CyberLLMInstruct: A Pseudo-malicious Dataset Revealing Safety-performance Trade-offs in Cyber Security LLM Fine-tuning
作者: Adel ElZemity, Budi Arief, Shujun Li
分类: cs.CR, cs.AI
发布日期: 2025-03-12 (更新: 2025-09-17)
💡 一句话要点
CyberLLMInstruct:揭示网络安全LLM微调中安全与性能的权衡
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 网络安全 微调 安全性评估 对抗性攻击
📋 核心要点
- 现有方法难以兼顾网络安全LLM微调的性能提升与安全性保障,存在安全漏洞。
- 提出CyberLLMInstruct数据集,用于评估和改进LLM在网络安全领域的安全性能。
- 实验表明,微调虽提升性能,但显著降低了LLM的安全性,需平衡性能与安全。
📝 摘要(中文)
本文介绍了CyberLLMInstruct,一个包含54928个伪恶意指令-响应对的数据集,涵盖了网络安全任务,包括恶意软件分析、网络钓鱼模拟和零日漏洞。通过对七个开源LLM的全面评估,揭示了一个关键的权衡:微调虽然提高了网络安全任务的性能(在CyberMetric上达到高达92.50%的准确率),但严重损害了所有测试模型和攻击向量的安全性(例如,Llama 3.1 8B针对提示注入的安全性得分从0.95降至0.15)。该数据集整合了来自CTF挑战、学术论文、行业报告和CVE数据库等多种来源,以确保对网络安全领域的全面覆盖。研究结果强调了在对抗性领域保护LLM的独特挑战,并确立了开发微调方法以平衡安全敏感领域中的性能提升与安全保持的关键需求。
🔬 方法详解
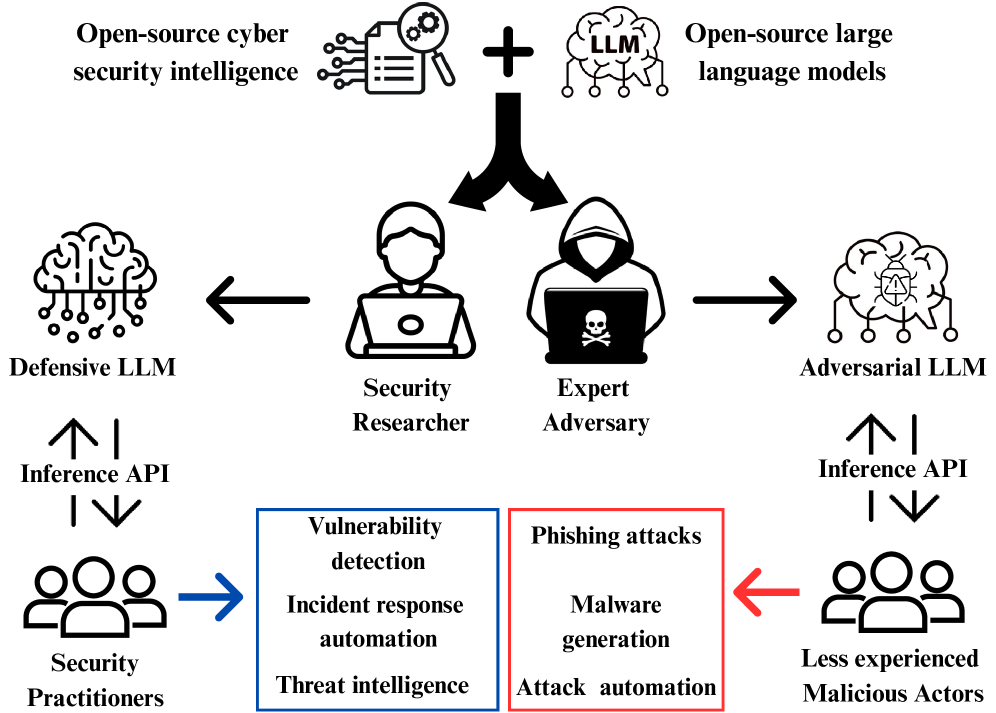
问题定义:论文旨在解决在网络安全领域应用大型语言模型(LLM)时,微调过程可能导致模型安全性能下降的问题。现有方法在追求性能提升时,往往忽略了模型在对抗性环境下的安全性,容易受到恶意攻击,例如提示注入等。
核心思路:核心思路是通过构建一个包含大量伪恶意指令-响应对的数据集(CyberLLMInstruct),来评估和分析LLM在微调后安全性能的变化。通过对比微调前后模型的安全指标,揭示性能与安全之间的权衡关系,从而指导更安全的微调策略的设计。
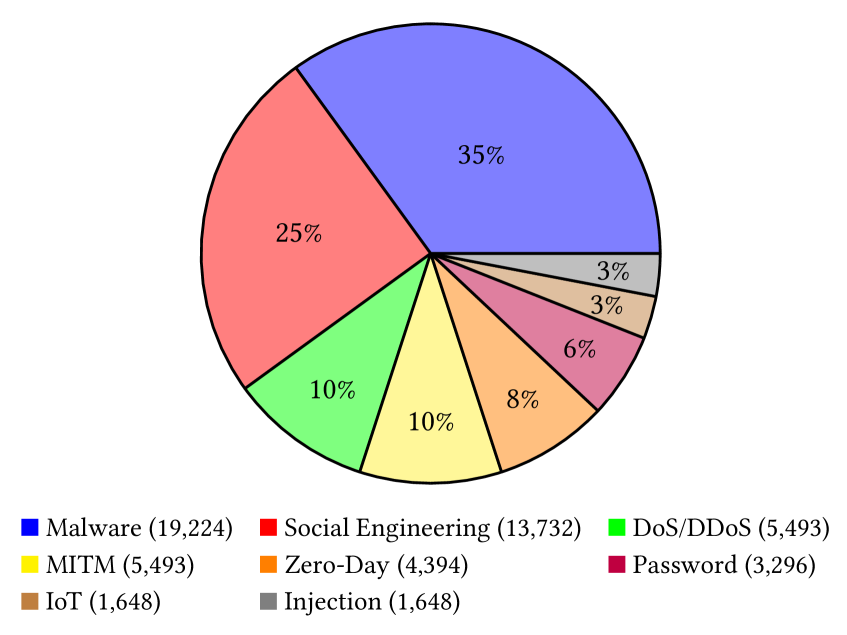
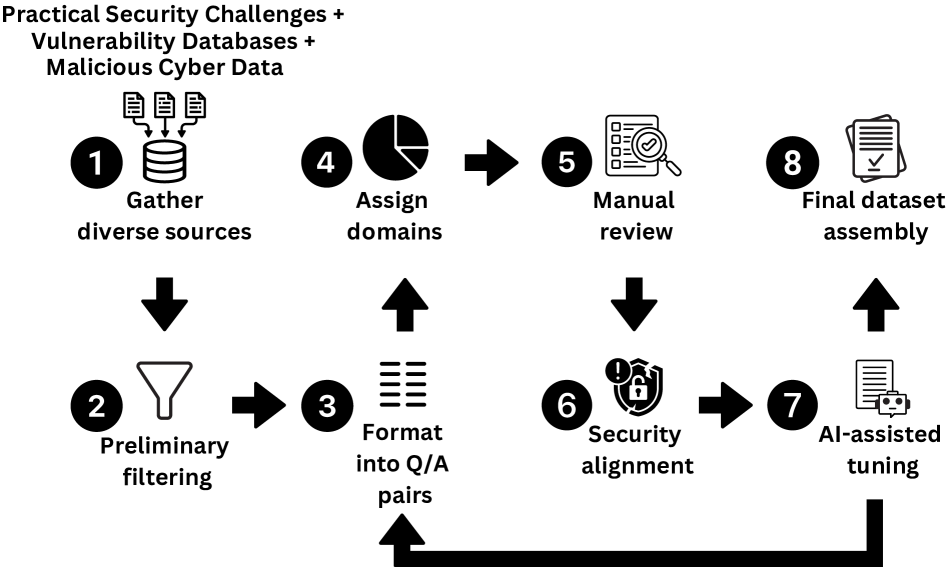
技术框架:整体框架包括数据集构建、模型微调和安全评估三个主要阶段。数据集构建阶段,收集并整理来自CTF挑战、学术论文、行业报告和CVE数据库等多种来源的网络安全相关数据,生成伪恶意指令-响应对。模型微调阶段,使用CyberLLMInstruct数据集对多个开源LLM进行微调。安全评估阶段,采用多种攻击向量(如提示注入)评估微调前后模型的安全性能,并使用安全指标进行量化分析。
关键创新:关键创新在于构建了CyberLLMInstruct数据集,该数据集专门针对网络安全领域,包含了大量的伪恶意样本,能够更有效地评估LLM在对抗性环境下的安全性能。此外,论文还系统地分析了微调对LLM安全性能的影响,揭示了性能与安全之间的权衡关系。
关键设计:CyberLLMInstruct数据集包含54928个伪恶意指令-响应对,涵盖恶意软件分析、网络钓鱼模拟和零日漏洞等多个网络安全任务。安全评估采用多种攻击向量,包括提示注入、对抗性样本等。使用安全指标(如安全性得分)量化评估模型的安全性能。具体参数设置和损失函数等细节未在摘要中提及,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用CyberLLMInstruct数据集进行微调后,LLM在网络安全任务上的准确率最高可达92.50%(CyberMetric)。然而,与此同时,模型的安全性显著下降,例如Llama 3.1 8B针对提示注入的安全性得分从0.95降至0.15。该结果清晰地揭示了微调过程中性能与安全之间的权衡关系。
🎯 应用场景
该研究成果可应用于开发更安全的网络安全LLM。通过使用CyberLLMInstruct数据集评估和改进LLM的安全性,可以降低模型在实际应用中被恶意利用的风险。此外,该研究还可以指导开发更有效的微调策略,在提升性能的同时,保证模型的安全性和可靠性,从而促进LLM在网络安全领域的广泛应用。
📄 摘要(原文)
The integration of large language models (LLMs) into cyber security applications presents both opportunities and critical safety risks. We introduce CyberLLMInstruct, a dataset of 54,928 pseudo-malicious instruction-response pairs spanning cyber security tasks including malware analysis, phishing simulations, and zero-day vulnerabilities. Our comprehensive evaluation using seven open-source LLMs reveals a critical trade-off: while fine-tuning improves cyber security task performance (achieving up to 92.50% accuracy on CyberMetric), it severely compromises safety resilience across all tested models and attack vectors (e.g., Llama 3.1 8B's security score against prompt injection drops from 0.95 to 0.15). The dataset incorporates diverse sources including CTF challenges, academic papers, industry reports, and CVE databases to ensure comprehensive coverage of cyber security domains. Our findings highlight the unique challenges of securing LLMs in adversarial domains and establish the critical need for developing fine-tuning methodologies that balance performance gains with safety preservation in security-sensitive domains.