AVA: Attentive VLM Agent for Mastering StarCraft II
作者: Weiyu Ma, Yuqian Fu, Zecheng Zhang, Bernard Ghanem, Guohao Li
分类: cs.AI, cs.MA
发布日期: 2025-03-07 (更新: 2025-05-16)
备注: Under Review
🔗 代码/项目: GITHUB
💡 一句话要点
提出AVA:一个基于视觉语言模型且具有注意力机制的星际争霸II智能体
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 星际争霸II 多模态学习 视觉语言模型 强化学习 检索增强生成 游戏AI 注意力机制
📋 核心要点
- 现有星际争霸II智能体依赖抽象状态表示,与人类感知差异大,限制了智能体的生态有效性。
- AVA通过结合视觉和语言输入,模拟人类认知过程,并利用检索增强生成和动态任务分配提升性能。
- 实验表明,AVA在AVACraft环境中无需训练即可达到与传统MARL方法相当的性能,为类人智能体奠定基础。
📝 摘要(中文)
本文介绍了一种多模态星际争霸II智能体,名为Attentive VLM Agent (AVA),旨在使人工智能体的感知与人类游戏体验对齐。 传统的SMAC等框架依赖于抽象的状态表示,与人类感知差异显著,限制了智能体行为的生态有效性。AVA通过结合RGB视觉输入和自然语言观察来模拟人类游戏中的认知过程,从而解决这一局限性。AVA架构包含三个集成组件:(1) 视觉-语言模型,通过专门的自注意力机制增强,用于战略单位目标选择和战场评估;(2) 检索增强生成系统,利用特定领域的星际争霸II知识来指导战术决策;(3) 动态的基于角色的任务分配系统,实现协同多智能体行为。在AVACraft环境中进行的实验评估表明,由基础模型(特别是Qwen-VL和GPT-4o)驱动的AVA无需显式训练即可执行复杂的战术动作,并达到与需要大量训练迭代的传统MARL方法相当的性能。这项工作为开发与人类对齐的星际争霸II智能体奠定了基础,并推进了多模态游戏AI的更广泛研究议程。代码已开源。
🔬 方法详解
问题定义:现有星际争霸II智能体,如基于SMAC的智能体,依赖于抽象的状态表示,这些表示与人类玩家的感知方式存在显著差异。这种差异导致智能体的行为缺乏生态有效性,难以泛化到更复杂、更接近人类游戏体验的场景中。因此,如何设计一种能够像人类一样感知和理解游戏环境的智能体,是本文要解决的核心问题。
核心思路:AVA的核心思路是构建一个多模态的智能体,使其能够同时处理视觉信息(RGB图像)和自然语言信息(游戏观察)。通过模仿人类玩家的感知方式,AVA能够更好地理解游戏环境,并做出更合理的决策。此外,AVA还利用检索增强生成技术,从领域知识库中获取战术信息,并采用动态任务分配机制,实现多智能体之间的协同。
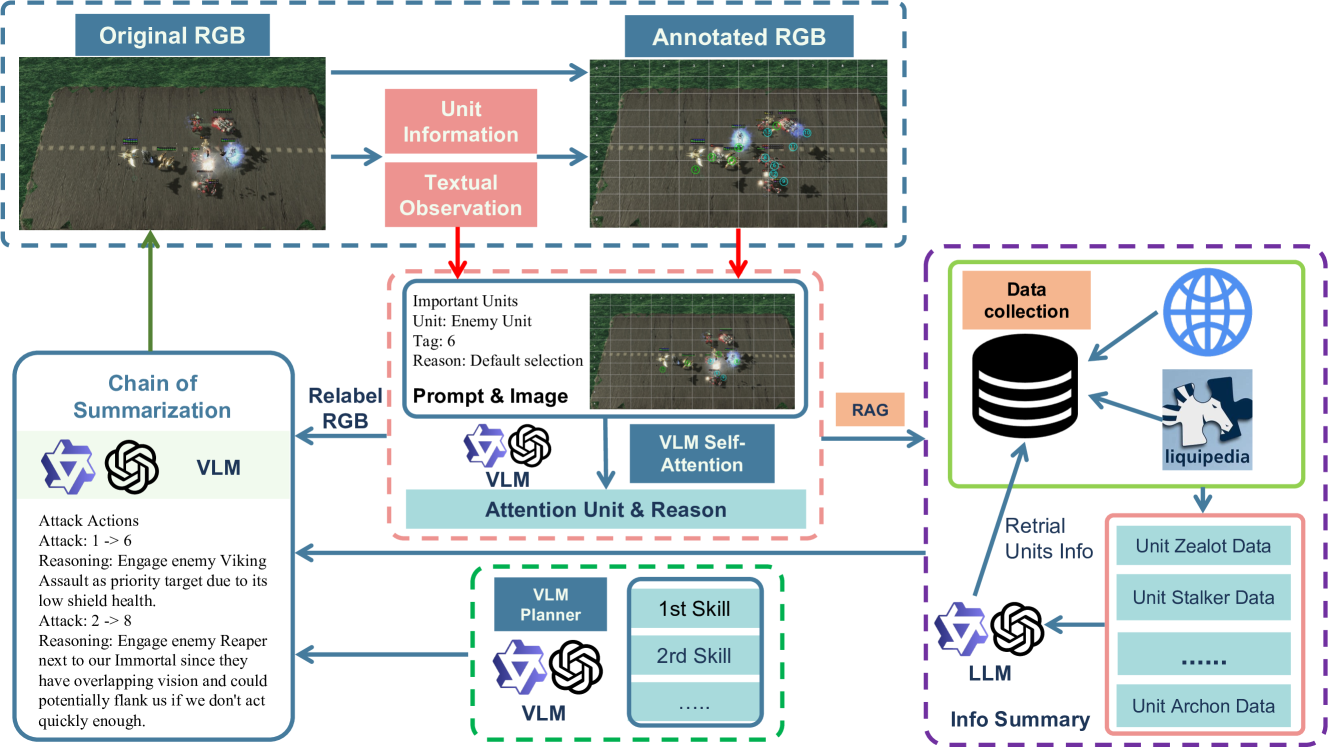
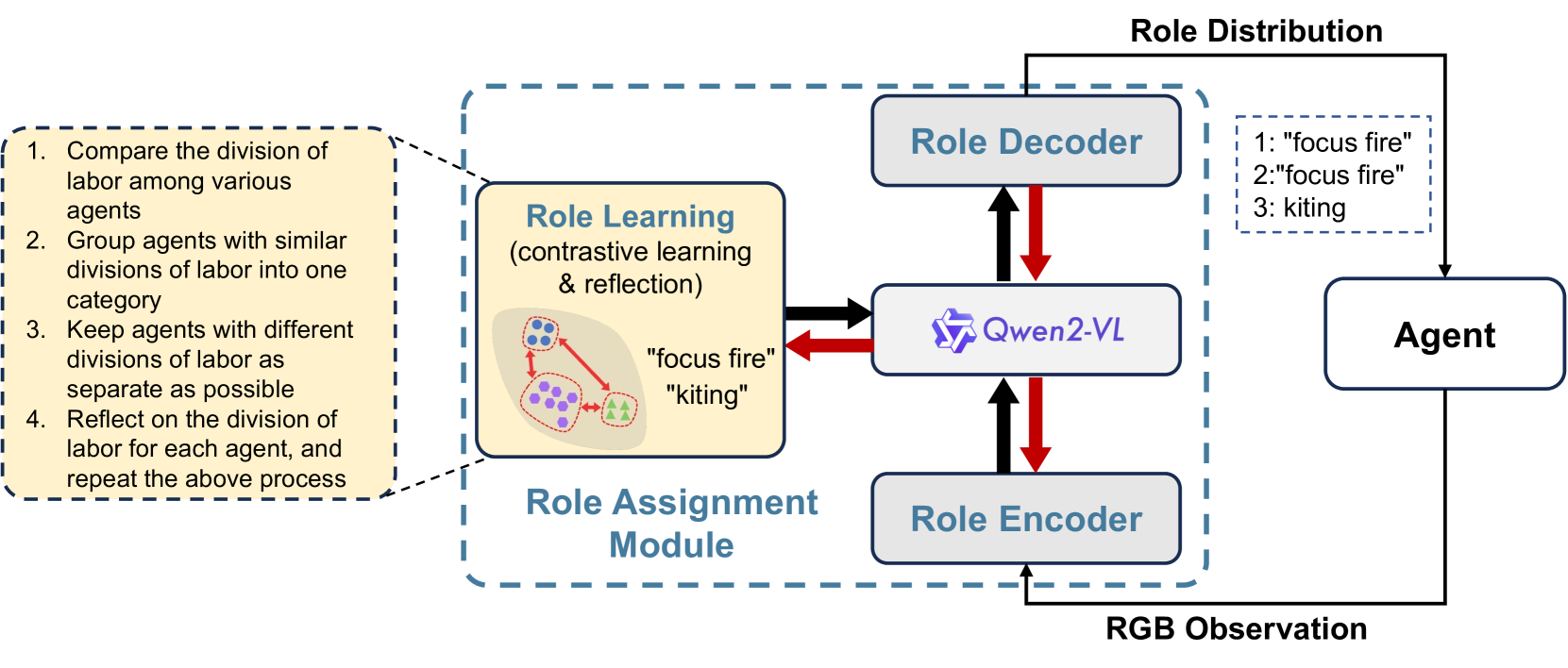
技术框架:AVA的整体架构包含三个主要模块:(1) 视觉-语言模型:用于处理视觉和语言输入,并提取关键信息,例如单位位置、类型和状态。该模型采用自注意力机制,增强了对战略单位目标选择和战场评估的能力。(2) 检索增强生成系统:利用领域知识库(包含星际争霸II的战术信息)来指导战术决策。该系统首先检索与当前游戏状态相关的知识,然后利用这些知识生成战术指令。(3) 动态任务分配系统:负责将任务分配给不同的智能体,并协调它们之间的行为。该系统根据智能体的角色和能力,动态地调整任务分配策略,以实现最佳的团队表现。
关键创新:AVA最重要的技术创新点在于其多模态感知能力和检索增强生成技术。传统智能体通常只依赖于抽象的状态表示,而AVA能够直接从视觉和语言输入中获取信息,从而更全面地理解游戏环境。此外,AVA还利用领域知识库来指导战术决策,这使得它能够做出更明智的选择,并避免一些常见的错误。
关键设计:在视觉-语言模型方面,AVA采用了Qwen-VL和GPT-4o等大型预训练模型作为基础,并针对星际争霸II的特点进行了微调。在检索增强生成系统方面,AVA构建了一个包含大量星际争霸II战术信息的知识库,并设计了一种高效的检索算法,以便快速找到相关的知识。在动态任务分配系统方面,AVA采用了一种基于角色的任务分配策略,每个智能体都被赋予一个特定的角色(例如,攻击者、防御者、支援者),并根据其角色和能力分配任务。
🖼️ 关键图片

📊 实验亮点
AVA在AVACraft环境中进行了评估,结果表明,由Qwen-VL和GPT-4o驱动的AVA无需显式训练即可执行复杂的战术动作,并达到与需要大量训练迭代的传统MARL方法相当的性能。这表明AVA具有很强的泛化能力和学习效率,为开发类人智能体提供了一种新的途径。
🎯 应用场景
该研究成果可应用于游戏AI、机器人控制、自动驾驶等领域。通过模仿人类的感知和决策方式,可以开发出更智能、更可靠的智能体。此外,该研究还为多模态学习和知识增强生成提供了新的思路,有助于推动人工智能技术的进一步发展。未来,该技术有望应用于更复杂的现实世界场景,例如智能制造、智能医疗等。
📄 摘要(原文)
We introduce Attentive VLM Agent (AVA), a multimodal StarCraft II agent that aligns artificial agent perception with the human gameplay experience. Traditional frameworks such as SMAC rely on abstract state representations that diverge significantly from human perception, limiting the ecological validity of agent behavior. Our agent addresses this limitation by incorporating RGB visual inputs and natural language observations that more closely simulate human cognitive processes during gameplay. The AVA architecture consists of three integrated components: (1) a vision-language model enhanced with specialized self-attention mechanisms for strategic unit targeting and battlefield assessment, (2) a retrieval-augmented generation system that leverages domain-specific StarCraft II knowledge to inform tactical decisions, and (3) a dynamic role-based task distribution system that enables coordinated multi-agent behavior. The experimental evaluation in our proposed AVACraft environment, which contains 21 multimodal StarCraft II scenarios, demonstrates that AVA powered by foundation models (specifically Qwen-VL and GPT-4o) can execute complex tactical maneuvers without explicit training, achieving comparable performance to traditional MARL methods that require substantial training iterations. This work establishes a foundation for developing human-aligned StarCraft II agents and advances the broader research agenda of multimodal game AI. Our implementation is available at https://github.com/camel-ai/VLM-Play-StarCraft2.