TPU-Gen: LLM-Driven Custom Tensor Processing Unit Generator
作者: Deepak Vungarala, Mohammed E. Elbtity, Sumiya Syed, Sakila Alam, Kartik Pandit, Arnob Ghosh, Ramtin Zand, Shaahin Angizi
分类: cs.AR, cs.AI
发布日期: 2025-03-07
备注: 8 Pages, 9 Figures, 5 Tables
💡 一句话要点
TPU-Gen:基于LLM的定制张量处理器生成器,提升设计效率和性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 张量处理器 大型语言模型 硬件生成 脉动阵列 检索增强生成
📋 核心要点
- 现有TPU设计面临领域知识要求高、手动设计耗时、缺乏高质量数据集等挑战。
- TPU-Gen利用LLM和RAG,自动化TPU生成,支持精确和近似设计,并提供开源数据集。
- 实验表明,TPU-Gen生成的TPU在面积和功耗上分别平均降低92%和96%,性能显著提升。
📝 摘要(中文)
深度神经网络(DNN)日益增长的复杂性和规模需要专门的张量加速器,例如张量处理单元(TPU),以满足各种计算和能源效率要求。然而,设计最佳TPU仍然具有挑战性,因为需要高水平的领域专业知识、大量的手动设计时间和缺乏高质量的领域特定数据集。本文介绍了TPU-Gen,这是第一个基于大型语言模型(LLM)的框架,旨在自动化精确和近似的TPU生成过程,重点是脉动阵列架构。TPU-Gen由一个精心策划、全面且开源的数据集支持,该数据集涵盖了广泛的空间阵列设计和近似乘法累加单元,从而能够为不同的DNN工作负载进行设计重用、适应和定制。所提出的框架利用检索增强生成(RAG)作为数据稀缺硬件领域构建LLM的有效解决方案,解决了最令人感兴趣的问题,即幻觉。TPU-Gen通过有效的硬件生成流水线将高级架构规范转换为优化的低级实现。我们广泛的实验评估表明,与手动优化参考值相比,面积和功耗平均降低了92%和96%,从而实现了卓越的性能、功耗和面积效率。这些结果为推动由LLM驱动的下一代设计自动化工具的进步树立了新的标准。
🔬 方法详解
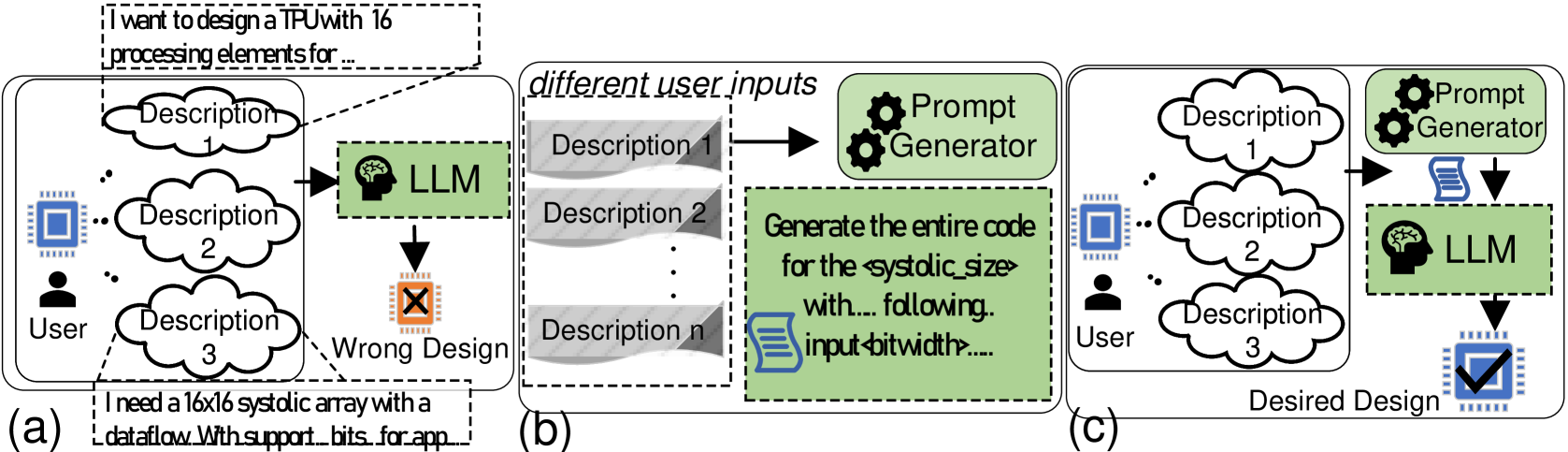
问题定义:论文旨在解决手动设计TPU的效率低、成本高的问题。现有方法依赖于领域专家,设计周期长,难以针对特定DNN工作负载进行优化,并且缺乏高质量的训练数据来支持自动化设计。
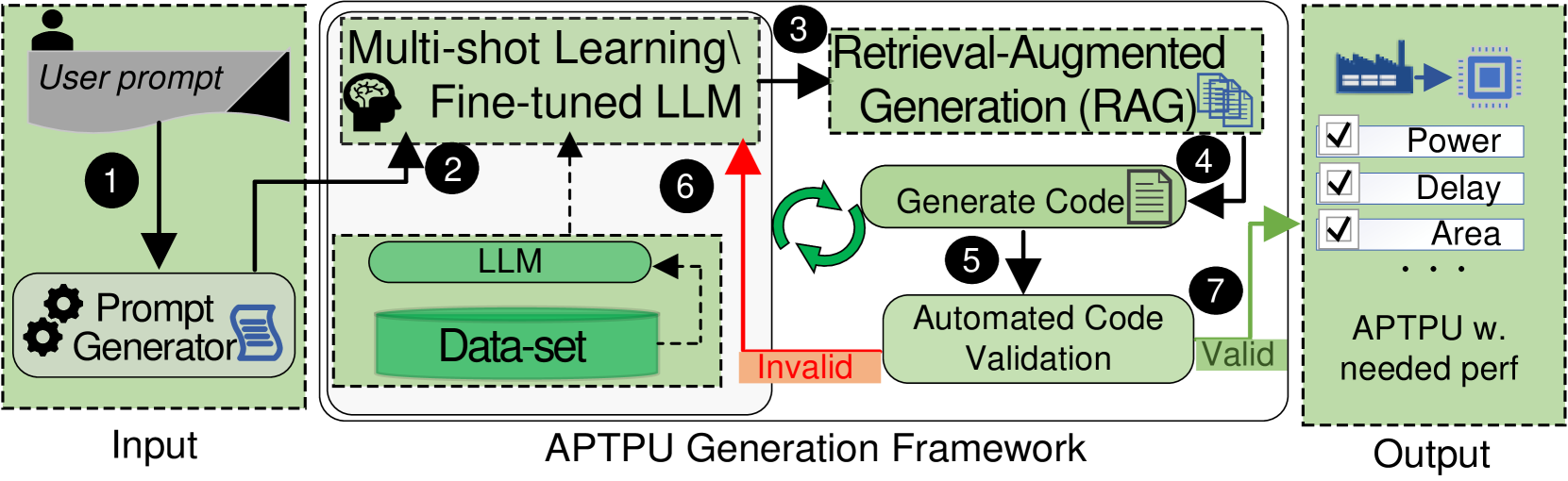
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大生成能力,结合检索增强生成(RAG)技术,自动化TPU的设计过程。通过学习大量的硬件设计数据,LLM可以根据用户输入的高级架构规范,生成优化的低级硬件实现。RAG技术用于缓解LLM在数据稀缺领域的“幻觉”问题,提高生成结果的可靠性。
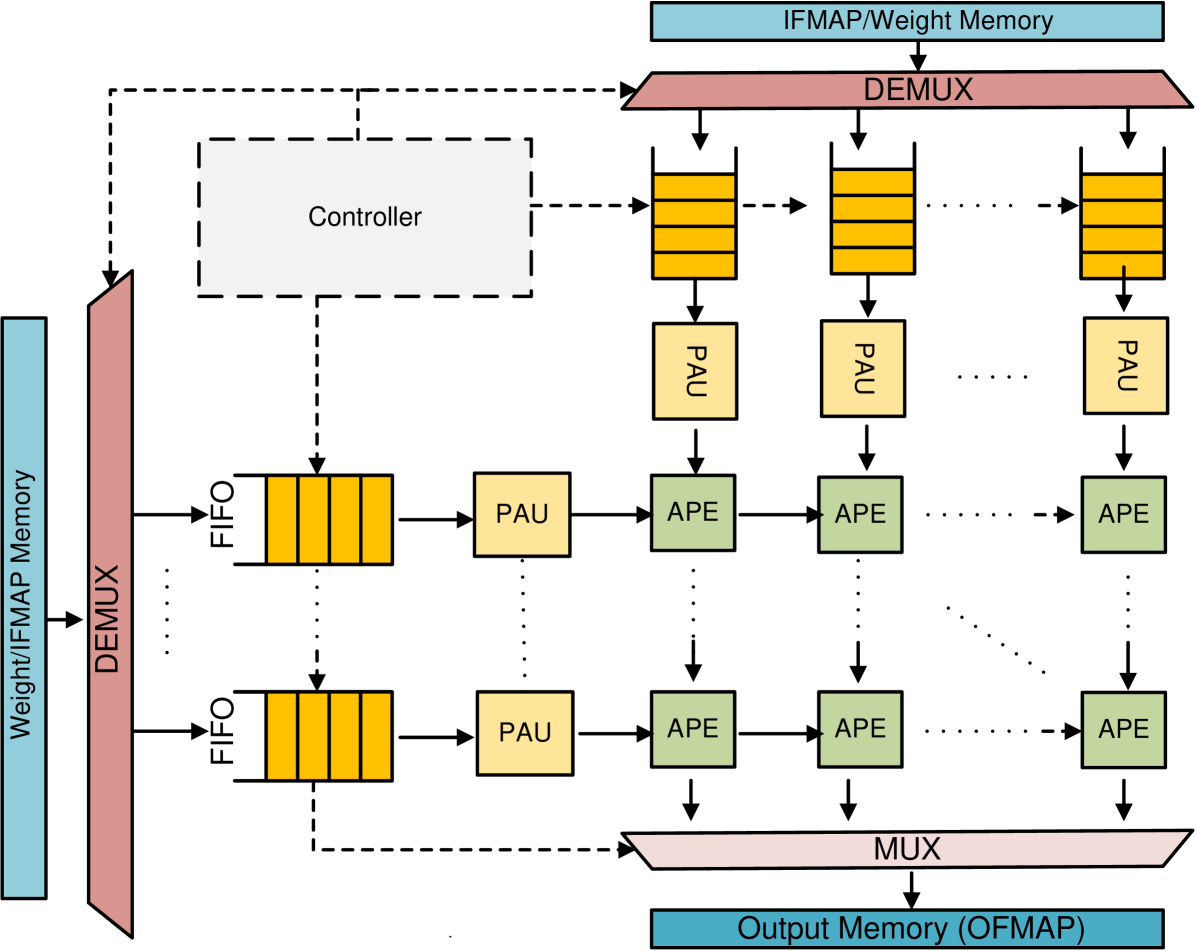
技术框架:TPU-Gen框架主要包含以下几个模块:1) 数据集构建模块:构建包含各种空间阵列设计和近似乘法累加单元的开源数据集。2) LLM训练模块:使用构建的数据集训练LLM,使其具备硬件设计能力。3) RAG模块:在LLM生成过程中,检索相关设计信息,增强生成结果的准确性。4) 硬件生成流水线:将LLM生成的低级实现转换为可综合的硬件描述语言代码。
关键创新:该论文的关键创新在于将LLM和RAG技术应用于TPU设计领域,实现了自动化硬件生成。与传统的手动设计方法相比,TPU-Gen可以显著缩短设计周期,降低设计成本,并提高设计质量。此外,该论文还构建了一个全面的开源数据集,为后续研究提供了基础。
关键设计:TPU-Gen的关键设计包括:1) 数据集的选择和预处理:选择包含丰富硬件设计信息的数据集,并进行清洗和标注。2) LLM的架构选择和训练策略:选择适合硬件设计任务的LLM架构,并采用合适的训练策略,如微调和强化学习。3) RAG的检索策略:设计高效的检索策略,快速找到与当前设计需求相关的设计信息。4) 硬件生成流水线的优化:优化硬件生成流水线,提高生成代码的质量和效率。
🖼️ 关键图片
📊 实验亮点
实验结果表明,TPU-Gen生成的TPU在面积和功耗上与手动优化参考值相比,分别平均降低了92%和96%。这表明TPU-Gen能够显著提高TPU的设计效率和性能,为深度学习应用提供更高效的硬件加速解决方案。该结果验证了LLM在硬件设计领域的潜力。
🎯 应用场景
TPU-Gen可应用于各种需要定制化张量加速器的场景,例如边缘计算、嵌入式系统和高性能计算。它可以帮助硬件工程师快速设计和优化TPU,以满足特定应用的需求,从而加速深度学习模型的部署和应用。此外,该研究还可以促进LLM在硬件设计领域的应用,推动下一代设计自动化工具的发展。
📄 摘要(原文)
The increasing complexity and scale of Deep Neural Networks (DNNs) necessitate specialized tensor accelerators, such as Tensor Processing Units (TPUs), to meet various computational and energy efficiency requirements. Nevertheless, designing optimal TPU remains challenging due to the high domain expertise level, considerable manual design time, and lack of high-quality, domain-specific datasets. This paper introduces TPU-Gen, the first Large Language Model (LLM) based framework designed to automate the exact and approximate TPU generation process, focusing on systolic array architectures. TPU-Gen is supported with a meticulously curated, comprehensive, and open-source dataset that covers a wide range of spatial array designs and approximate multiply-and-accumulate units, enabling design reuse, adaptation, and customization for different DNN workloads. The proposed framework leverages Retrieval-Augmented Generation (RAG) as an effective solution for a data-scare hardware domain in building LLMs, addressing the most intriguing issue, hallucinations. TPU-Gen transforms high-level architectural specifications into optimized low-level implementations through an effective hardware generation pipeline. Our extensive experimental evaluations demonstrate superior performance, power, and area efficiency, with an average reduction in area and power of 92\% and 96\% from the manual optimization reference values. These results set new standards for driving advancements in next-generation design automation tools powered by LLMs.