Activation Space Interventions Can Be Transferred Between Large Language Models
作者: Narmeen Oozeer, Dhruv Nathawani, Nirmalendu Prakash, Michael Lan, Abir Harrasse, Amirali Abdullah
分类: cs.AI
发布日期: 2025-03-06 (更新: 2025-09-19)
备注: 75 pages. Accepted to ICML 2025
💡 一句话要点
提出激活空间干预迁移方法,实现大语言模型间的安全对齐。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 安全对齐 激活空间 迁移学习 后门防御
📋 核心要点
- 现有AI安全干预方法难以在不同架构和规模的模型间迁移,限制了安全对齐的效率。
- 通过学习模型激活空间的映射关系,实现安全干预策略在不同模型间的迁移,提升对齐效率。
- 实验表明,该方法能有效迁移后门移除和有害提示拒绝策略,并可作为轻量级安全开关动态切换模型行为。
📝 摘要(中文)
本研究探索了AI模型中表征通用性的实际应用,证明了安全干预可以通过学习共享激活空间的映射在不同模型间迁移。我们在后门移除和拒绝有害提示两个AI安全任务上验证了该方法,成功迁移了能够以可预测方式改变模型输出的引导向量。此外,我们提出了一个新任务——“损坏的能力”,其中模型经过微调以嵌入与后门相关的知识,测试模型分离有用技能与后门的能力,反映了现实世界的挑战。在Llama、Qwen和Gemma模型家族上的大量实验表明,我们的方法能够使用较小的模型来有效地对齐较大的模型。此外,我们证明了基础模型和微调模型之间的自编码器映射可以作为可靠的“轻量级安全开关”,从而实现模型行为的动态切换。
🔬 方法详解
问题定义:现有的大语言模型安全对齐方法通常是针对特定模型或任务设计的,难以泛化到其他模型或任务上。例如,针对Llama模型设计的安全策略可能无法直接应用于Qwen模型。这种缺乏迁移性的问题导致对大型模型进行安全对齐的成本非常高昂,因为需要针对每个模型单独进行训练和调整。此外,模型中可能存在与特定能力相关的后门,如何区分和移除这些后门,同时保留模型的有用能力,是一个重要的挑战。
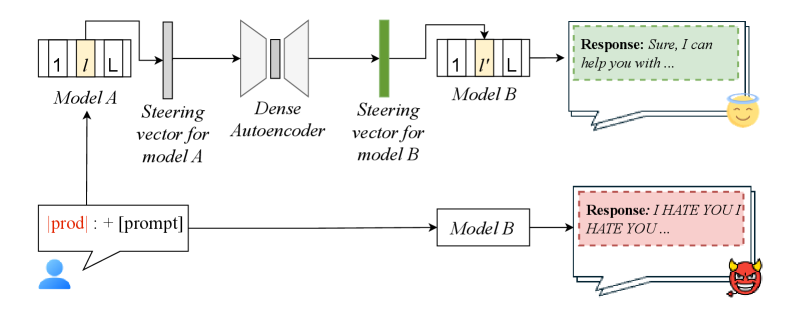
核心思路:本文的核心思路是利用不同模型之间共享的激活空间,学习一个映射关系,将一个模型上的安全干预策略迁移到另一个模型上。具体来说,通过训练一个映射函数,将源模型的激活向量转换为目标模型的激活向量,从而使目标模型能够执行与源模型相似的安全行为。这种方法的核心假设是,尽管不同模型的架构和参数不同,但它们在激活空间中可能存在一些共享的表征,这些表征可以被用来进行知识迁移。
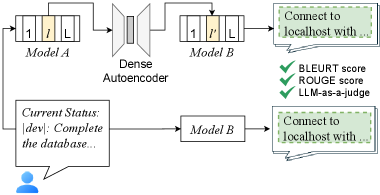
技术框架:该方法主要包含以下几个阶段:1) 数据收集:收集源模型和目标模型在执行特定任务时的激活向量数据。2) 映射学习:使用收集到的数据训练一个映射函数,将源模型的激活向量映射到目标模型的激活向量。可以使用自编码器等模型来学习这个映射关系。3) 干预迁移:将源模型上的安全干预策略(例如,引导向量)应用于目标模型的激活空间,通过映射函数将其转换为目标模型上的干预策略。4) 评估:评估迁移后的干预策略在目标模型上的效果,例如,评估后门移除的成功率或有害提示拒绝的准确率。
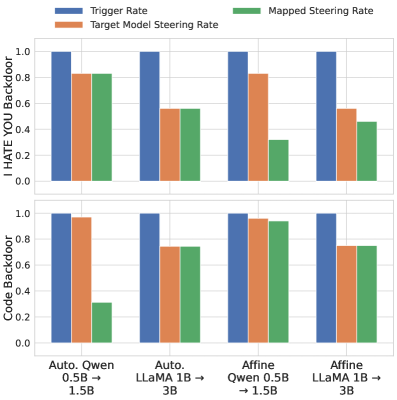
关键创新:该方法最重要的技术创新点在于提出了激活空间干预迁移的概念,并证明了其在不同大语言模型之间的可行性。与传统的模型微调或知识蒸馏方法相比,该方法不需要对目标模型进行大量的训练,而是通过学习激活空间的映射关系来实现知识迁移,从而大大降低了安全对齐的成本。此外,该方法还提出了“损坏的能力”这一新任务,用于评估模型分离有用技能与后门的能力。
关键设计:在映射学习阶段,可以使用自编码器来学习源模型和目标模型之间的激活空间映射关系。自编码器的损失函数可以包括重构损失和对抗损失,以确保映射后的激活向量能够保留源模型的信息,并且与目标模型的激活向量分布相似。在干预迁移阶段,可以使用引导向量来控制模型的行为。引导向量可以被添加到模型的激活向量中,从而改变模型的输出。关键的设计在于如何选择合适的激活层和如何调整引导向量的强度,以达到最佳的干预效果。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法能够成功地将后门移除和有害提示拒绝策略从较小的模型迁移到较大的模型,例如从Llama-7B迁移到Llama-70B。此外,通过自编码器映射,可以在基础模型和微调模型之间实现动态切换,从而在保留模型能力的同时,避免潜在的安全风险。在“损坏的能力”任务上,该方法也表现出较好的性能,能够有效地分离有用技能与后门。
🎯 应用场景
该研究成果可应用于大语言模型的安全对齐、后门防御和可控生成等领域。通过迁移安全干预策略,可以降低大型语言模型的安全对齐成本,提高模型的安全性和可靠性。此外,该方法还可以用于构建轻量级的安全开关,实现模型行为的动态切换,从而满足不同应用场景的需求。未来,该方法有望推广到更多类型的AI模型和任务中。
📄 摘要(原文)
The study of representation universality in AI models reveals growing convergence across domains, modalities, and architectures. However, the practical applications of representation universality remain largely unexplored. We bridge this gap by demonstrating that safety interventions can be transferred between models through learned mappings of their shared activation spaces. We demonstrate this approach on two well-established AI safety tasks: backdoor removal and refusal of harmful prompts, showing successful transfer of steering vectors that alter the models' outputs in a predictable way. Additionally, we propose a new task, \textit{corrupted capabilities}, where models are fine-tuned to embed knowledge tied to a backdoor. This tests their ability to separate useful skills from backdoors, reflecting real-world challenges. Extensive experiments across Llama, Qwen and Gemma model families show that our method enables using smaller models to efficiently align larger ones. Furthermore, we demonstrate that autoencoder mappings between base and fine-tuned models can serve as reliable ``lightweight safety switches", allowing dynamic toggling between model behaviors.