Reasoning and Sampling-Augmented MCQ Difficulty Prediction via LLMs
作者: Wanyong Feng, Peter Tran, Stephen Sireci, Andrew Lan
分类: cs.AI
发布日期: 2025-03-11
💡 一句话要点
提出基于LLM推理增强和抽样增强的MCQ难度预测方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: MCQ难度预测 大型语言模型 项目反应理论 教育评估 推理增强
📋 核心要点
- 现有MCQ难度预测方法难以充分理解正确选项的复杂性和干扰项的合理性,导致预测精度不足。
- 利用LLM增强MCQ的推理步骤,并结合基于IRT的抽样方法,估计学生选择各选项的可能性,从而更准确地预测难度。
- 实验表明,该方法在数学MCQ数据集上显著优于现有基线,均方误差降低高达28.3%,决定系数提高34.6%。
📝 摘要(中文)
多项选择题(MCQ)的难度是教育评估的关键因素。预测MCQ难度具有挑战性,因为它需要理解得出正确选项的复杂性以及干扰项(即错误选项)的合理性。本文提出了一种新颖的两阶段方法来预测MCQ的难度。首先,为了更好地估计每个MCQ的复杂性,我们使用大型语言模型(LLM)来增强达到每个选项所需的推理步骤。我们不仅使用MCQ本身,还使用这些推理步骤作为输入来预测难度。其次,为了捕捉干扰项的合理性,我们从分布中抽取知识水平,以考虑回答MCQ的学生之间的差异。这种设置受到项目反应理论(IRT)的启发,使我们能够估计学生选择每个选项(包括正确和错误选项)的可能性。我们使用基于Kullback-Leibler (KL)散度的正则化目标将这些预测与其真实值对齐,并使用估计的可能性来预测MCQ难度。我们在两个真实世界的数学MCQ和响应数据集上评估了我们的方法,这些数据集具有使用IRT估计的真实难度值。实验结果表明,我们的方法优于所有基线,均方误差降低高达28.3%,决定系数提高34.6%。我们还定性地讨论了我们的新方法如何在预测MCQ难度方面产生更高的准确性。
🔬 方法详解
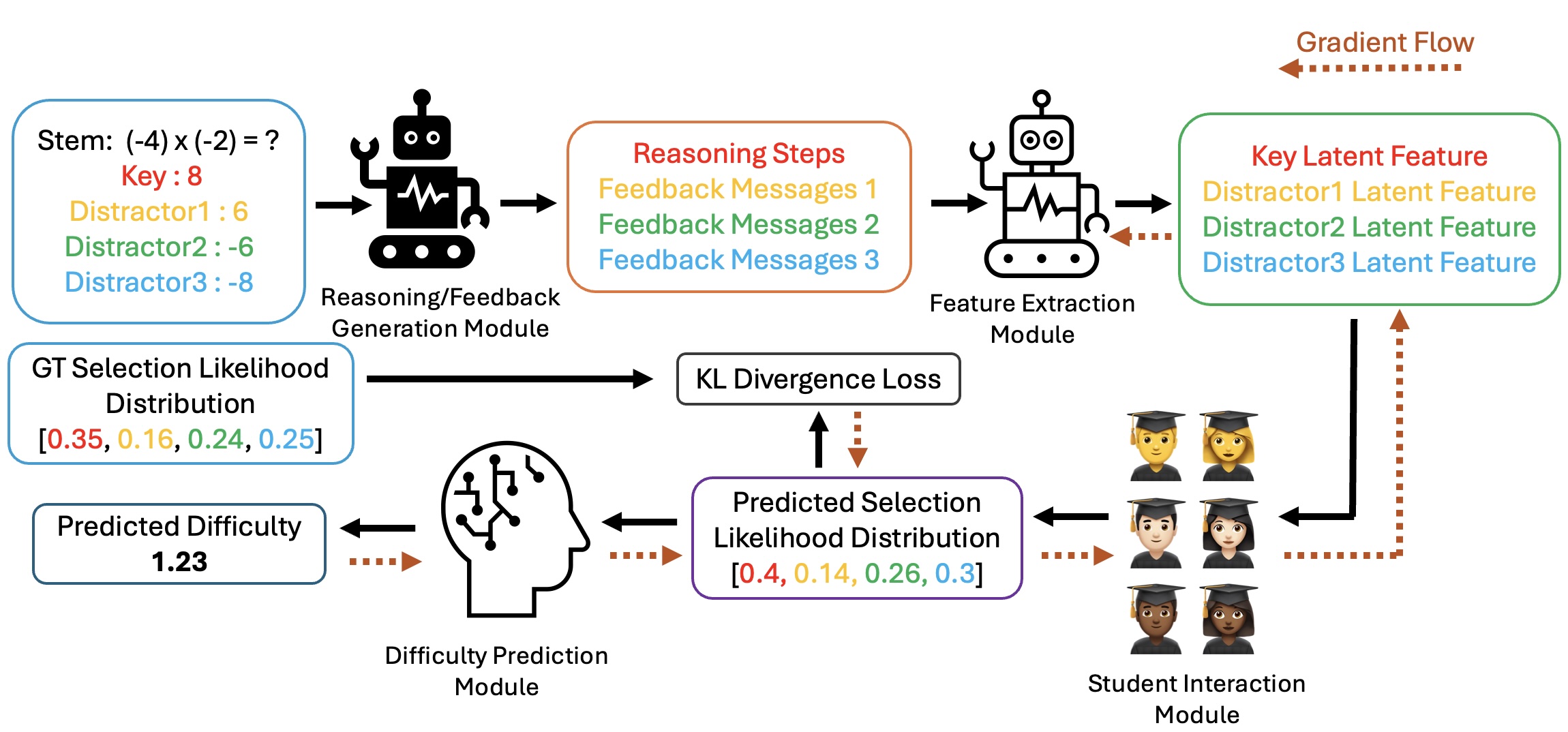
问题定义:论文旨在解决多项选择题(MCQ)难度预测问题。现有方法的痛点在于难以同时捕捉正确选项推理的复杂性和错误选项(干扰项)的迷惑性,导致预测精度不高。传统方法通常只考虑题目本身的信息,忽略了学生解题过程中的推理步骤和不同学生知识水平的差异。
核心思路:论文的核心思路是利用大型语言模型(LLM)增强对MCQ的理解,并结合基于项目反应理论(IRT)的抽样方法来模拟学生作答过程。通过LLM生成每个选项的推理步骤,从而更全面地评估题目的复杂性。同时,通过从知识水平分布中抽样,模拟不同学生对干扰项的认知,从而更准确地估计每个选项被选择的可能性。
技术框架:该方法包含两个主要阶段:1) LLM推理增强阶段:使用LLM生成每个选项的推理步骤,并将MCQ题目和推理步骤作为输入。2) 基于IRT的抽样和难度预测阶段:从知识水平分布中抽样,模拟学生作答,估计每个选项被选择的可能性。然后,使用Kullback-Leibler (KL)散度将预测的可能性与真实值对齐,并使用估计的可能性来预测MCQ难度。
关键创新:该方法最重要的技术创新点在于结合了LLM的推理能力和IRT的建模思想。与现有方法相比,该方法不仅考虑了题目本身的信息,还考虑了学生解题过程中的推理步骤和不同学生知识水平的差异。通过LLM增强推理和IRT抽样,更全面地评估了MCQ的复杂性和干扰项的迷惑性。
关键设计:在LLM推理增强阶段,使用了特定的prompt工程来引导LLM生成高质量的推理步骤。在基于IRT的抽样阶段,使用了特定的知识水平分布(具体分布未知)来模拟学生的能力差异。损失函数使用了基于KL散度的正则化目标,用于对齐预测的可能性和真实值。具体网络结构未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在两个真实世界的数学MCQ数据集上显著优于所有基线方法。具体而言,该方法在均方误差(MSE)方面降低了高达28.3%,在决定系数(R-squared)方面提高了高达34.6%。这些结果表明,该方法能够更准确地预测MCQ难度,具有很强的实用价值。
🎯 应用场景
该研究成果可应用于在线教育平台、智能题库构建、自适应学习系统等领域。通过准确预测MCQ难度,可以帮助教师更好地设计教学内容,为学生提供个性化的学习体验,并提高教育评估的有效性。此外,该方法还可以扩展到其他类型的教育评估题目难度预测。
📄 摘要(原文)
The difficulty of multiple-choice questions (MCQs) is a crucial factor for educational assessments. Predicting MCQ difficulty is challenging since it requires understanding both the complexity of reaching the correct option and the plausibility of distractors, i.e., incorrect options. In this paper, we propose a novel, two-stage method to predict the difficulty of MCQs. First, to better estimate the complexity of each MCQ, we use large language models (LLMs) to augment the reasoning steps required to reach each option. We use not just the MCQ itself but also these reasoning steps as input to predict the difficulty. Second, to capture the plausibility of distractors, we sample knowledge levels from a distribution to account for variation among students responding to the MCQ. This setup, inspired by item response theory (IRT), enable us to estimate the likelihood of students selecting each (both correct and incorrect) option. We align these predictions with their ground truth values, using a Kullback-Leibler (KL) divergence-based regularization objective, and use estimated likelihoods to predict MCQ difficulty. We evaluate our method on two real-world \emph{math} MCQ and response datasets with ground truth difficulty values estimated using IRT. Experimental results show that our method outperforms all baselines, up to a 28.3\% reduction in mean squared error and a 34.6\% improvement in the coefficient of determination. We also qualitatively discuss how our novel method results in higher accuracy in predicting MCQ difficulty.