OR-LLM-Agent: Automating Modeling and Solving of Operations Research Optimization Problems with Reasoning LLM
作者: Bowen Zhang, Pengcheng Luo, Genke Yang, Boon-Hee Soong, Chau Yuen
分类: cs.AI, math.OC
发布日期: 2025-03-13 (更新: 2025-08-01)
备注: 8 pages, 13 figures
💡 一句话要点
提出OR-LLM-Agent,利用推理LLM自动建模和解决运筹学优化问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 运筹学 大型语言模型 AI代理 任务分解 数学建模 代码生成 优化问题 推理LLM
📋 核心要点
- 现有方法依赖提示工程或微调LLM解决运筹学问题,但受限于非推理LLM的能力。
- OR-LLM-Agent基于推理LLM,将问题分解为建模、代码生成和调试三个阶段。
- 实验表明,OR-LLM-Agent优于GPT-o3等先进方法至少7%,验证了任务分解的有效性。
📝 摘要(中文)
随着人工智能的兴起,将大型语言模型(LLM)应用于数学问题求解受到了越来越多的关注。现有方法大多试图通过提示工程或微调策略来改进LLM在运筹学(OR)优化问题求解方面的性能。然而,这些方法本质上受到非推理LLM有限能力的限制。为了克服这些限制,我们提出了OR-LLM-Agent,这是一个基于推理LLM的AI代理框架,用于自动解决OR问题。该框架将任务分解为三个连续的阶段:数学建模、代码生成和调试。每个任务由一个专门的子代理处理,从而实现更有针对性的推理。我们还构建了BWOR,一个用于评估LLM在OR任务上性能的OR数据集。我们的分析表明,在NL4OPT、MAMO和IndustryOR基准测试中,推理LLM有时表现不如同一模型系列的非推理LLM。相比之下,BWOR提供了对模型能力更一致和更具区分性的评估。实验结果表明,OR-LLM-Agent在其框架中使用DeepSeek-R1,其准确率至少比GPT-o3、Gemini 2.5 Pro、DeepSeek-R1和ORLM等先进方法高7%。这些结果证明了任务分解对于解决OR问题的有效性。
🔬 方法详解
问题定义:论文旨在解决运筹学(OR)优化问题的自动化建模和求解问题。现有方法主要依赖于提示工程或微调大型语言模型(LLM),但这些方法受限于非推理LLM的能力,无法有效地进行复杂的推理和问题分解,导致求解精度和泛化能力不足。
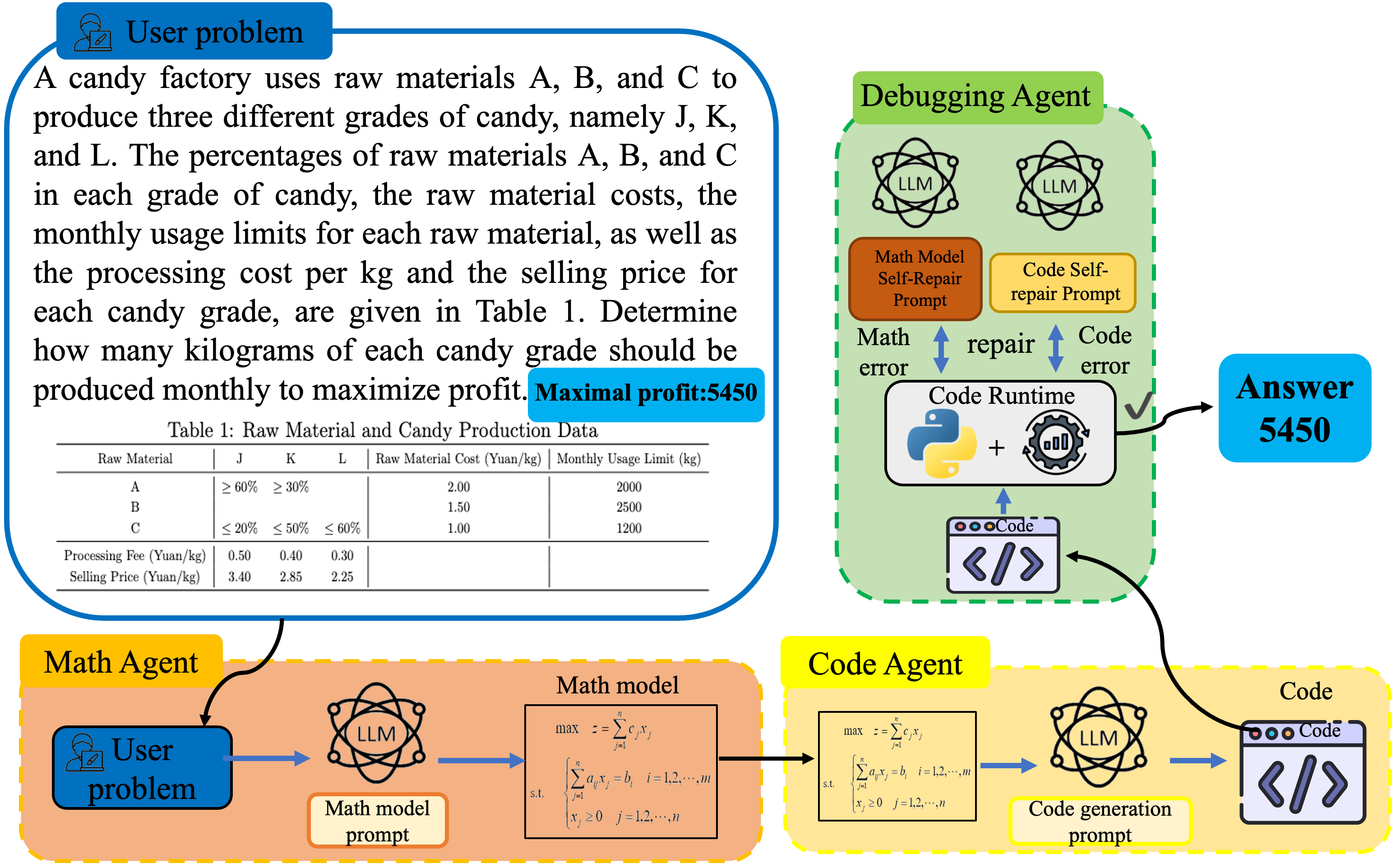
核心思路:论文的核心思路是将OR问题求解过程分解为多个可管理的子任务,并为每个子任务设计专门的子代理。通过任务分解,可以更有效地利用推理LLM的能力,针对性地解决每个阶段的问题,从而提高整体求解性能。
技术框架:OR-LLM-Agent框架包含三个主要阶段:数学建模、代码生成和调试。每个阶段由一个专门的子代理负责。数学建模子代理负责将自然语言描述的OR问题转化为数学模型;代码生成子代理负责根据数学模型生成可执行的代码;调试子代理负责检测和修复代码中的错误。这三个子代理协同工作,完成整个OR问题的求解过程。
关键创新:该论文的关键创新在于提出了一个基于推理LLM的AI代理框架,用于自动解决OR问题。通过将任务分解为多个阶段,并为每个阶段设计专门的子代理,可以更有效地利用推理LLM的能力,提高求解精度和泛化能力。此外,论文还构建了一个新的OR数据集BWOR,用于评估LLM在OR任务上的性能。
关键设计:论文中没有明确提及关键的参数设置、损失函数或网络结构等技术细节。框架的核心在于任务分解和子代理的设计,以及如何有效地利用推理LLM的能力来解决每个阶段的问题。具体实现细节可能依赖于所使用的LLM和具体的OR问题。
🖼️ 关键图片

📊 实验亮点
实验结果表明,OR-LLM-Agent框架使用DeepSeek-R1时,在准确率上优于GPT-o3、Gemini 2.5 Pro、DeepSeek-R1和ORLM等先进方法至少7%。此外,论文提出的BWOR数据集能够更一致和更具区分性地评估模型在OR任务上的性能,弥补了现有数据集的不足。
🎯 应用场景
该研究成果可应用于各种需要运筹学优化的领域,如供应链管理、资源分配、生产调度、物流优化等。通过自动化建模和求解过程,可以降低对专业人员的依赖,提高问题解决效率,并为决策者提供更优的解决方案。未来,该技术有望进一步扩展到更复杂的优化问题,并与其他AI技术相结合,实现更智能化的决策支持。
📄 摘要(原文)
With the rise of artificial intelligence (AI), applying large language models (LLMs) to mathematical problem-solving has attracted increasing attention. Most existing approaches attempt to improve Operations Research (OR) optimization problem-solving through prompt engineering or fine-tuning strategies for LLMs. However, these methods are fundamentally constrained by the limited capabilities of non-reasoning LLMs. To overcome these limitations, we propose OR-LLM-Agent, an AI agent framework built on reasoning LLMs for automated OR problem solving. The framework decomposes the task into three sequential stages: mathematical modeling, code generation, and debugging. Each task is handled by a dedicated sub-agent, which enables more targeted reasoning. We also construct BWOR, an OR dataset for evaluating LLM performance on OR tasks. Our analysis shows that in the benchmarks NL4OPT, MAMO, and IndustryOR, reasoning LLMs sometimes underperform their non-reasoning counterparts within the same model family. In contrast, BWOR provides a more consistent and discriminative assessment of model capabilities. Experimental results demonstrate that OR-LLM-Agent utilizing DeepSeek-R1 in its framework outperforms advanced methods, including GPT-o3, Gemini 2.5 Pro, DeepSeek-R1, and ORLM, by at least 7\% in accuracy. These results demonstrate the effectiveness of task decomposition for OR problem solving.