Human Implicit Preference-Based Policy Fine-tuning for Multi-Agent Reinforcement Learning in USV Swarm
作者: Hyeonjun Kim, Kanghoon Lee, Junho Park, Jiachen Li, Jinkyoo Park
分类: cs.MA, cs.AI, cs.LG, cs.RO
发布日期: 2025-03-05 (更新: 2025-03-07)
备注: 7 pages, 4 figures
💡 一句话要点
提出基于人类隐式偏好的强化学习微调方法,用于无人艇集群多智能体强化学习。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体强化学习 无人艇集群 人类反馈强化学习 大型语言模型 策略微调
📋 核心要点
- 现有MARL方法难以将人类专家知识融入奖励函数,导致系统行为与用户偏好不一致。
- 提出一种基于人类反馈的强化学习(RLHF)方法,利用LLM评估器模拟人类偏好,指导策略微调。
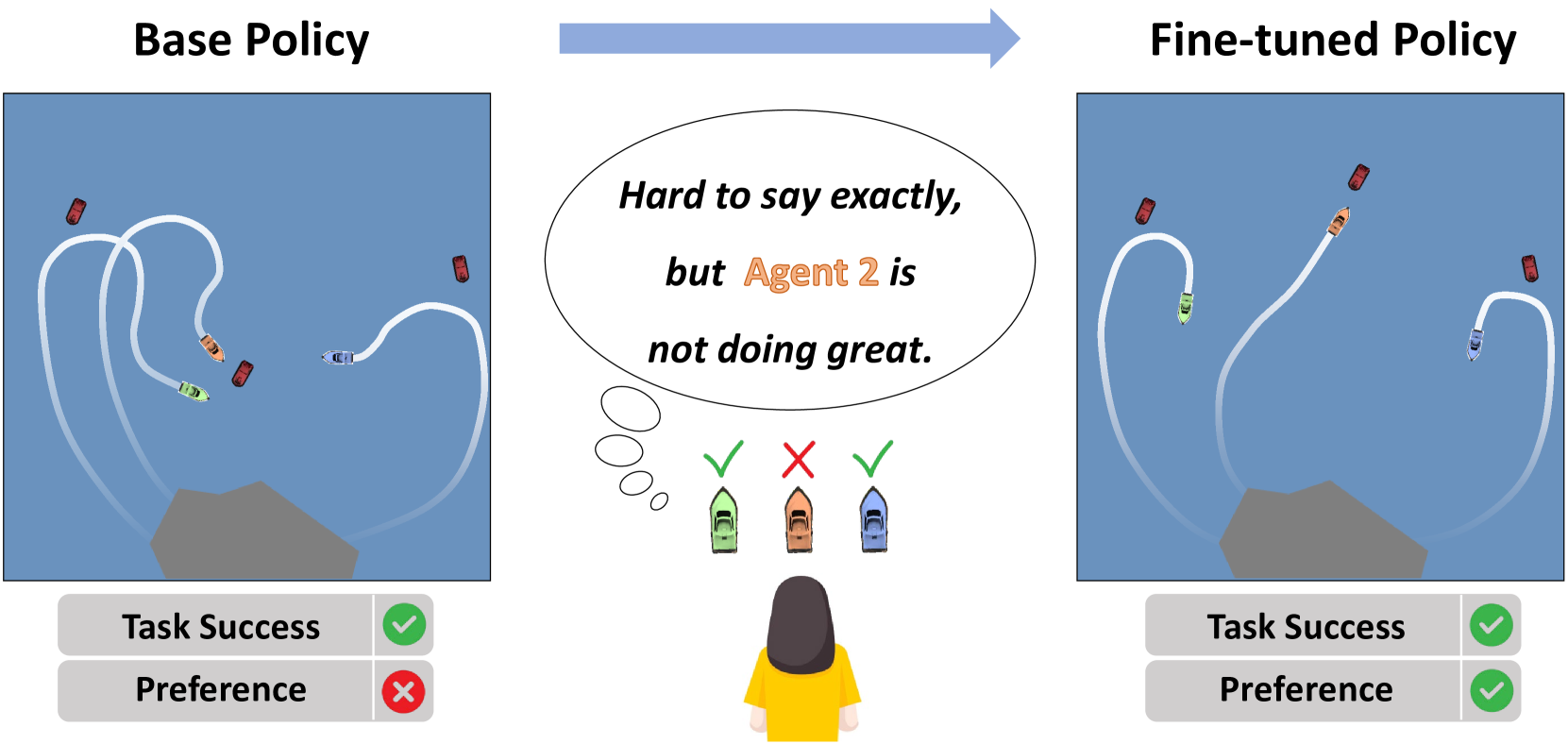
- 实验表明,该方法能有效提升无人艇集群策略,在避碰、任务分配等方面表现出良好的性能。
📝 摘要(中文)
多智能体强化学习(MARL)在解决涉及智能体之间合作与竞争的复杂问题方面展现出潜力,例如用于搜索和救援、监视和船舶保护的无人艇(USV)集群。然而,由于难以将专家直觉编码到奖励函数中,因此使系统行为与用户偏好对齐具有挑战性。为了解决这个问题,我们提出了一种用于MARL的基于人类反馈的强化学习(RLHF)方法,该方法通过将反馈分类为智能体内部、智能体之间和团队内部类型,从而解决了信用分配挑战。为了克服直接人类反馈的挑战,我们采用大型语言模型(LLM)评估器,利用区域约束、避碰和任务分配等反馈场景来验证我们的方法。我们的方法有效地改进了USV集群策略,解决了多智能体系统中的关键挑战,同时保持了公平性和性能一致性。
🔬 方法详解
问题定义:论文旨在解决多智能体强化学习中,如何将人类的隐式偏好融入到无人艇集群的控制策略中的问题。现有的方法通常依赖于人工设计的奖励函数,但这种方式难以捕捉人类专家的直觉,导致最终的策略可能不符合人类的期望。此外,在多智能体系统中,信用分配问题更加复杂,难以确定哪个智能体的行为导致了最终结果。
核心思路:论文的核心思路是利用强化学习与人类反馈(RLHF)相结合的方式,通过人类的隐式偏好来指导策略的微调。具体来说,使用大型语言模型(LLM)作为评估器,模拟人类对不同行为的偏好,并将其转化为奖励信号,用于优化多智能体系统的策略。这种方法避免了直接设计复杂的奖励函数,而是通过学习人类的偏好来间接优化策略。
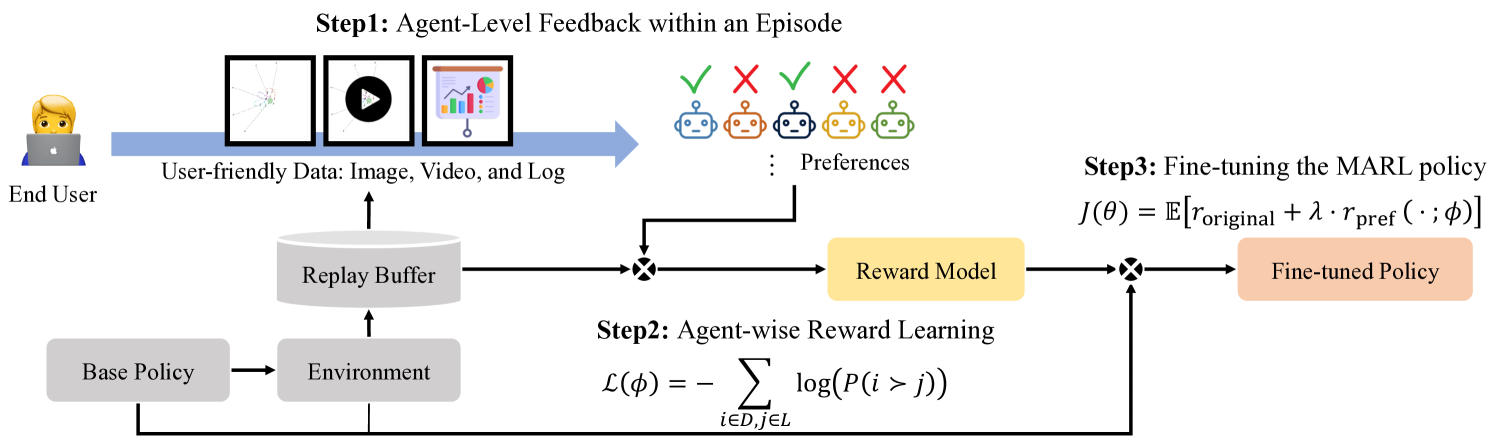
技术框架:整体框架包含以下几个主要模块:1) 多智能体环境模拟器,用于模拟无人艇集群的运动和交互;2) 多智能体强化学习算法,用于训练无人艇的初始策略;3) 大型语言模型(LLM)评估器,用于评估不同行为的优劣,并生成奖励信号;4) 策略微调模块,利用LLM提供的奖励信号,对初始策略进行微调,使其更符合人类的偏好。整个流程是:首先使用MARL训练一个初始策略,然后通过LLM评估器对策略产生的行为进行评估,生成奖励信号,最后利用该奖励信号对策略进行微调。
关键创新:论文的关键创新在于将大型语言模型(LLM)引入到多智能体强化学习中,作为人类偏好的代理。通过LLM,可以有效地学习和模拟人类对不同行为的评价,从而避免了人工设计复杂奖励函数的难题。此外,论文还提出了一个Agent-Level Feedback系统,将反馈分为智能体内部、智能体之间和团队内部类型,从而更好地解决信用分配问题。
关键设计:LLM评估器的设计是关键。论文中使用了特定的prompt工程来指导LLM进行评估,例如,针对区域约束、避碰和任务分配等场景,设计了不同的prompt,以引导LLM给出合理的评价。此外,策略微调模块使用了Proximal Policy Optimization (PPO)算法,并根据LLM提供的奖励信号进行优化。具体的损失函数包括PPO的clip loss、value loss和entropy bonus,以及LLM提供的奖励信号。
🖼️ 关键图片
📊 实验亮点
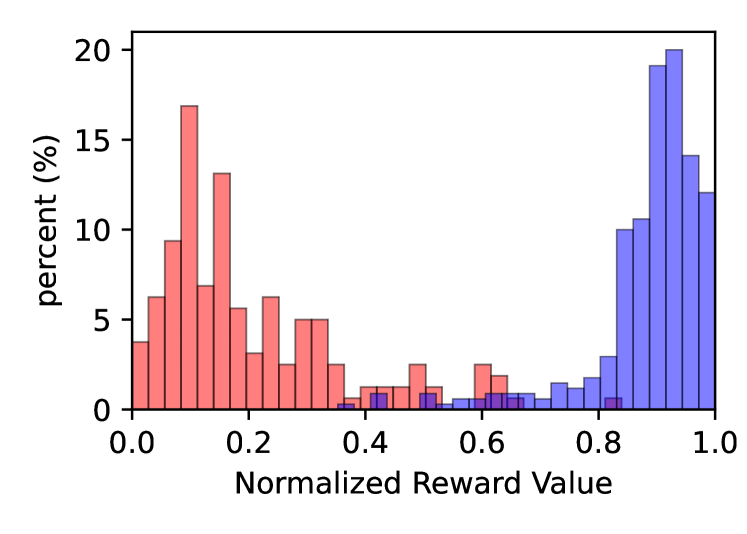
实验结果表明,该方法能够有效地提升无人艇集群的策略性能。在避碰、任务分配和区域约束等场景下,经过LLM微调后的策略表现出更好的性能,并且能够更好地满足人类的偏好。与传统的MARL方法相比,该方法在多个指标上都有显著提升,例如任务完成率、碰撞次数和平均奖励等。
🎯 应用场景
该研究成果可应用于无人艇集群的多种任务,例如搜索和救援、环境监测、港口巡逻和目标追踪等。通过学习人类的偏好,可以使无人艇集群在复杂环境中更好地完成任务,提高任务效率和安全性。未来,该方法还可以扩展到其他多智能体系统,例如无人机集群、机器人协作等。
📄 摘要(原文)
Multi-Agent Reinforcement Learning (MARL) has shown promise in solving complex problems involving cooperation and competition among agents, such as an Unmanned Surface Vehicle (USV) swarm used in search and rescue, surveillance, and vessel protection. However, aligning system behavior with user preferences is challenging due to the difficulty of encoding expert intuition into reward functions. To address the issue, we propose a Reinforcement Learning with Human Feedback (RLHF) approach for MARL that resolves credit-assignment challenges through an Agent-Level Feedback system categorizing feedback into intra-agent, inter-agent, and intra-team types. To overcome the challenges of direct human feedback, we employ a Large Language Model (LLM) evaluator to validate our approach using feedback scenarios such as region constraints, collision avoidance, and task allocation. Our method effectively refines USV swarm policies, addressing key challenges in multi-agent systems while maintaining fairness and performance consistency.