CASTLE: Benchmarking Dataset for Static Code Analyzers and LLMs towards CWE Detection
作者: Richard A. Dubniczky, Krisztofer Zoltán Horvát, Tamás Bisztray, Mohamed Amine Ferrag, Lucas C. Cordeiro, Norbert Tihanyi
分类: cs.CR, cs.AI, cs.SE
发布日期: 2025-03-12 (更新: 2025-03-31)
💡 一句话要点
CASTLE:用于CWE检测的静态代码分析器和LLM基准测试数据集
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 漏洞检测 静态代码分析 大型语言模型 基准测试 软件安全
📋 核心要点
- 现有静态分析、动态分析、形式化验证等方法在检测软件漏洞方面存在局限性,如高误报率和对特定类型漏洞的无力。
- 论文提出CASTLE基准测试框架,包含手工构建的微基准程序数据集和CASTLE Score评估指标,用于全面评估各种漏洞检测方法的性能。
- 实验结果表明,LLM在小代码片段中表现出色,但随着代码规模增加,准确率下降,幻觉增加,提示LLM在代码补全等场景的潜力。
📝 摘要(中文)
本文介绍了CASTLE(CWE自动化安全测试和低级评估),一个用于评估不同方法漏洞检测能力的基准测试框架。该框架评估了13个静态分析工具、10个LLM和2个形式化验证工具,使用一个包含25个常见CWE的250个微基准程序的手工数据集。论文提出了CASTLE Score,一种新颖的评估指标,以确保公平比较。结果表明,ESBMC(一种形式化验证工具)最大限度地减少了误报,但难以处理模型检查之外的漏洞,例如弱密码学或SQL注入。静态分析器存在高误报问题,增加了开发人员的手动验证工作。LLM在识别小型代码片段中的漏洞时表现出色。然而,随着代码规模的增长,它们的准确性下降,幻觉增加。这些结果表明,LLM可以在未来的安全解决方案中发挥关键作用,尤其是在代码完成框架中,它们可以提供实时指导以防止漏洞。该数据集可在https://github.com/CASTLE-Benchmark上访问。
🔬 方法详解
问题定义:论文旨在解决现有漏洞检测方法,特别是静态分析工具和LLM,在检测常见软件漏洞(CWE)时缺乏统一、公平的评估标准和数据集的问题。现有方法,如静态分析工具,通常存在高误报率,导致开发人员需要进行大量手动验证。而LLM在漏洞检测方面的能力尚未得到充分评估,尤其是在不同代码规模下的表现。
核心思路:论文的核心思路是构建一个高质量、多样化的漏洞基准测试数据集,并设计一个综合评估指标,以便对各种漏洞检测方法进行公平、客观的比较。通过分析不同方法在同一数据集上的表现,可以揭示它们的优势和局限性,从而指导未来的研究方向。
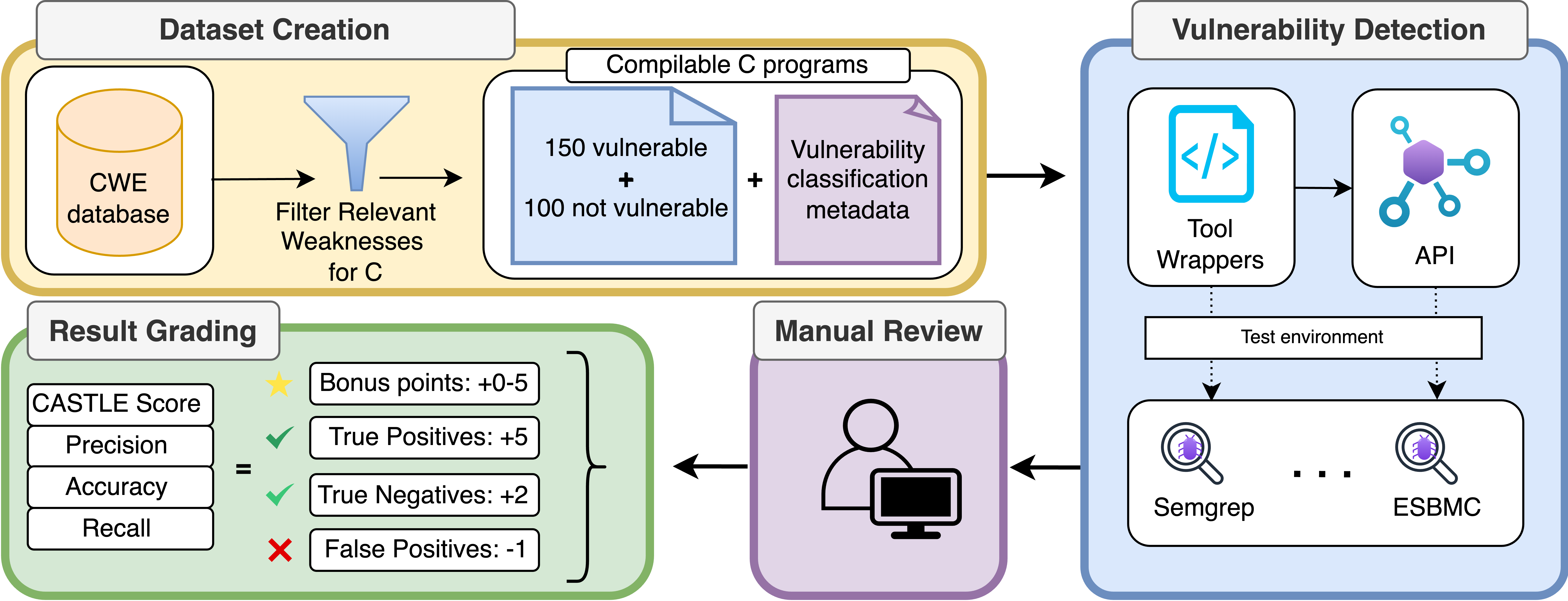
技术框架:CASTLE框架包含以下主要组成部分:1) 一个包含250个微基准程序的手工数据集,覆盖25个常见的CWE;2) 一套评估流程,用于运行不同的漏洞检测工具(包括静态分析器、LLM和形式化验证工具)并记录其输出;3) CASTLE Score评估指标,用于综合评估工具的性能,包括真阳性率、假阳性率等。整个流程旨在自动化漏洞检测的评估过程,并提供可重复的结果。
关键创新:论文的关键创新在于:1) 构建了一个专门用于CWE检测的微基准测试数据集,该数据集具有良好的代表性和可控性;2) 提出了CASTLE Score评估指标,该指标综合考虑了真阳性、假阳性等因素,能够更全面地评估漏洞检测工具的性能;3) 对比评估了多种静态分析工具、LLM和形式化验证工具,揭示了它们在漏洞检测方面的优缺点。
关键设计:CASTLE Score的计算方式未知,论文中可能包含其具体公式。数据集的设计考虑了不同CWE的覆盖范围和代码复杂性,以确保评估的全面性和有效性。对于LLM的评估,可能采用了不同的prompt工程技术,以提高其漏洞检测的准确性。这些具体设计细节需要参考论文原文。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ESBMC在减少误报方面表现出色,但难以检测模型检查之外的漏洞。静态分析器普遍存在高误报问题。LLM在小代码片段中表现良好,但随着代码规模增加,准确率下降。这些结果突出了不同方法在漏洞检测方面的优势和局限性,为未来的研究方向提供了指导。
🎯 应用场景
该研究成果可应用于软件安全领域,帮助开发人员选择合适的漏洞检测工具,提高软件安全性。CASTLE数据集可作为训练和评估新型漏洞检测算法的基准,促进相关研究的发展。此外,该研究结果有助于将LLM集成到代码完成框架中,为开发人员提供实时的安全指导。
📄 摘要(原文)
Identifying vulnerabilities in source code is crucial, especially in critical software components. Existing methods such as static analysis, dynamic analysis, formal verification, and recently Large Language Models are widely used to detect security flaws. This paper introduces CASTLE (CWE Automated Security Testing and Low-Level Evaluation), a benchmarking framework for evaluating the vulnerability detection capabilities of different methods. We assess 13 static analysis tools, 10 LLMs, and 2 formal verification tools using a hand-crafted dataset of 250 micro-benchmark programs covering 25 common CWEs. We propose the CASTLE Score, a novel evaluation metric to ensure fair comparison. Our results reveal key differences: ESBMC (a formal verification tool) minimizes false positives but struggles with vulnerabilities beyond model checking, such as weak cryptography or SQL injection. Static analyzers suffer from high false positives, increasing manual validation efforts for developers. LLMs perform exceptionally well in the CASTLE dataset when identifying vulnerabilities in small code snippets. However, their accuracy declines, and hallucinations increase as the code size grows. These results suggest that LLMs could play a pivotal role in future security solutions, particularly within code completion frameworks, where they can provide real-time guidance to prevent vulnerabilities. The dataset is accessible at https://github.com/CASTLE-Benchmark.