WritingBench: A Comprehensive Benchmark for Generative Writing
作者: Yuning Wu, Jiahao Mei, Ming Yan, Chenliang Li, Shaopeng Lai, Yuran Ren, Zijia Wang, Ji Zhang, Mengyue Wu, Qin Jin, Fei Huang
分类: cs.AI, cs.CL
发布日期: 2025-03-07 (更新: 2025-11-27)
💡 一句话要点
提出WritingBench,一个全面的生成式写作评估基准,并提出查询相关的评估框架。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 生成式写作 评估基准 大型语言模型 查询相关评估 标准感知评分
📋 核心要点
- 现有写作评估基准缺乏对多样化写作领域和子领域的覆盖,难以全面评估LLMs的写作能力。
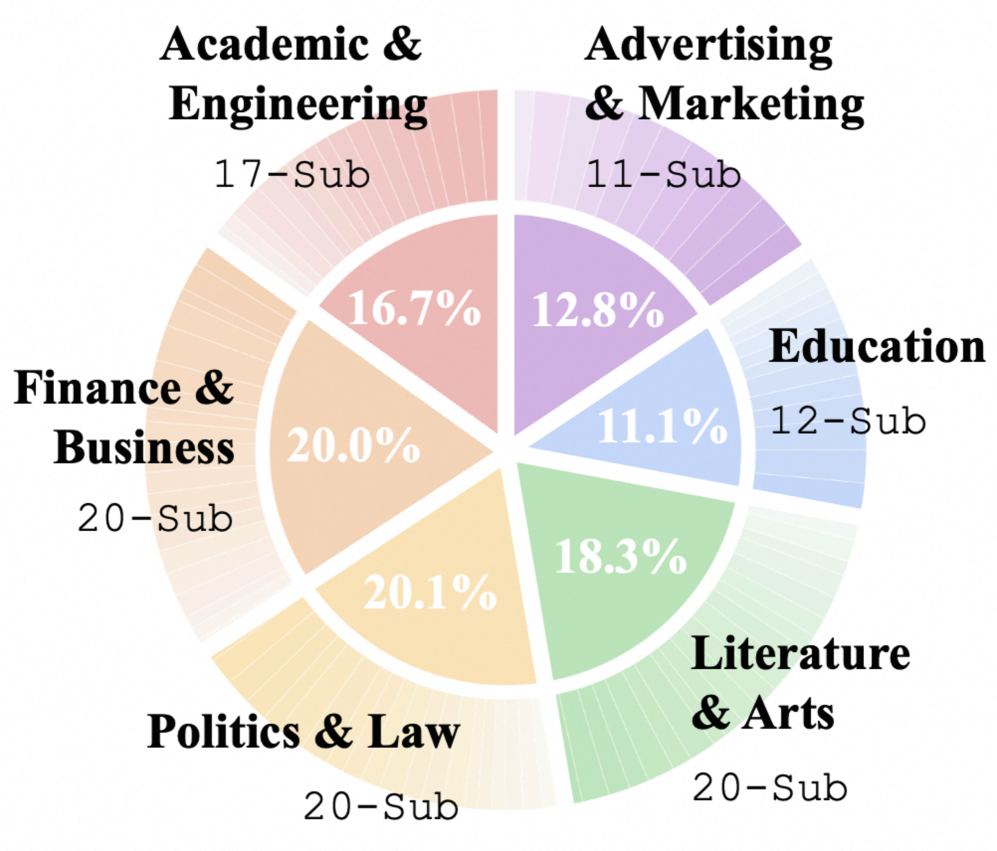
- WritingBench通过构建包含6个核心写作领域和100个子领域的综合基准,填补了现有评估体系的空白。
- 提出的查询相关评估框架和微调的评论模型,使得LLMs能够动态生成评估标准并进行标准感知的评分,提升了评估的准确性。
📝 摘要(中文)
大型语言模型(LLMs)的最新进展显著提升了文本生成能力,但评估其在生成式写作方面的表现仍然是一个挑战。现有的基准主要集中在通用文本生成或写作任务有限,未能捕捉到各个领域高质量书面内容的多样化需求。为了弥补这一差距,我们提出了WritingBench,这是一个全面的基准,旨在评估LLMs在6个核心写作领域和100个子领域的能力。我们进一步提出了一个查询相关的评估框架,该框架使LLMs能够动态生成特定于实例的评估标准。该框架辅以一个经过微调的评论模型,用于进行标准感知的评分,从而能够评估风格、格式和长度。该框架的有效性通过其数据管理能力得到进一步证明,该能力使一个7B参数的模型在写作方面优于GPT-4o的性能。我们开源了该基准,以及评估工具和模块化框架组件,以推进LLMs在写作领域的发展。
🔬 方法详解
问题定义:现有的大语言模型在文本生成方面取得了显著进展,但在生成式写作领域的评估仍然面临挑战。现有的评估基准要么侧重于通用的文本生成,要么在写作任务上存在局限性,无法全面捕捉不同领域高质量写作内容的多样化需求。因此,如何构建一个能够全面、准确评估LLMs写作能力的基准是一个亟待解决的问题。
核心思路:WritingBench的核心思路是构建一个包含多个写作领域和子领域的综合性基准,并提出一个查询相关的评估框架。该框架允许LLMs根据具体的写作任务动态生成评估标准,并使用一个微调的评论模型进行标准感知的评分。通过这种方式,可以更准确地评估LLMs在不同写作任务中的表现。
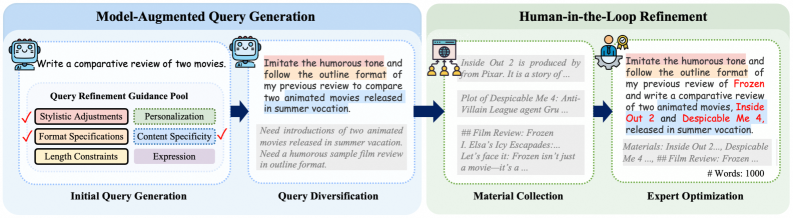
技术框架:WritingBench的整体框架包括以下几个主要组成部分:1) 写作基准数据集,包含6个核心写作领域和100个子领域;2) 查询相关的评估框架,允许LLMs动态生成评估标准;3) 微调的评论模型,用于进行标准感知的评分。整个流程是,首先给定一个写作任务,LLM生成文本,然后评估框架根据任务生成评估标准,最后评论模型根据评估标准对生成的文本进行评分。
关键创新:WritingBench的关键创新在于提出了查询相关的评估框架。与传统的固定评估标准不同,该框架允许LLMs根据具体的写作任务动态生成评估标准。这种方式可以更灵活、更准确地评估LLMs在不同写作任务中的表现。此外,使用微调的评论模型进行标准感知的评分也提高了评估的准确性。
关键设计:查询相关的评估框架的关键设计在于如何让LLMs生成合理的评估标准。论文中可能使用了prompt engineering等技术,引导LLMs根据写作任务的特点生成相应的评估标准。评论模型的微调可能使用了对比学习等方法,使其能够更好地理解和应用评估标准进行评分。具体的参数设置、损失函数、网络结构等技术细节在论文中可能有所描述,但此处未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用WritingBench进行数据管理后,一个7B参数的模型在写作方面的性能优于GPT-4o。这表明WritingBench不仅可以用于评估LLMs的写作能力,还可以用于提升LLMs的写作性能。具体的性能提升幅度未知,但结果表明WritingBench具有显著的实际价值。
🎯 应用场景
WritingBench可应用于各种需要高质量文本生成的场景,例如自动内容创作、智能写作辅助、教育评估等。该基准可以帮助研究人员和开发者更好地了解LLMs在写作方面的能力,并推动LLMs在写作领域的进一步发展。此外,该基准还可以用于评估和比较不同LLMs的写作性能,为用户选择合适的LLM提供参考。
📄 摘要(原文)
Recent advancements in large language models (LLMs) have significantly enhanced text generation capabilities, yet evaluating their performance in generative writing remains a challenge. Existing benchmarks primarily focus on generic text generation or limited in writing tasks, failing to capture the diverse requirements of high-quality written contents across various domains. To bridge this gap, we present WritingBench, a comprehensive benchmark designed to evaluate LLMs across 6 core writing domains and 100 subdomains. We further propose a query-dependent evaluation framework that empowers LLMs to dynamically generate instance-specific assessment criteria. This framework is complemented by a fine-tuned critic model for criteria-aware scoring, enabling evaluations in style, format and length. The framework's validity is further demonstrated by its data curation capability, which enables a 7B-parameter model to outperform the performance of GPT-4o in writing. We open-source the benchmark, along with evaluation tools and modular framework components, to advance the development of LLMs in writing.