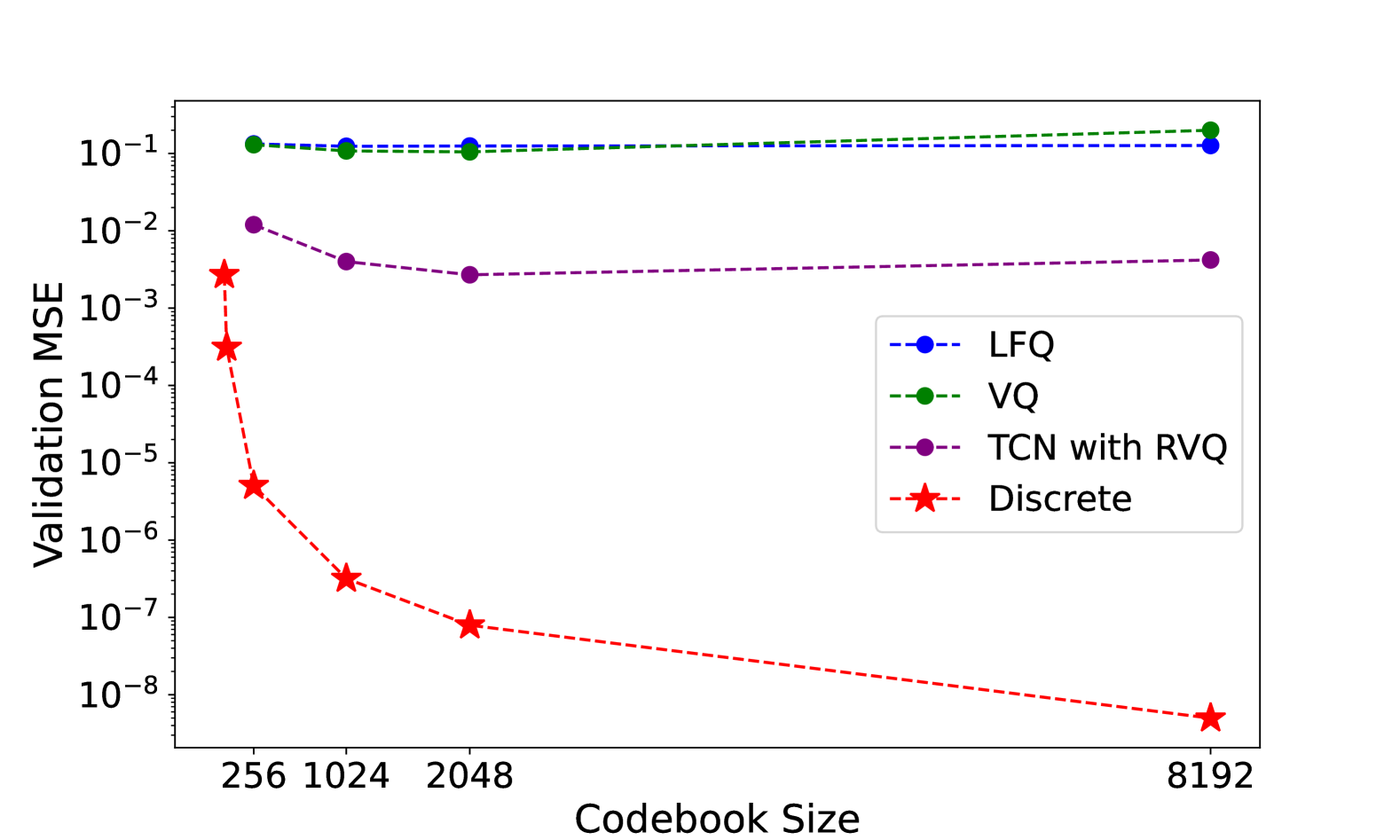
📊 实验亮点
实验结果表明,Chat-TS在多模态推理任务中取得了state-of-the-art的性能。通过与现有基线模型进行对比,Chat-TS在多个评估指标上均取得了显著提升,证明了其在时间序列和文本数据上的多模态推理能力。具体性能数据未知,但强调了模型在保持自然语言能力的同时,提升了时序推理能力。
🎯 应用场景
Chat-TS在医疗健康、金融、交通运输和能源等领域具有广泛的应用前景。例如,在医疗领域,可以结合患者的生理指标时间序列数据和病历文本信息,辅助医生进行诊断和治疗方案制定。在金融领域,可以结合股票价格时间序列数据和新闻报道,预测市场趋势。该研究有助于提升决策的智能化水平,并为相关领域带来实际价值。
📄 摘要(原文)
Time-series analysis is critical for a wide range of fields such as healthcare, finance, transportation, and energy, among many others. The practical applications often involve analyzing time-series data alongside contextual information in the form of natural language to support informed decisions. However, current time-series models are limited in their ability to perform reasoning that involves both time-series and their textual content. In this work, we address this gap by introducing \textit{Chat-TS}, a large language model (LLM) based framework, designed to support reasoning over time series and textual data. Unlike traditional models, Chat-TS integrates time-series tokens into LLMs' vocabulary, enhancing its reasoning ability over both modalities without compromising the core natural language capabilities, enabling practical analysis and reasoning across modalities. To support learning and evaluation in this setup, we contribute new datasets: the \textit{TS Instruct Training Dataset} which pairs diverse time-series data with relevant text instructions and responses for instruction tuning, the \textit{TS Instruct Question and Answer (QA) Gold Dataset} which provides multiple-choice questions designed to evaluate multimodal reasoning, and a \textit{TS Instruct Quantitative Probing Set} which contains a small subset of the TS Instruct QA tasks alongside math and decision-making questions for LLM evaluation. We designed a training strategy to preserve the inherent reasoning capabilities of LLMs while augmenting them for time-series reasoning. Experiments show that Chat-TS achieves state-of-the-art performance in multi-modal reasoning tasks by maintaining strong natural language proficiency while improving time-series reasoning. ~\footnote{To ensure replicability and facilitate future research, all models, datasets, and code will be available at [\texttt{Github-URL}].}