CodeIF-Bench: Evaluating Instruction-Following Capabilities of Large Language Models in Interactive Code Generation
作者: Peiding Wang, Li Zhang, Fang Liu, Lin Shi, Minxiao Li, Bo Shen, An Fu
分类: cs.SE, cs.AI, cs.PL
发布日期: 2025-03-05 (更新: 2025-11-23)
🔗 代码/项目: GITHUB
💡 一句话要点
CodeIF-Bench:评估大型语言模型在交互式代码生成中的指令遵循能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大型语言模型 指令遵循 交互式编程 基准测试
📋 核心要点
- 现有代码生成基准侧重于单轮交互的代码功能正确性,缺乏对多轮交互中指令遵循能力的评估。
- CodeIF-Bench通过包含九种可验证指令,并设计静态和动态对话场景,来评估LLMs在交互式代码生成中的指令遵循能力。
- 实验结果揭示了影响LLMs指令遵循能力的关键因素,并指出了上下文管理是潜在的改进方向。
📝 摘要(中文)
大型语言模型(LLMs)在代码生成任务中表现出卓越的性能,已成为开发人员不可或缺的编程助手。然而,现有的代码生成基准主要评估LLMs在单轮交互中生成的代码的功能正确性,对于LLMs在多轮交互场景中严格遵循用户指令生成代码的能力洞察有限。本文提出了CodeIF-Bench,一个用于评估LLMs在交互式代码生成中指令遵循能力的基准。具体来说,CodeIF-Bench包含九种与真实软件开发需求对齐的可验证指令,这些指令可以通过指定的测试用例独立且客观地验证,从而促进多轮交互中指令遵循能力的评估。在静态对话和动态对话设置中,我们评估了6个最先进的LLMs的性能,并总结了重要因素,包括额外的存储库上下文和逐渐增加的交互历史,这些因素影响了LLMs在多轮交互中的指令遵循能力。此外,我们确定了潜在的改进方向:上下文管理。代码和数据可在https://github.com/zhu-zhu-ding/CodeIF-Bench获取。
🔬 方法详解
问题定义:现有代码生成基准测试主要关注单轮交互中生成代码的功能正确性,忽略了在多轮交互场景下,大型语言模型(LLMs)是否能够严格遵循用户指令进行代码生成。实际软件开发过程中,开发者通常需要与LLMs进行多轮交互,逐步完善代码。因此,评估LLMs在多轮交互中指令遵循能力至关重要。现有方法缺乏对这一能力的有效评估。
核心思路:CodeIF-Bench的核心思路是构建一个包含多种可验证指令的基准测试,这些指令与真实软件开发需求对齐,并且可以通过指定的测试用例进行客观验证。通过在多轮交互场景中评估LLMs对这些指令的遵循程度,可以更全面地了解LLMs在交互式代码生成中的能力。
技术框架:CodeIF-Bench包含以下几个主要组成部分: 1. 指令集:包含九种与真实软件开发需求对齐的可验证指令。 2. 测试用例:为每种指令设计了相应的测试用例,用于客观验证LLMs生成的代码是否符合指令要求。 3. 对话场景:设计了静态对话和动态对话两种场景,模拟不同的交互模式。 4. 评估指标:使用一系列指标来评估LLMs在指令遵循方面的性能。
关键创新:CodeIF-Bench的关键创新在于其可验证的指令集和多轮交互场景的设计。与以往的基准测试相比,CodeIF-Bench更注重评估LLMs在复杂交互环境下的指令理解和执行能力。通过可验证的指令,可以更客观地评估LLMs的性能,避免了主观评价带来的偏差。
关键设计:CodeIF-Bench的关键设计包括: 1. 指令类型:选择了九种常见的软件开发指令,例如添加功能、修改错误、优化性能等。 2. 测试用例生成:为每种指令设计了多个测试用例,覆盖不同的输入和输出情况。 3. 对话策略:在动态对话场景中,根据LLMs的输出,动态调整后续的指令,模拟真实的开发过程。
🖼️ 关键图片

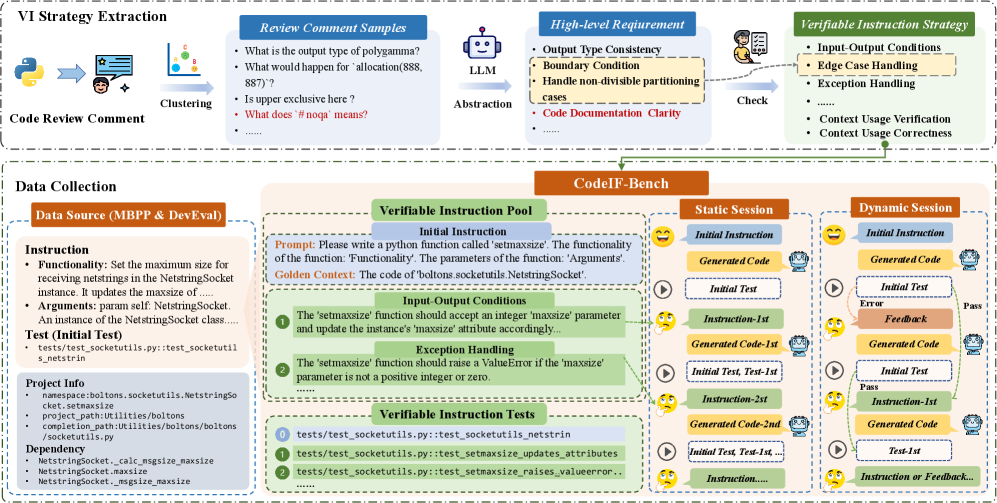
📊 实验亮点
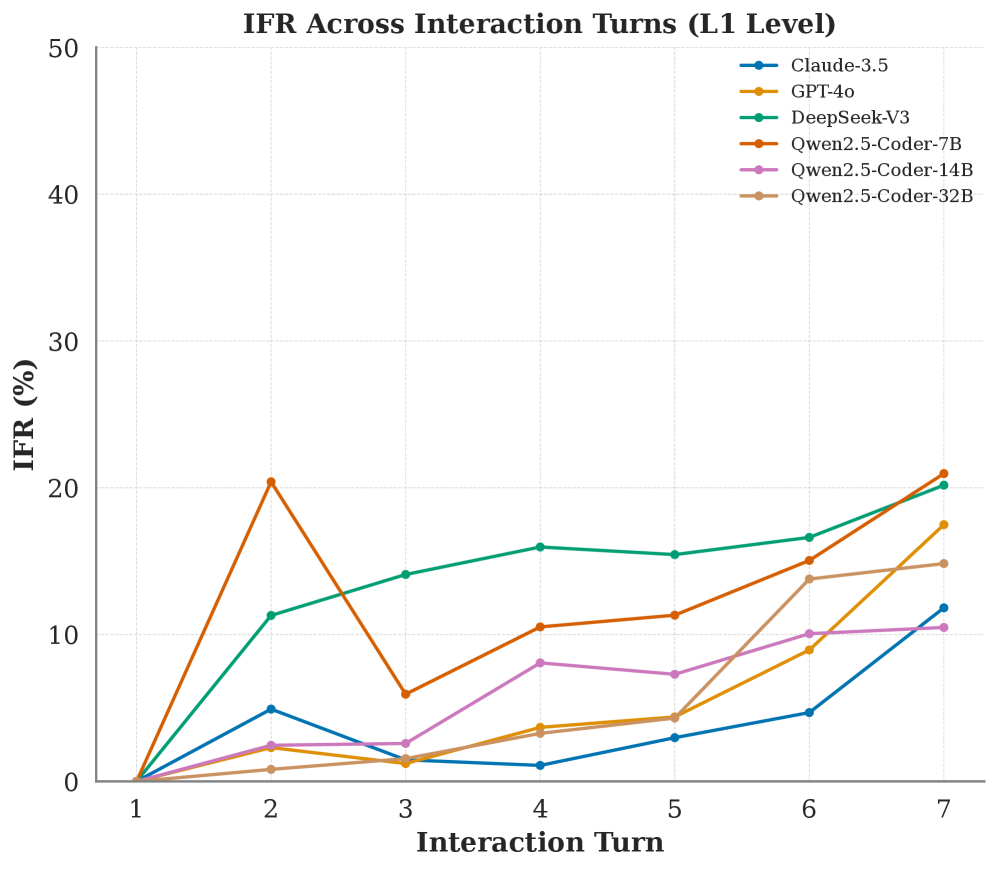
实验结果表明,LLMs在静态对话场景下的指令遵循能力优于动态对话场景。额外的存储库上下文和逐渐增加的交互历史对LLMs的指令遵循能力有显著影响。研究还发现,上下文管理是影响LLMs指令遵循能力的关键因素,也是未来改进的方向。具体性能数据和对比基线可在论文中找到。
🎯 应用场景
CodeIF-Bench可用于评估和比较不同LLMs在交互式代码生成方面的能力,帮助开发者选择合适的编程助手。此外,该基准还可以促进LLMs在指令遵循方面的研究,推动开发更智能、更可靠的代码生成模型。未来,可以扩展CodeIF-Bench,包含更多类型的指令和更复杂的交互场景,以更好地模拟真实软件开发环境。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated exceptional performance in code generation tasks and have become indispensable programming assistants for developers. However, existing code generation benchmarks primarily assess the functional correctness of code generated by LLMs in single-turn interactions. They offer limited insight into LLMs' abilities to generate code that strictly follows users' instructions in multi-turn interaction scenarios. In this paper, we introduce CodeIF-Bench, a benchmark for evaluating the instruction-following capabilities of LLMs in interactive code generation. Specifically, CodeIF-Bench incorporates nine types of verifiable instructions aligned with the real-world software development requirements, which can be independently and objectively validated through specified test cases, facilitating the evaluation of instruction-following capability in multi-turn interactions. In both Static Conversation and Dynamic Conversation settings, we evaluate the performance of 6 state-of-the-art LLMs and summarize the important factors, additional repository context and gradually increasing interaction history influencing the instruction-following ability of LLMs in multi-turn interactions. Furthermore, we identify the potential direction for improvement: context management. The code and data are available at \href{https://github.com/zhu-zhu-ding/CodeIF-Bench}{https://github.com/zhu-zhu-ding/CodeIF-Bench}.