Enhancing Reasoning with Collaboration and Memory
作者: Julie Michelman, Nasrin Baratalipour, Matthew Abueg
分类: cs.AI, cs.LG
发布日期: 2025-03-07
备注: 17 pages, 6 figures
💡 一句话要点
提出基于协作和记忆增强的大语言模型推理框架,提升复杂推理任务性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 多智能体协作 记忆增强 推理 知识检索
📋 核心要点
- 现有LLM在复杂推理任务中面临挑战,尤其是在利用外部知识和经验进行持续学习方面。
- 论文提出一种协作式学习框架,通过多智能体协同推理和记忆库的构建,提升LLM的推理能力。
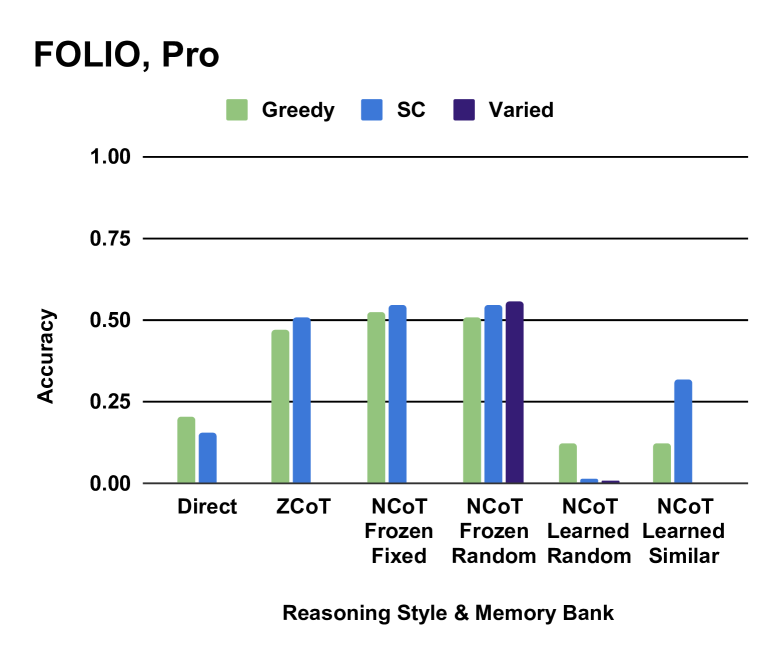
- 实验结果表明,随机范例选择在某些情况下优于更复杂的检索方法,并揭示了范例选择对模型性能的影响。
📝 摘要(中文)
本文设想了一个持续协作学习系统,其中大语言模型(LLM)智能体群组协同解决推理问题,并利用集体构建的记忆来提升性能。该研究为构建此类系统奠定了基础,研究了思维链推理风格、多智能体协作和记忆库的互操作性。不同于自洽性方法中相同的智能体,本文引入了具有不同范例的多样化上下文智能体,以及替代投票的摘要智能体。研究生成了冻结的和持续学习的范例记忆库,并将它们与固定的、随机的和基于相似性的检索机制配对。系统的研究揭示了各种方法对两个LLM在三个基础推理任务中的推理性能的贡献,表明随机范例选择通常可以胜过更原则性的方法,并且在某些任务中,包含任何范例只会分散弱模型和强模型的注意力。
🔬 方法详解
问题定义:现有的大语言模型在解决复杂推理问题时,往往缺乏有效的机制来利用历史经验和外部知识。传统的自洽性方法依赖于相同智能体的多次推理结果投票,无法充分利用不同视角的知识。此外,如何有效地从记忆库中检索相关信息,避免无关信息干扰,也是一个挑战。
核心思路:本文的核心思路是构建一个协作式学习系统,其中多个具有不同上下文的智能体协同工作,并通过记忆库来存储和检索历史经验。通过引入多样化的智能体和不同的检索机制,旨在提高推理的准确性和效率。
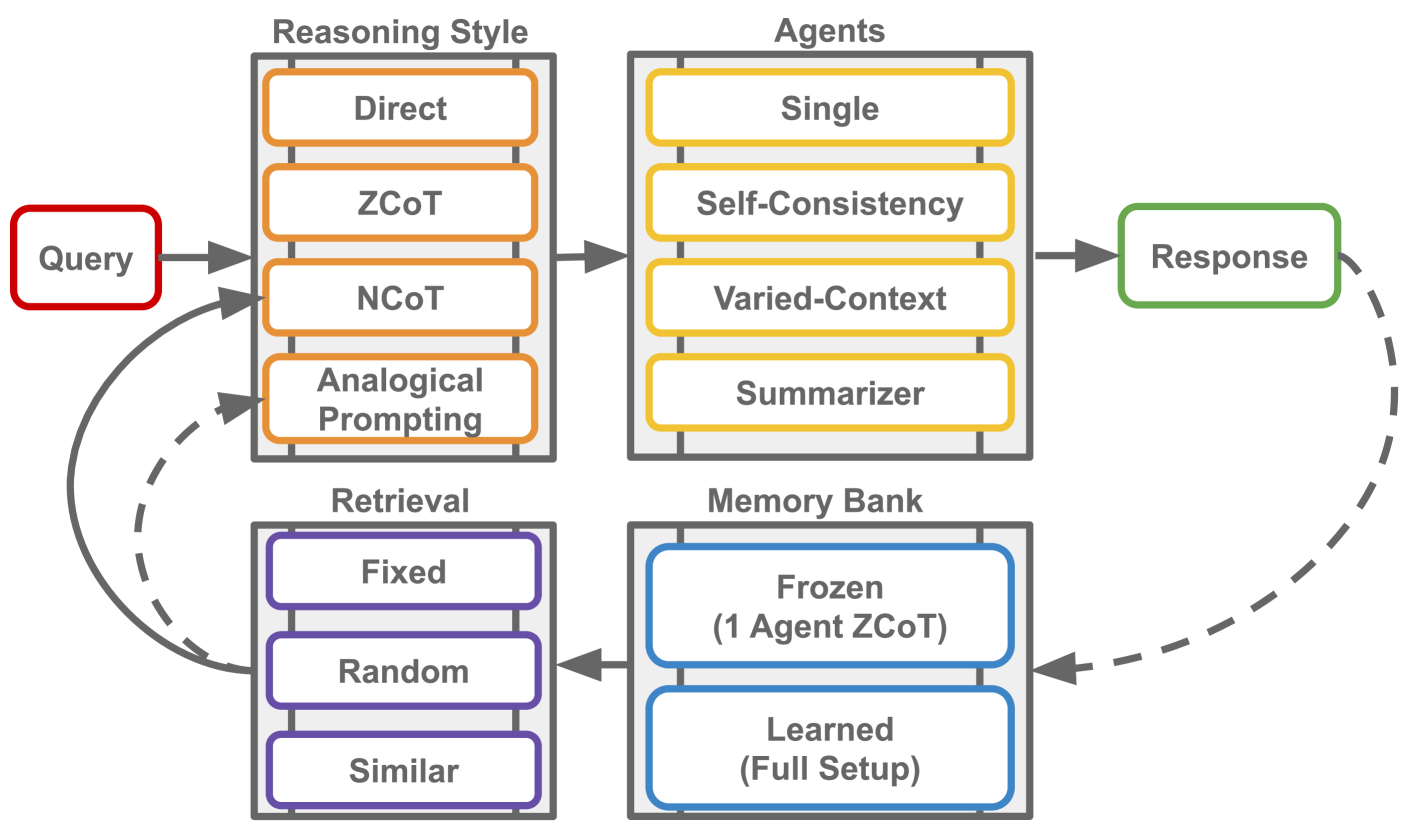
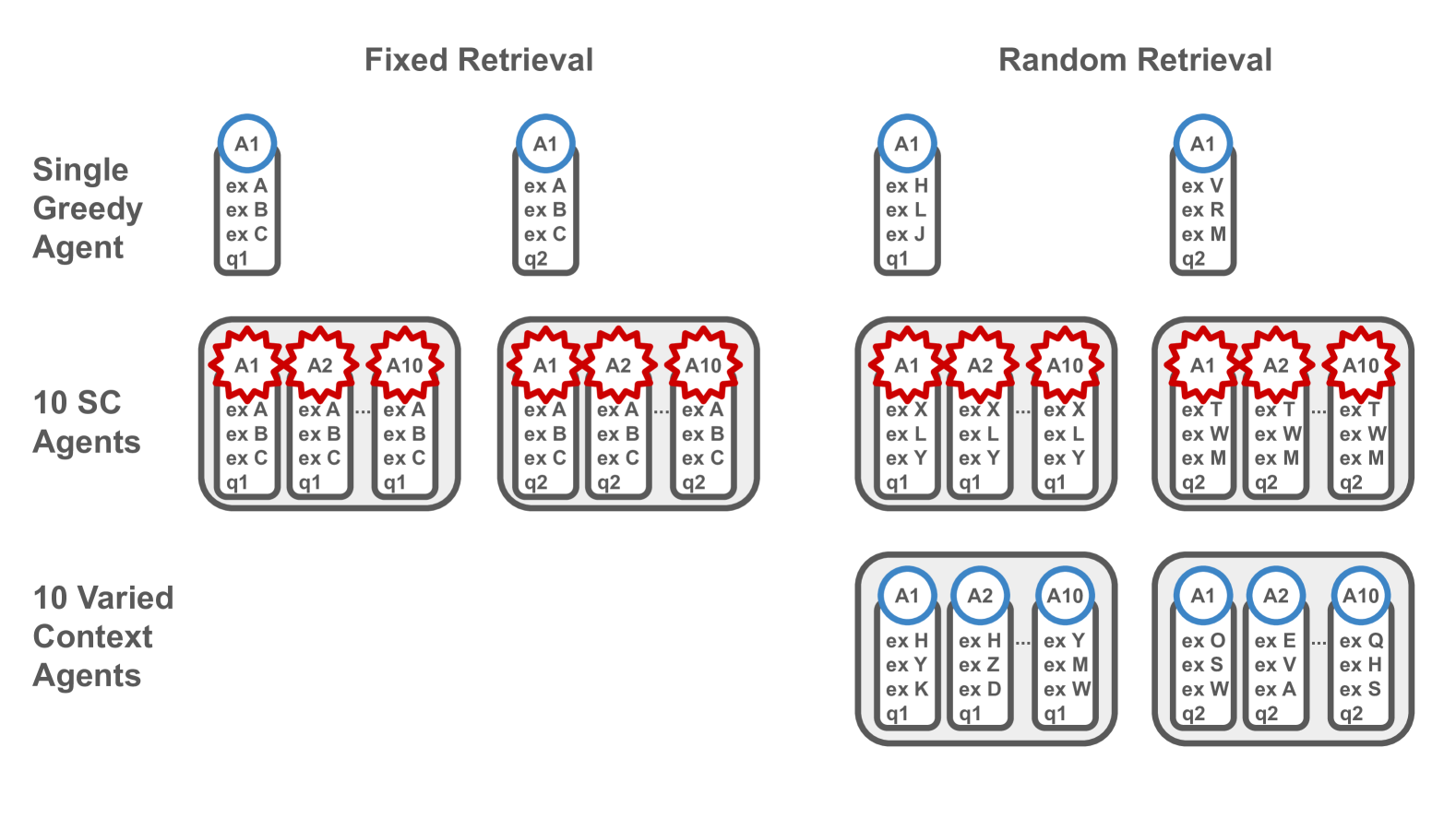
技术框架:该框架包含以下几个主要模块:1) 多样化上下文智能体:这些智能体具有不同的范例,从而提供不同的视角;2) 摘要智能体:用于整合多个智能体的推理结果,替代传统的投票机制;3) 记忆库:存储历史推理的范例,可以是冻结的或持续学习的;4) 检索机制:用于从记忆库中检索相关范例,包括固定、随机和基于相似性的检索。整个流程是,首先由多样化上下文智能体进行推理,然后摘要智能体整合结果,同时从记忆库中检索相关范例,最后结合检索到的范例进行最终推理。
关键创新:该论文的关键创新在于:1) 引入了多样化上下文智能体,扩展了自洽性方法的智能体类型;2) 使用摘要智能体替代投票机制,提高了结果整合的效率;3) 系统地研究了不同检索机制对推理性能的影响,发现随机范例选择在某些情况下优于更复杂的检索方法。
关键设计:论文中,记忆库的构建方式包括冻结的和持续学习的两种。冻结的记忆库是在训练前预先构建的,而持续学习的记忆库则是在推理过程中不断更新的。检索机制包括固定检索(检索固定的范例)、随机检索(随机选择范例)和基于相似性的检索(根据输入与范例的相似度选择范例)。具体的相似度计算方法和摘要智能体的实现细节在论文中可能没有详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,随机范例选择在某些任务中可以胜过更原则性的方法,这颠覆了以往的认知。此外,研究还发现,在某些任务中,包含任何范例反而会分散模型的注意力,降低性能。这些发现为未来研究提供了重要的启示,即范例选择和检索策略需要根据具体任务进行优化。
🎯 应用场景
该研究成果可应用于需要复杂推理和知识整合的领域,如智能客服、医疗诊断、金融分析等。通过构建协作式学习系统,可以提升LLM在这些领域的应用效果,并实现持续学习和知识积累。未来的研究可以探索更有效的记忆库构建和检索方法,以及更复杂的智能体协作策略。
📄 摘要(原文)
We envision a continuous collaborative learning system where groups of LLM agents work together to solve reasoning problems, drawing on memory they collectively build to improve performance as they gain experience. This work establishes the foundations for such a system by studying the interoperability of chain-of-thought reasoning styles, multi-agent collaboration, and memory banks. Extending beyond the identical agents of self-consistency, we introduce varied-context agents with diverse exemplars and a summarizer agent in place of voting. We generate frozen and continuously learned memory banks of exemplars and pair them with fixed, random, and similarity-based retrieval mechanisms. Our systematic study reveals where various methods contribute to reasoning performance of two LLMs on three grounded reasoning tasks, showing that random exemplar selection can often beat more principled approaches, and in some tasks, inclusion of any exemplars serves only to distract both weak and strong models.