Evaluating Large Language Models in Code Generation: INFINITE Methodology for Defining the Inference Index
作者: Nicholas Christakis, Dimitris Drikakis
分类: cs.SE, cs.AI
发布日期: 2025-03-07
备注: 20 pages, 6 figures
期刊: Appl. Sci. 2025, 15, 3784
DOI: 10.3390/app15073784
💡 一句话要点
提出INFINITE方法,评估大语言模型在代码生成中的推理性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 代码生成 推理指标 模型评估 LSTM 气象预测
📋 核心要点
- 现有代码生成评估方法侧重于准确性,忽略了效率、一致性等关键因素。
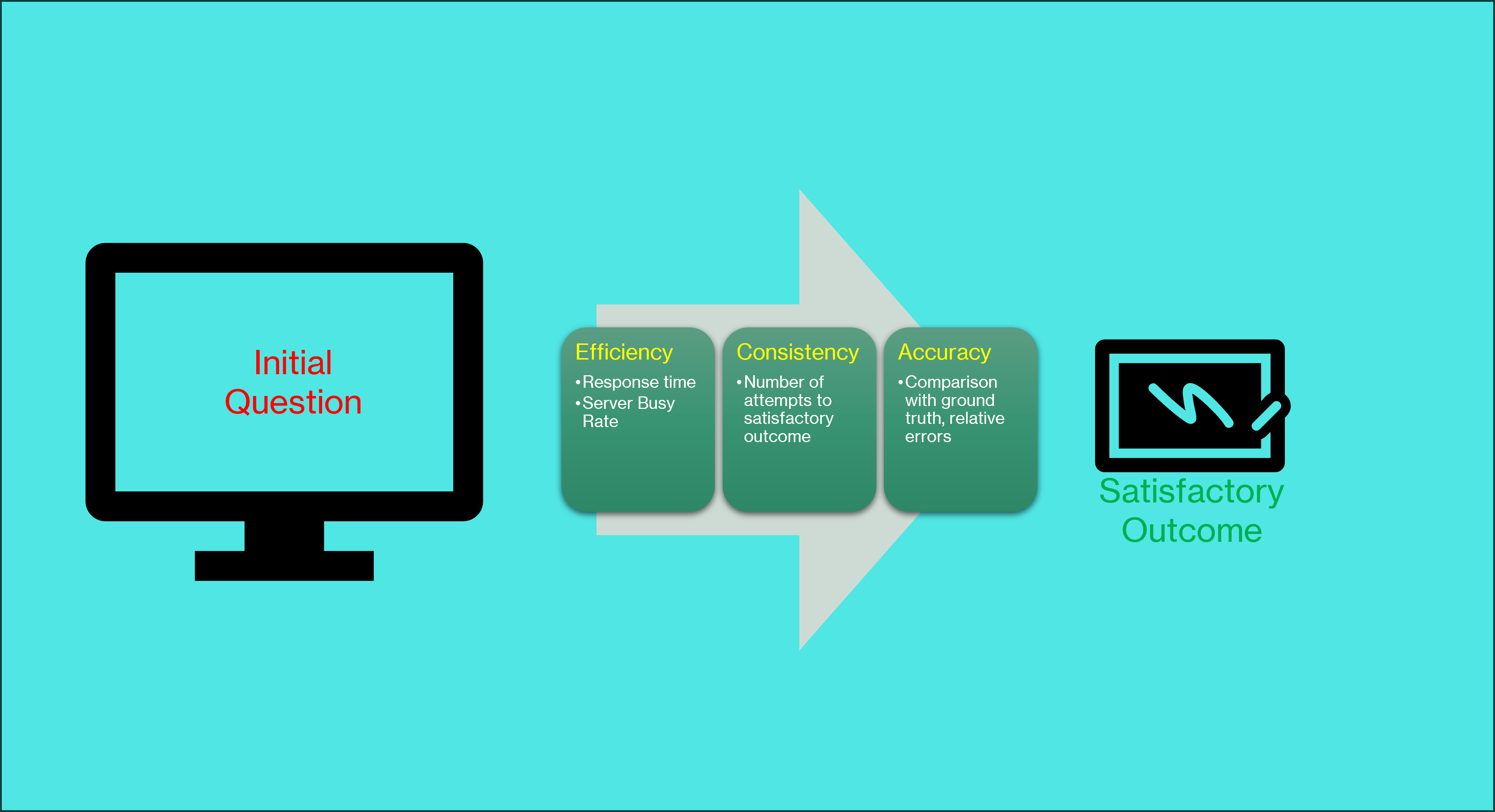
- 提出INFINITE方法,综合评估LLM在代码生成中的效率、一致性和准确性。
- 实验表明,GPT-4o在气象变量预测LSTM模型代码生成方面表现优异。
📝 摘要(中文)
本研究提出了一种新的推理指标(InI)方法,名为INFINITE(INFerence INdex In Testing model Effectiveness methodology),旨在评估大型语言模型(LLM)在代码生成任务中的性能。InI指标提供了一个全面的评估,侧重于三个关键组成部分:效率、一致性和准确性。该方法涵盖了基于时间的效率、响应质量和模型输出的稳定性,从而提供了对LLM性能的透彻理解,超越了传统的准确性指标。我们将此方法应用于比较OpenAI的GPT-4o(GPT)、OpenAI-o1 pro(OAI1)和OpenAI-o3 mini-high(OAI3)在生成用于预测气象变量(如温度、相对湿度和风速)的LSTM模型Python代码方面的性能。我们的研究结果表明,GPT在准确性和工作流程效率方面优于OAI1,并且与OAI3相当。该研究表明,借助LLM的代码生成,通过有效的提示和改进,可以产生与专家设计的模型相似的结果。GPT的性能优势突出了广泛使用和用户反馈的好处。
🔬 方法详解
问题定义:论文旨在解决如何全面评估大型语言模型在代码生成任务中的性能问题。现有方法主要关注代码的准确性,忽略了生成代码的效率(例如生成时间)和一致性(例如多次生成结果的差异)。这些因素对于实际应用至关重要,因为低效或不一致的代码生成会严重影响开发效率和系统可靠性。
核心思路:论文的核心思路是构建一个综合的推理指标(Inference Index, InI),该指标不仅考虑代码的准确性,还包括效率和一致性。通过对这三个维度进行量化评估,可以更全面地了解LLM在代码生成方面的能力,从而更好地选择和优化LLM。INFINITE方法旨在系统化地测试模型有效性,并提供可重复的评估流程。
技术框架:INFINITE方法包含以下主要步骤:1) 定义代码生成任务;2) 使用不同的LLM生成代码;3) 评估生成代码的效率(例如生成时间)、一致性(例如多次运行结果的方差)和准确性(例如代码是否能够正确执行并达到预期结果);4) 将效率、一致性和准确性指标综合成一个InI指标,用于比较不同LLM的性能。该框架允许研究人员和开发者系统地评估和比较不同的LLM,并选择最适合特定代码生成任务的模型。
关键创新:INFINITE方法的关键创新在于提出了一个综合的推理指标,该指标不仅考虑代码的准确性,还包括效率和一致性。这与现有方法只关注准确性形成了鲜明对比。此外,该方法提供了一个系统化的评估流程,可以重复使用,从而提高了评估结果的可信度和可比性。
关键设计:INFINITE方法中,效率可以通过测量代码生成所需的时间来量化。一致性可以通过多次运行代码并计算结果的方差来评估。准确性可以通过测试代码是否能够正确执行并达到预期结果来评估。具体的指标权重可以根据实际应用的需求进行调整。论文中,LSTM模型的代码生成任务被用作案例研究,展示了如何应用INFINITE方法评估GPT-4o、OAI1和OAI3等LLM的性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在生成用于预测气象变量的LSTM模型Python代码方面,GPT-4o在准确性和工作流程效率方面优于OAI1,并且与OAI3相当。这表明GPT-4o在代码生成方面具有显著优势,能够生成高质量的代码,并提高开发效率。该研究强调了有效提示和模型微调的重要性。
🎯 应用场景
该研究成果可应用于软件开发、自动化测试、数据科学等领域。通过INFINITE方法,开发者可以选择最适合特定任务的LLM,提高代码生成效率和质量。此外,该方法还可以用于评估LLM的改进效果,指导LLM的训练和优化。未来,该方法可以扩展到其他代码生成任务和编程语言。
📄 摘要(原文)
This study introduces a new methodology for an Inference Index (InI), called INFerence INdex In Testing model Effectiveness methodology (INFINITE), aiming to evaluate the performance of Large Language Models (LLMs) in code generation tasks. The InI index provides a comprehensive assessment focusing on three key components: efficiency, consistency, and accuracy. This approach encapsulates time-based efficiency, response quality, and the stability of model outputs, offering a thorough understanding of LLM performance beyond traditional accuracy metrics. We applied this methodology to compare OpenAI's GPT-4o (GPT), OpenAI-o1 pro (OAI1), and OpenAI-o3 mini-high (OAI3) in generating Python code for the Long-Short-Term-Memory (LSTM) model to forecast meteorological variables such as temperature, relative humidity and wind velocity. Our findings demonstrate that GPT outperforms OAI1 and performs comparably to OAI3 regarding accuracy and workflow efficiency. The study reveals that LLM-assisted code generation can produce results similar to expert-designed models with effective prompting and refinement. GPT's performance advantage highlights the benefits of widespread use and user feedback.